1. 引言
分类(Classification)是一种监督学习任务,其目标是为输入数据分配类别标签。在本文中,我们将深入了解一种快速且简单的分类方法:朴素贝叶斯分类器(Naive Bayes Classifier)。
朴素贝叶斯分类器尤其擅长文本分类任务,例如垃圾邮件过滤、欺诈检测等。事实上,从上世纪90年代起,垃圾邮件过滤的基线模型就基于朴素贝叶斯算法。另一个例子是判断一段未知语言的句子是否与动物相关,也可以用朴素贝叶斯分类器来实现。
本文将从理论出发,解释朴素贝叶斯分类器的工作原理,并探讨如何提升其分类性能。
2. 朴素贝叶斯分类器原理
朴素贝叶斯分类器以离散变量为输入,输出每个类别标签的概率得分。最终预测的类别是得分最高的那个类别。
它基于贝叶斯定理计算每个类别的后验概率:
$$ P(C|A) = \frac{P(A|C) P(C)}{P(A)} $$
其中:
- $ C $:类别标签
- $ A $:观测值(由多个特征组成)
对于一个观测值 $ A = {a_1, a_2, ..., a_m} $,我们计算每个类别的概率:
$$ P(C_i |A) = \frac{P(a_1,a_2,...,a_m|C_i) P(C_i)}{P(a_1,a_2,...,a_m)} $$
由于朴素贝叶斯假设所有特征之间相互独立,我们可以将联合概率拆解为乘积形式:
$$ P(a_1,a_2,...,a_m|C_i) = \prod_{j=1}^{m} P(a_j|C_i) $$
又由于分母对所有类别是常数,因此可以忽略,最终只需比较:
$$ P(C_i |A) \propto \Big ( \prod_{j=1}^{m}P(a_j|C_i) \Big ) P(C_i) $$
最终选择概率最大的类别作为预测结果。
⚠️ 该方法基于两个重要假设:
- 特征之间相互独立(这也是“朴素”一词的由来)
- 所有特征对分类结果的影响是等价的
这两个假设在现实中往往不成立,但朴素贝叶斯依然在很多任务中表现良好。
下图展示了朴素贝叶斯分类器的计算流程:
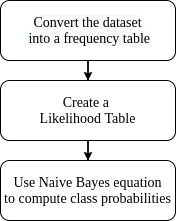
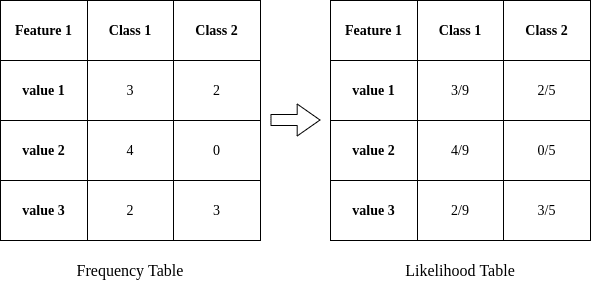
训练阶段通常使用频率表和似然表来统计每个特征在不同类别下的分布:
3. 提升朴素贝叶斯分类性能的方法
朴素贝叶斯是一个简单但高效的分类器。它的性能评估可以通过留出法(hold-out)或交叉验证(cross-validation)来完成。我们也可以使用合适的评估指标(如准确率、F1值等)来衡量其表现。
以下是一些可以提升朴素贝叶斯分类器性能的实用方法:
✅ 有效方法
| 方法 | 说明 |
|---|---|
| 去除相关特征 | 保留独立特征,避免重复计算导致偏差 |
| 使用对数概率 | 避免浮点数下溢问题 |
| 消除零频率问题 | 使用拉普拉斯平滑(Laplace Smoothing)处理未出现的特征 |
| 处理连续变量 | 离散化或使用高斯分布建模 |
| 处理文本数据 | 去除停用词、词干提取、词向量化等 |
| 重新训练模型 | 随着新数据积累更新模型 |
| 并行化概率计算 | 利用特征独立性进行并行加速 |
| 小数据集适用性 | 适合数据量小、不易过拟合 |
| 作为生成模型使用 | 可用于生成符合分布的新数据 |
❌ 无效方法
| 方法 | 原因 |
|---|---|
| 超参数调优 | 朴素贝叶斯参数极少,调参空间有限 |
| 缺失值处理 | 朴素贝叶斯天然对缺失值不敏感 |
| 维度约简 | 特征独立性假设已简化模型复杂度 |
| 提前停止 | 无迭代训练过程 |
| 集成方法 | 朴素贝叶斯本身方差低,集成效果有限 |
3.1 去除相关特征
朴素贝叶斯假设特征之间相互独立。如果特征之间存在高度相关性,模型会重复计算其影响,导致预测偏差。
✅ 解决方法:
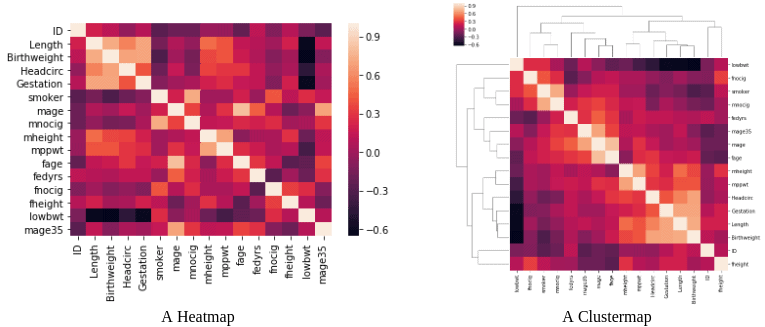
- 使用相关性矩阵检测相关性高的特征对
- 利用Seaborn库可视化相关性矩阵,辅助判断
import seaborn as sns
# 计算相关性矩阵
correlations = df.corr()
# 绘制热力图
sns.heatmap(correlations, xticklabels=correlations.columns, yticklabels=correlations.columns, annot=True)
# 绘制聚类图
sns.clustermap(correlations, xticklabels=correlations.columns, yticklabels=correlations.columns, annot=True)
下图展示了相关性热力图和聚类图的示例:
3.2 使用对数概率
朴素贝叶斯中,多个小概率相乘容易导致浮点数下溢(underflow),即结果接近于0,无法准确表示。
✅ 解决方法:
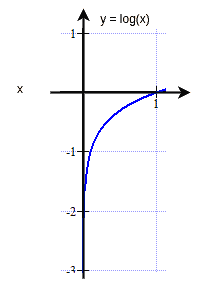
将概率值取对数,将乘法转换为加法,从而避免下溢问题。
$$ \log \big ( P(C_i |A) \big ) \propto \Big ( \sum_{j=1}^{m} \log \big ( P(a_j|C_i) \big ) \Big ) + \log \big ( P(C_i) \big ) $$
⚠️ 注意:取对数不会改变概率大小顺序,因此不影响最终分类结果。
下图展示了对数概率的映射关系:
3.3 消除零频率问题
如果某个特征在训练集中未出现,在测试集中出现时,其概率为0,导致整个乘积也为0,模型无法做出正确判断。
✅ 解决方法:
使用拉普拉斯平滑(Laplace Smoothing),在分子和分母中各加一个小的平滑项(通常为1):
$$ P(C|A) = \frac{P(A|C) P(C) + 1}{P(A) + 1} $$
这样即使某个特征在训练集中未出现,也会被赋予一个极小的非零概率。
3.4 处理连续变量
朴素贝叶斯通常处理离散特征,对于连续变量需要特殊处理。
✅ 解决方法:
- 离散化(Discretization):将连续值划分为区间,作为离散类别处理
- 高斯分布建模:假设特征服从正态分布,使用均值和标准差计算概率
- 非参数方法:如核密度估计(KDE)适用于非正态分布的数据
3.5 处理文本数据
文本数据需要专门的预处理步骤,才能被朴素贝叶斯有效处理。
✅ 常用处理步骤:
- 去除停用词(stop words)
- 转换为小写
- 词干提取(stemming)或词形还原(lemmatization)
- 使用词向量(word2vec、TF-IDF等)表示文本
3.6 重新训练模型
朴素贝叶斯模型训练速度快,适合频繁更新模型。
✅ 适用场景:
- 数据集增大时
- 数据分布随时间变化
- 出现新类别或新特征
由于其计算效率高,重新训练成本低,适合动态环境下的持续优化。
3.7 并行化概率计算
朴素贝叶斯的特征独立性使其非常适合并行计算。
✅ 实现方式:
- 将每个特征的概率计算任务分配到不同线程或节点
- 利用多核CPU或分布式系统加速计算过程
3.8 小数据集适用性
朴素贝叶斯适合小数据集训练,因为其模型结构简单,不易过拟合。
✅ 优势:
- 模型参数少,训练所需数据少
- 不易出现过拟合现象
- 对特征之间的关系建模较少,适合数据稀疏场景
⚠️ 劣势:
- 高偏差(high bias),可能无法捕捉复杂模式
3.9 不建议使用集成方法
集成方法(如Bagging、Boosting)通常用于降低模型方差。
❌ 不适用于朴素贝叶斯的原因:
- 朴素贝叶斯本身方差较低
- 多个朴素贝叶斯模型组合效果提升有限
3.10 作为生成模型使用
朴素贝叶斯本质上是一个生成模型(Generative Model),可以用于生成符合训练数据分布的新样本。
✅ 应用场景:
- 合成数据生成
- 数据增强
- 类别样本模拟
4. 总结
朴素贝叶斯分类器是一种高效、简洁且实用的机器学习方法,尤其适合文本分类等任务。
本文从贝叶斯定理出发,解释了朴素贝叶斯分类器的基本原理,并探讨了多种提升其性能的实用技巧:
- 去除相关特征
- 使用对数概率
- 拉普拉斯平滑处理零频率问题
- 正确处理连续变量和文本数据
- 重新训练模型
- 并行化计算
同时我们也指出,一些常见的提升方法(如超参数调优、集成学习)并不适用于朴素贝叶斯。
尽管其假设条件(特征独立)在现实中不一定成立,但在许多实际应用中,朴素贝叶斯依然表现良好,值得在项目中尝试。