1. 引言
现代深度学习框架为我们提供了非常直观的接口来设置网络层、调整超参数以及评估模型性能。但要真正理解模型的运行机制,以及在讨论结果时更有底气,我们需要掌握一些基本概念。
本文将重点讲解 前向传播网络(Feedforward Neural Networks) 与 反向传播算法(Backpropagation) 的区别和各自作用。
2. 前向传播网络
前向传播网络是深度学习中最基础的模型结构,由人工神经元按层组织而成。其最大特点是 信号仅从输入层向输出层单向流动,不包含任何反馈或循环连接。
2.1 神经元的计算原理
每个神经元接收一组输入  ,通过加权求和加上偏置项,再经过激活函数处理,输出激活值
,通过加权求和加上偏置项,再经过激活函数处理,输出激活值  :
:
(1) 
其中:
 是偏置项(bias)
是偏置项(bias) 是权重(weights)
是权重(weights) 是激活函数,如 ReLU 或 Sigmoid
是激活函数,如 ReLU 或 Sigmoid
下图展示了一个神经元的结构:
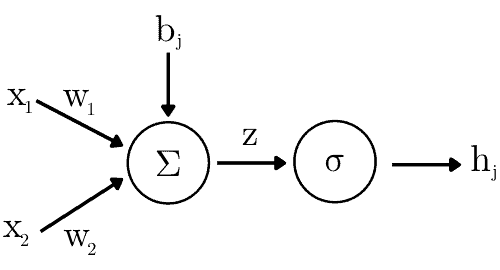
2.2 层与前向传播
神经网络由多个神经元层组成,输入层、隐藏层和输出层之间通过前向传播进行数据流动。例如:
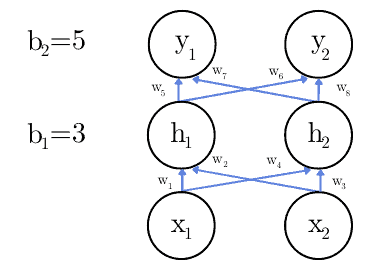
图中:
 和
和  是输入
是输入 和
和  是隐藏层输出
是隐藏层输出 和
和  是最终输出
是最终输出 和
和  是偏置项,会在训练阶段调整
是偏置项,会在训练阶段调整
前向传播网络的核心特征是 没有反向连接,所有信号只从前向后流动。
2.3 示例:图像分类任务
假设我们要构建一个简单的图像分类器,判断图像中是否为狗。为了简化问题,假设只用两个灰度像素值  和
和  进行判断(取值范围:[0, 255])。
进行判断(取值范围:[0, 255])。
网络结构如下:
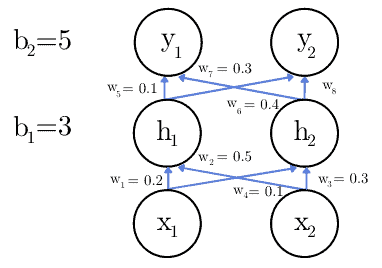
设定输入值为:


激活函数为恒等函数(identity function):
(2) 
因为使用的是恒等函数,所以:
(3) 
同理可得  、
、 和
和  。
。
3. 反向传播算法
在训练神经网络时,我们通过 反向传播(Backpropagation) 来计算损失函数对各个参数的梯度,从而更新权重和偏置,使模型输出更接近真实值。
3.1 损失函数(Cost Function)
假设我们有一个二分类任务,输出层有两个神经元:
- 表示“猫”的概率
- 表示“狗”的概率
对于一张真实为“猫”的图片,期望输出是:


如果模型输出为:


则误差为:
(4) 
整个训练集的损失函数  是所有样本误差的平均值:
是所有样本误差的平均值:
(5) 
3.2 偏导数计算
反向传播的核心是计算损失函数对每个参数的偏导数。以一个简单网络为例:
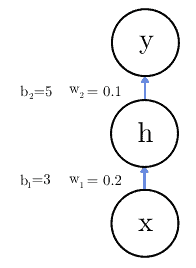
其中激活函数为恒等函数。要更新权重  ,我们需要计算:
,我们需要计算:
(6) 
3.3 示例:具体计算过程
以公式 (6) 为例,我们依次计算:
(7) 损失对输出的偏导数:
(7) 
(8) 输出对输入的偏导数(激活函数导数):
(8) 
(9) 输入对权重的偏导数:
(9) 
(10) 最终偏导数:
(10) 
3.4 训练中的反向传播流程
假设当前训练阶段有:

- 期望输出

- 当前输出

代入公式 (10):
(11) 
设学习率为  ,更新权重:
,更新权重:
(12) 
3.5 训练方式变体
除了对整个训练集进行反向传播外,还有以下常见训练方式:
- ✅ Mini-batch Gradient Descent:每次使用一小批样本更新参数
- ✅ **Stochastic Gradient Descent (SGD)**:每次使用一个样本更新参数
这些方法在计算效率和收敛性之间做了权衡。
3.6 通用偏导公式
对于任意一个连接第  层神经元
层神经元  与第
与第  层神经元
层神经元  的权重
的权重  ,其偏导公式为:
,其偏导公式为:
(15) 
同样可得偏置项的偏导公式:
(16) 
3.7 反向传播 ≠ 训练算法
⚠️ 注意:反向传播只是计算梯度的方法,不是训练算法本身。实际更新参数的是优化算法,如:
- ✅ Gradient Descent
- ✅ Stochastic Gradient Descent (SGD)
- ✅ Adam(Adaptive Moment Estimation)
此外,反向传播不仅适用于前向传播网络,也可以用于 RNN 等具有反馈结构的网络。
4. 总结
- ✅ 前向传播网络 是一种没有反馈连接的神经网络结构,数据从输入层流向输出层。
- ✅ 反向传播算法 是用于计算损失函数对模型参数梯度的数学方法,用于更新权重和偏置。
- ✅ 在模型推理阶段,数据仅向前流动;而在训练阶段,反向传播负责从输出反向更新参数。
理解这两者的区别,有助于我们更好地掌握神经网络的工作原理,也能在调试和优化模型时更有方向感。