1. 概述
本文探讨了在神经网络架构中引入偏差项(bias)的理论依据。
我们将首先了解一些支持偏差项的常见理由,然后探讨一些理论上成立但较少被提及的论点。
我们会从“偏差”这个词的常识意义出发,将其推广到神经网络中的偏差项。接着,我们将分析单层神经网络和深层神经网络的通用结构,证明如果存在偏差,它在每一层是唯一的一个标量或向量。这将引导我们从决策面和仿射空间的角度理解偏差的必要性。
文章最后,你将理解为什么要在神经网络中引入偏差项,并且更关键的是:你将知道没有偏差的神经网络在哪些情况下必然会产生预测误差。
2. 人类和测量中的偏差
2.1 偏差的常识意义
“偏差”这个词在日常语境中通常指系统性错误。例如,一个人对某个观点有偏见,意味着他无视反面证据坚持己见;一个游戏规则若对某些玩家有利,也可以说它是有偏差的。
这说明偏差是一种普遍存在的现象,不仅限于人类认知,也广泛存在于测量和预测系统中。
2.2 测量理论中的偏差
在测量理论中,偏差通常与“真实值”(true value)有关。真实值是对某个测量“理想状态”的假设 —— 即使用完美仪器测量所得的值。虽然现实中不存在完美测量,但这个概念仍然有指导意义。
如果我们发现某个测量工具系统性地偏离真实值,我们就可以通过校准来修正它。这个过程在神经网络中就相当于“学习” —— 通过不断调整参数来减少预测误差。
2.3 偏差与预测
在预测模型中,偏差可以理解为预测值与真实观测值之间的系统性差异。
例如,如果你总是低估学生的身高10厘米,这就是一个系统性偏差。只要你知道这个偏差,就可以在预测时加上这个固定值来修正结果。
| 我们的猜测 | 加上误差 | 真实值 |
|---|---|---|
| 165 | 175 | 175 |
| 159 | 169 | 169 |
| 171 | 181 | 181 |
| 167 | 177 | 177 |
我们可以用数学形式表示这个偏差:
$$ \hat{y} = f(x) + 10 $$
这与神经网络中偏差项的表达方式非常相似。
2.4 分类任务中的偏差
偏差不仅存在于数值预测中,也存在于分类任务中。例如,你可能倾向于高估某人的教育水平:
| 直觉预测 | 修正后 | 真实值 |
|---|---|---|
| 大学 | 学院 | 学院 |
| 学院 | 高中 | 高中 |
| 高中 | 初中 | 初中 |
这说明偏差不仅影响数值型输出,也会影响分类模型的预测结果。
2.5 偏差的本质总结
- 偏差是系统性错误
- 如果一个模型的预测总是偏离真实值一个固定量,那么这个量就是偏差
- 偏差可以是数值型的,也可以是分类型的
- 只要是系统性错误,就可以称为偏差,并且可以被修正
3. 神经网络中的偏差
3.1 神经网络与线性函数
单层神经网络可以表示为:
$$ Y = f(X, W) $$
其中 $ X $ 是输入向量,$ W $ 是权重矩阵,$ Y $ 是输出。
如果我们只使用线性变换 $ Y = WX $,那么这个网络只能拟合过原点的线性函数:
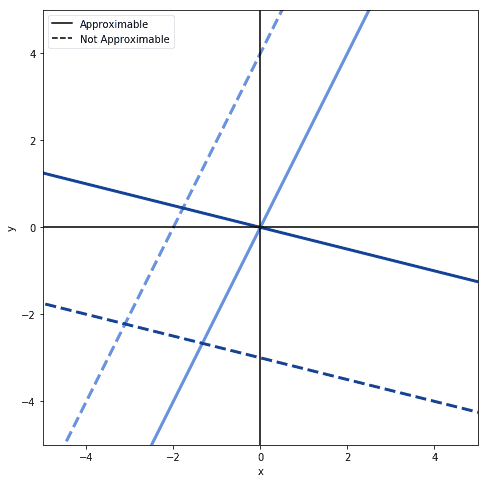
但如果加上偏差项:
$$ Y = WX + b $$
那么网络就可以拟合任意线性函数:
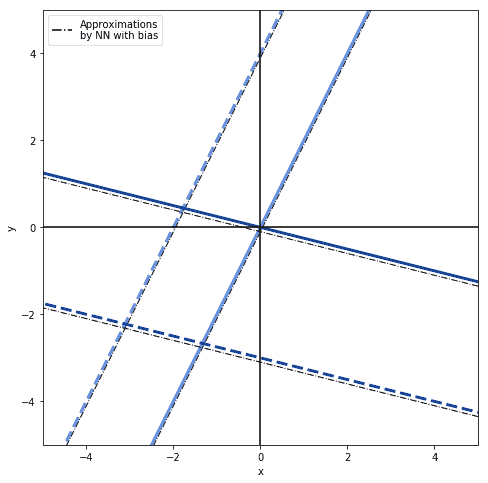
3.2 偏差项的引入
我们可以通过添加偏差项来纠正网络预测的系统性误差。例如:
$$ Y = f(X) + b $$
这里的 $ b $ 就是偏差项,表示网络预测值整体偏移的量。
3.3 每一层只有一个偏差
即使我们有多个输入特征,每个特征都有可能产生系统性误差,但这些误差可以合并为一个总偏差:
$$ Y = f(X) + b_1 + b_2 + \dots + b_n = f(X) + b $$
因此,每一层只需要一个偏差项,它是一个标量。
3.4 偏差向量的唯一性
在多层网络中,每层都有一个偏差项 $ b_k $,整个网络的偏差可以表示为一个向量:
$$ B = [b_1, b_2, \dots, b_n] $$
这个向量是唯一的,因为每一层的偏差都是唯一的。
如果输入标准化后均值为0,而网络没有偏差项,那么在网络输入为0时,输出也将为0,这可能导致预测误差。
3.5 激活函数中的偏差
有时,偏差项不是加在输出上,而是加在激活函数的输入上。例如,ReLU函数:
$$ y = \text{ReLU}(x) = \max(0, x) $$
如果输入总是小于0,ReLU会“死掉”,导致梯度为0,无法训练:
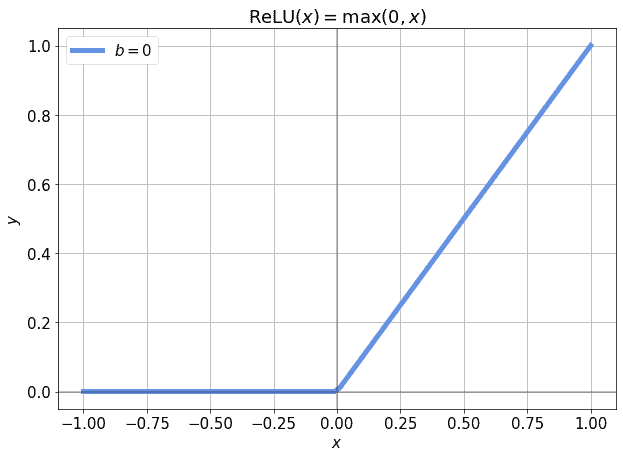
但如果我们加上一个偏差项:
$$ y = \text{ReLU}(x + b) $$
就可以将激活函数左移或右移,使得即使输入为0,也能激活神经元:
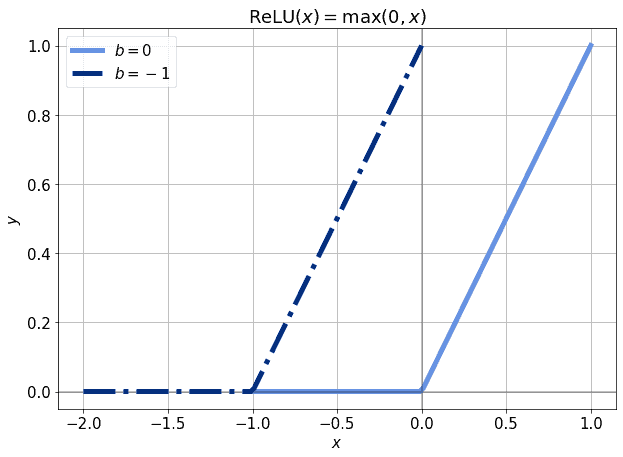
3.6 其他激活函数中的偏差
即使是更复杂的激活函数,如GeLU:
$$ y = \text{GELU}(x) $$
在输入标准化后也可能导致某些区域的输出接近0:
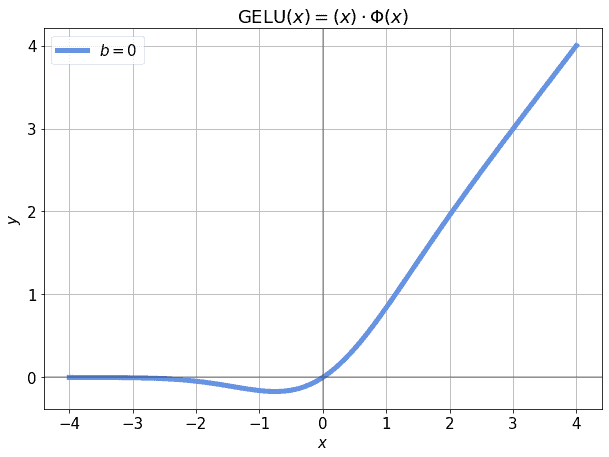
加上偏差后,可以使得这些区域的输出不再为0,从而避免梯度消失:
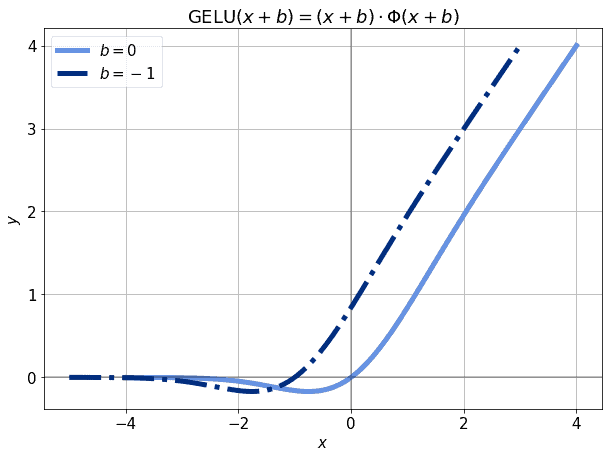
✅ 结论:无论使用哪种激活函数,加入偏差项都是一个好习惯,它可以避免模型在某些输入下“死掉”。
4. 引入偏差的理论依据
4.1 主要理由
神经网络中引入偏差项的主要理由包括:
- ✅ 预测中存在系统性误差
- ✅ 输入为0时输出不为0
- ✅ 决策面不是向量空间,而是仿射空间
4.2 数学解释:决策面与仿射空间
假设神经网络的输入输出空间构成一个向量空间 $ V $。如果目标函数是该空间中的一个子空间,并且激活函数是奇函数(如线性、tanh、双极性Sigmoid),那么可以不使用偏差项。
但如果目标函数是一个仿射超平面(affine hyperplane),而不是向量空间,那么必须引入偏差项,否则网络在输入接近0时会产生系统性误差。
例如,下面是一个仿射决策面:
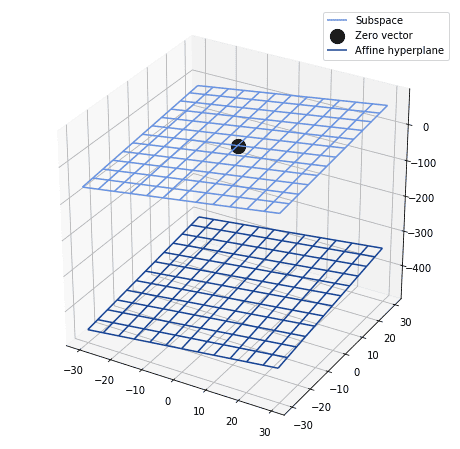
如果不引入偏差,所有靠近原点的预测都会偏离真实值。引入偏差后,可以对整个决策面进行平移,从而更准确地逼近目标函数。
5. 总结
本文从测量理论、预测误差和线性代数角度分析了神经网络中引入偏差项的必要性。
✅ 主要结论:
- 偏差是系统性误差,可以被建模和修正
- 每一层神经网络只需一个偏差项
- 偏差项可以防止模型在输入为0时输出错误
- 在仿射空间中,没有偏差项会导致模型无法准确逼近目标函数
❌ 踩坑提醒:如果你的输入做了标准化(如均值为0),并且没有引入偏差项,那么模型在输入接近0时很可能会表现很差。
⚠️ 建议:除非你明确知道目标函数是通过原点的向量空间,否则都应引入偏差项。它虽然增加了少量计算量,但能显著提升模型表现。