1. 概述
在本教程中,我们将学习如何确定神经网络中隐藏层的数量及其大小。
我们会从复杂度理论的角度切入,逐步分析神经网络架构的复杂度如何随着问题复杂度的提升而提升。随后,我们将区分基于理论的方法与启发式方法在确定隐藏层数量和大小时的应用场景。
最终,你将能够根据具体任务选择合适的神经网络结构。
2. 神经网络与维度
2.1. 问题与网络的复杂性
神经网络的复杂度应与所解决问题的复杂度相匹配。换句话说,问题越复杂,解决该问题所需的最小神经网络复杂度也越高。
我们可以用如下方式形式化这一观点:
设  表示问题 p 的复杂度,
表示问题 p 的复杂度, 表示解决该问题的神经网络 N 的复杂度,则:
表示解决该问题的神经网络 N 的复杂度,则:
$$ \forall{(p_1, p_2)}\ \forall{(N_1, N_2)}: C(p_1) < C(p_2) \to C(N_1) < C(N_2) $$
✅ 这意味着:如果我们能比较两个问题的复杂度,就可以对解决它们的神经网络复杂度进行排序。
这个观点源自复杂系统理论中一个更普遍的认知:环境越复杂,嵌入其中的认知系统也必须越复杂。
2.2. 维度灾难与复杂度
在机器学习中,一个常见的复杂度衡量标准是模型参数的维度  。因为非线性激活函数的反向传播计算成本随着参数维度的增加而迅速上升。
。因为非线性激活函数的反向传播计算成本随着参数维度的增加而迅速上升。
这就导致了所谓的“维度灾难”(Curse of Dimensionality)问题。一些架构(如卷积神经网络)通过利用输入特征之间的线性依赖性来缓解这个问题,而其他如回归神经网络则无法做到这一点。
⚠️ 因此,选择复杂度最小但又能解决问题的网络结构至关重要。
3. 神经网络与问题复杂度的关系
3.1. 理论上的空白
目前在深度神经网络领域存在一个重要的理论空白:我们还不清楚为什么神经网络能如此有效地解决大多数问题。本节将尝试从问题复杂度与网络结构之间的关系出发,为这一问题提供一些新的视角。
3.2. 退化问题与退化解
最简单的问题是“退化问题”,如  。这类问题只需一个将输入直接复制到输出的神经网络即可解决:
。这类问题只需一个将输入直接复制到输出的神经网络即可解决:

这种情况下不需要隐藏层。
3.3. 线性可分问题
更复杂的问题是线性可分问题,如线性回归或二分类问题。
以二分类为例,输出值可以是两个值之一,如  ,问题转化为寻找一个函数
,问题转化为寻找一个函数  ,满足:
,满足:
$$ y_1 \leq f(x, \beta) \wedge y_2 \geq f(x, \beta) $$
感知机可以解决这类问题:

✅ 对于线性可分问题,隐藏层数量应为 0,即只需输入层和输出层即可。
如果输入特征之间存在线性相关性,可以使用 PCA 等降维技术进行预处理。
3.4. 非线性可分问题
非线性可分问题无法用一个超平面来划分,如经典的 XOR 问题。解决这类问题至少需要一个隐藏层。
例如,XOR 问题可以用一个含 1 个隐藏层、2 个神经元的网络解决:

✅ 根据通用逼近定理(Universal Approximation Theorem),只要问题是一个在  上连续可微的函数,一个隐藏层就足以以任意精度逼近该函数。
上连续可微的函数,一个隐藏层就足以以任意精度逼近该函数。
所以,对于连续可微的问题,隐藏层数量应为 1,其大小则需通过启发式方法确定。
3.5. 任意边界问题
当问题的决策边界是任意形状时(如多个不连续区域),函数不再连续可微。
例如:
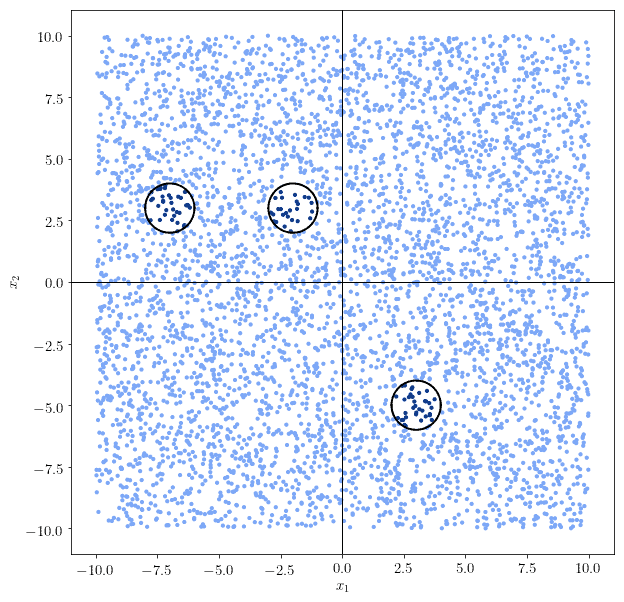
✅ 此时,需要增加到至少 2 个隐藏层,以学习这些不连续区域的组合。
可以这样理解:每个神经元学习一个连续区域,输出层的权重矩阵将它们组合成整体边界。
这类网络被称为深度神经网络(Deep Neural Networks),区别于仅含一个隐藏层的“浅层网络”。
3.6. 抽象问题
更高层次的问题要求网络学习层之间的模式,而非仅输入数据的模式。
典型例子是卷积神经网络(CNN),它能从图像像素中抽象出“线”、“圆”等概念:

✅ 这类问题需要超过 2 个隐藏层,以实现对特征的抽象和组合。

3.7. 更高复杂度的问题
理论上,问题复杂度可以无限增长,因此神经网络的最小复杂度也可以无限增长。
但在实践中,大多数实际问题并不需要特别深的网络。
例如:
- 图像识别(如 AlexNet)使用 8 层即可解决
- 文本生成(如 GPT-3)需要 96 层
✅ 所以,如果你的模型层数远超这些值,可能说明你设计的网络结构存在冗余或错误。
4. 启发式方法
当理论方法不足以指导我们时,可以使用以下几种启发式策略来选择隐藏层数量和大小:
4.1. 逐步构建更复杂的系统
✅ 从最简单的模型开始尝试,只有在简单模型无法解决问题时,才逐步增加复杂度。
例如:
- 先尝试线性模型
- 若失败,再尝试 1~2 个隐藏层
- 若仍失败,再考虑增加层数
⚠️ 训练神经网络是计算密集型任务,应尽量避免不必要的复杂度。
4.2. 优先增加层的大小而非层数
✅ 当现有网络无法学习决策函数时,优先增加隐藏层的节点数,而非增加层数。
因为:
- 增加节点数比增加层数更节省计算资源
- 更宽的层可能已经足够捕捉复杂模式
例如,可以尝试使用比输入层小但比输出层大的隐藏层。
4.3. 更好地处理数据
✅ 训练失败通常不是因为层数不够,而是因为数据预处理不足。
你可以尝试:
- 使用 PCA 等方法降维
- 对输入进行标准化或归一化
- 添加 Dropout 层防止过拟合
⚠️ 每次训练失败都应首先考虑是否数据处理不到位,而不是直接增加网络深度。
5. 总结
本文我们学习了如何根据问题复杂度选择神经网络隐藏层的数量和大小:
✅ 核心观点:
- 问题复杂度决定网络复杂度
- 退化问题 → 无隐藏层
- 线性可分问题 → 无隐藏层
- 非线性可分问题 → 1 个隐藏层
- 任意边界问题 → 2 个隐藏层
- 抽象问题 → 超过 2 个隐藏层
✅ 启发式建议:
- 从简单模型开始逐步增加复杂度
- 优先增加层的大小而非层数
- 训练失败时应优先优化数据预处理
最终建议:优先使用理论依据选择网络结构,理论不足时再用启发式方法补充。