1. 概述
在本篇文章中,我们将深入探讨权重衰减(Weight Decay)损失。首先我们会介绍机器学习中常见的问题——过拟合,以及如何通过正则化来缓解这一问题。随后,我们将正式定义权重衰减损失,并通过一个简单的例子来说明其作用机制。
2. 过拟合问题
在训练机器学习模型时,如何避免过拟合(Overfitting)是一个非常关键的问题。为了更好地理解过拟合,我们先了解两个基础概念:偏差(Bias)和方差(Variance)。
2.1 偏差
偏差是指模型预测值的平均值与真实值之间的差异。✅偏差越大,说明模型对训练数据的拟合能力越弱,学习到的函数越简单。这会导致模型在训练集上表现不佳。
2.2 方差
方差衡量的是模型对同一输入样本的预测波动程度。✅方差越高,说明模型对训练数据的依赖性越强,学习到了非常复杂的函数形式。虽然这在训练集上表现很好,但会导致泛化能力下降,即在测试数据上表现差。
2.3 偏差-方差权衡
这就是我们常说的偏差-方差权衡(Bias-Variance Trade-off):
- 如果模型参数太多,它会学习一个非常复杂的函数,导致高方差、低偏差,出现过拟合;
- 如果模型参数太少,它学习的函数过于简单,导致高偏差、低方差,出现欠拟合(Underfitting);
理想情况下,我们要在这两者之间找到一个平衡点,让模型既能捕捉到数据的规律,又不至于过度拟合训练数据。
下图形象地展示了过拟合的表现形式:
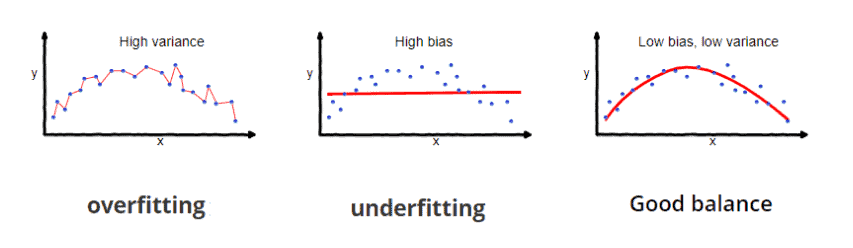
3. 正则化
正则化(Regularization)是缓解过拟合最常用的方法之一。其核心思想是:通过限制模型的学习能力,让它学习一个更简单的函数,从而提升泛化性能。
模型函数的复杂度与其可学习参数的大小密切相关。✅当模型学习到的参数值很大时,往往意味着它学习到了更复杂的函数结构。因此,我们可以通过控制参数的大小来控制模型的复杂度。
正则化实现方式是在损失函数中添加一个额外项,用来惩罚参数值过大的情况。这样可以让模型在优化过程中倾向于选择更小的参数值,从而学到一个更简单的函数。
4. 权重衰减损失
正则化有多种实现方式,其中权重衰减(Weight Decay)是最常见的一种,它对应的是L2正则化(L2 Regularization)。
✅权重衰减的核心思想是:在损失函数中加入网络权重的 L2 范数(即平方和),从而限制权重的大小。
假设原始损失函数为 $ L $,则加入权重衰减后的损失函数为:
$$ L_{new} = L + \frac{\lambda}{2m} \sum_{j=1}^n \theta_j^2 $$
其中:
- $ \theta_j $:模型参数;
- $ m $:训练样本数量;
- $ \lambda $:正则化系数,控制正则项对总损失的影响程度。
✅增大 $ \lambda $ 的值可以进一步限制权重的大小,从而降低模型的复杂度和方差,有助于防止过拟合。
5. 示例:逻辑回归中的权重衰减
为了更直观地理解权重衰减的作用,我们来看一个简单的例子:逻辑回归。
逻辑回归的原始损失函数为:
$$ L = y \log(\hat{y}) + (1-y)\log(1 - \hat{y}) $$
其中:
- $ y $:真实标签;
- $ \hat{y} $:模型预测输出。
如果我们用线性函数 $ \hat{y} = wx + b $ 来表示预测值,那么损失函数可以改写为:
$$ L = y \log(wx + b) + (1-y)\log(1 - wx - b) $$
为了防止过拟合,我们在损失函数中加入权重衰减项:
$$ L_{new} = y \log(wx + b) + (1-y)\log(1 - wx - b) + \frac{\lambda}{2} |w|_2^2 $$
✅通过这种方式,我们不仅优化了模型的预测误差,还同时控制了模型参数的大小,从而提升了模型的泛化能力。
6. 总结
本文我们介绍了权重衰减损失的基本原理及其在防止模型过拟合中的作用:
- 通过分析偏差-方差权衡,我们理解了过拟合的本质;
- 正则化是一种通用的防止过拟合的策略;
- 权重衰减是 L2 正则化的一种实现方式,通过限制模型参数的大小来简化模型;
- 在逻辑回归中,我们通过添加权重衰减项展示了其具体实现方式。
✅权重衰减是深度学习中非常实用的一种正则化技巧,尤其在模型参数较多时,其作用尤为显著。合理使用权重衰减,可以在不过度牺牲模型表达能力的前提下,有效提升模型的泛化性能。