1. 引言
在本文中,我们将介绍三种计算二叉搜索树(BST)中某个节点“排名”(Rank)的方法。
2. 树中节点的排名
一个节点 x 的排名,是指树中值小于或等于 x 的节点数量。 只要数据类型之间存在顺序关系(即可以用 ≤ 比较),就可以定义排名。例如,下图中节点值为 27 的排名是 7:
![]()
也就是说,我们给定一个值 x 和树的根节点,目标是找出 x 在该树中的排名。
需要注意的是,x 不一定存在于树中。如果存在,也可能重复出现。我们介绍的方法将涵盖所有这些情况。
3. 暴力法计算排名
最直观的做法是递归统计左子树和右子树中所有小于等于 x 的节点数。如果当前节点值小于等于 x,则计数加 1;否则不加。最终结果就是该节点左子树和右子树的排名之和。
递推公式如下:
$$ rank(x, root) = \begin{cases} 0, & \text{空树} \ 1 + rank(x, root.left) + rank(x, root.right), & root.value \leq x \ rank(x, root.left) + rank(x, root.right), & root.value > x \end{cases} $$
3.1. 伪代码
algorithm BruteForceRank(node, x):
if node == null:
return 0
leftRank <- BruteForceRank(node.left, x)
rightRank <- BruteForceRank(node.right, x)
if node.value <= x:
return 1 + leftRank + rightRank
else:
return leftRank + rightRank
3.2. 示例
以下图为例,暴力法计算 27 的排名时会遍历整棵树:
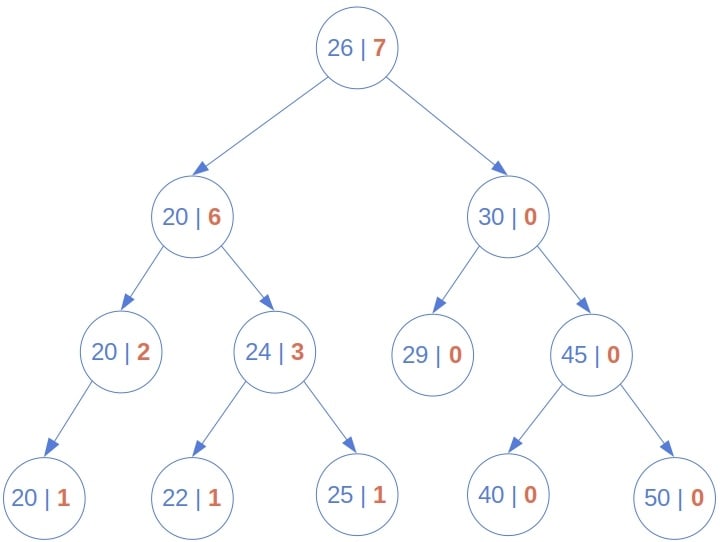
它会一直递归到底层节点,再逐层返回结果。
3.3. 时间复杂度
由于每次都要遍历整个树,时间复杂度为 **Θ(n)**,其中 n 是节点总数。这个方法没有利用 BST 的有序性,效率较低。
4. 利用 BST 有序性优化排名计算
由于 BST 的特性,我们可以根据当前节点值与 x 的比较决定是否需要遍历右子树:
- 如果 node.value ≤ x:需要遍历左右子树。
- 如果 node.value > x:可以直接跳过右子树。
4.1. 伪代码
algorithm OrderBasedCalculationOfRank(node, x):
if node == null:
return 0
if node.value <= x:
return 1 + Rank(node.left, x) + Rank(node.right, x)
else:
return Rank(node.left, x)
4.2. 示例
以下图为例,该方法计算 27 的排名时只访问小于等于它的节点:
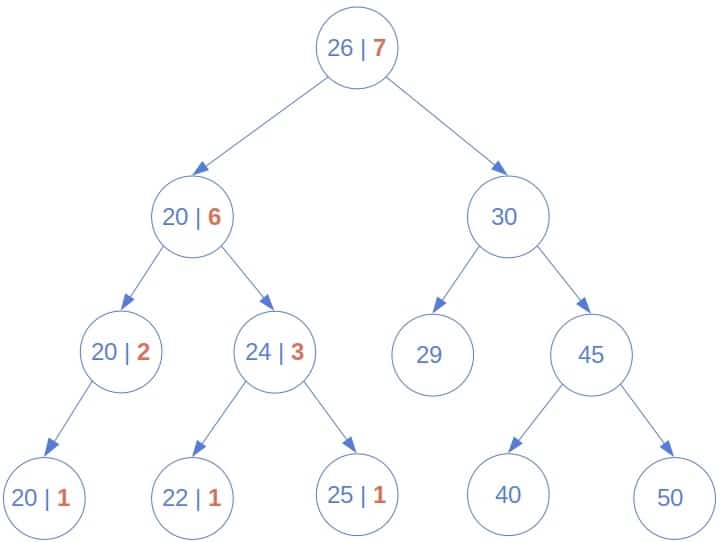
4.3. 时间复杂度
最坏情况下(x 比所有节点都大),该方法仍需遍历整棵树,复杂度为 **O(n)**。但在多数情况下,只访问排名数量的节点,比暴力法快。
5. 使用顺序统计树优化排名计算
如果我们为每个节点维护一个 size 属性(表示以该节点为根的子树节点总数),就可以跳过递归左子树,直接读取其 size,仅递归右子树。
5.1. 伪代码
algorithm Rank(node, x):
if node == null:
return 0
if node.value <= x:
leftSize <- if node.left == null then 0 else node.left.size
return 1 + leftSize + Rank(node.right, x)
else:
return Rank(node.left, x)
5.2. 示例
以下图为例,该算法在计算 27 的排名时仅遍历关键路径:
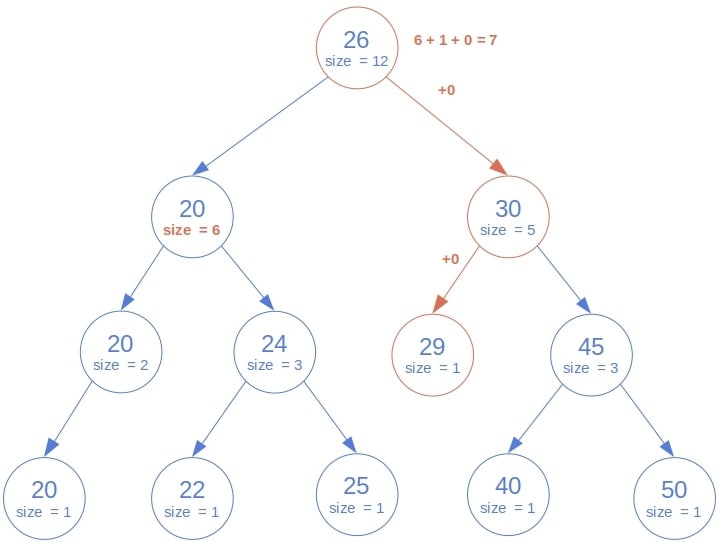
具体流程如下:
- 根节点 20 ≤ 27 → 读取左子树大小 6,加 1(根自己),再递归右子树。
- 右子树根 30 > 27 → 递归左子树。
- 左子树根 25 ≤ 27 → 读取左子树大小 0,加 1,递归右子树。
- 右子树为空 → 返回 0。
- 最终结果:6 + 1 + 0 = 7。
5.3. 时间复杂度
该方法每次只走一条路径,时间复杂度为 **O(h)**,其中 h 是树的高度。
- 如果树是平衡的,h ≈ log n → 复杂度为 O(log n)
- 如果树不平衡,h 可能等于 n → 复杂度为 O(n)
⚠️ 缺点是每次插入或删除节点后,都需要更新所有祖先节点的 size 属性。
5.4. 尾递归优化版本
由于每次递归调用只返回结果,无需后续处理,可以转换为尾递归形式,避免栈溢出:
algorithm TailRecursiveRank(node, x, current):
if node == null:
return current
if node.value <= x:
leftSize <- if node.left == null then 0 else node.left.size
current <- current + 1 + leftSize
return TailRecursiveRank(node.right, x, current)
else:
return TailRecursiveRank(node.left, x, current)
✅ 优点:可以进行尾调用优化,避免栈溢出
✅ 可以轻松转换为迭代版本
6. 方法对比与选择建议
| 方法 | 时间复杂度 | 是否需要 size 属性 | 是否需要平衡树 | 适用场景 |
|---|---|---|---|---|
| 暴力法 | O(n) | 否 | 否 | 其他方法不适用时 |
| 利用有序性 | O(n)(最坏) | 否 | 否 | 不支持节点增强时 |
| 顺序统计树 | O(h)(平均 O(log n)) | ✅ 是 | ✅ 是 | 高频查询、低频更新 |
选择建议:
- 如果树是按某种顺序构建的,且查询的顺序与之相同,使用第二种或第三种方法更高效。
- 如果可以为节点添加 size 属性,推荐使用第三种方法。
- 如果树频繁更新,而查询较少,第三种方法可能因频繁更新 size 而得不偿失。
- 如果查询频繁且树结构稳定,建议使用平衡的顺序统计树。
7. 总结
本文介绍了三种在二叉搜索树中计算节点排名的方法:
- 暴力法:遍历整棵树,效率最低,但实现简单。
- 利用有序性:减少不必要的递归,适用于大多数情况。
- 顺序统计树:效率最高(O(log n)),但需要维护 size 属性,适合高频查询、低频更新的场景。
📌 最终选择哪种方法,取决于具体使用场景和性能需求。