1. 简介
在本教程中,我们将探讨不同的特征缩放方法如何影响线性回归模型的预测能力。
我们会先介绍两种常用的特征缩放方法:归一化(Normalization) 和 标准化(Standardization),然后将它们应用到一个示例数据集上,最后对比它们在模型训练中的表现。
✅ 特别提醒:虽然线性回归本身对特征缩放不敏感,但在一些实际场景中(如使用正则化的线性模型),特征缩放可能会对模型表现产生显著影响。
2. 特征缩放简介
特征缩放(Feature Scaling)是指将不同量纲的特征值映射到统一的数值范围内,以避免某些特征因数值范围大而对模型造成不必要的影响。
⚠️ 对于像 KNN、SVM、逻辑回归(尤其是带正则化)这类依赖特征之间距离或梯度的算法,特征缩放非常重要。但对于像决策树这样的规则型算法,影响不大。
2.1 归一化(Normalization)
又称最小-最大缩放(Min-Max Scaling),将每个特征的值缩放到 [0, 1] 区间内:
$$ z = \frac{x - \min(x)}{\max(x) - \min(x)} $$
✅ 适用于数据分布不均、但没有明显异常值的场景。
2.2 标准化(Standardization)
又称 Z-score 缩放,将特征转换为均值为 0,标准差为 1 的分布:
$$ z = \frac{x - \mu}{\sigma} $$
✅ 更适合数据中存在异常值或分布偏态明显的场景。
✅ 一般情况下,标准化比归一化更常用,尤其是在深度学习和回归模型中。
3. Python 中的特征缩放示例
我们以 Concrete Compressive Strength 数据集为例,来展示特征缩放的效果。
该数据集包含 8 个数值型特征(如水泥、水、粉煤灰等成分含量)和一个目标变量(混凝土抗压强度),共 1030 条记录。
我们首先绘制原始数据的箱型图(Boxplot):
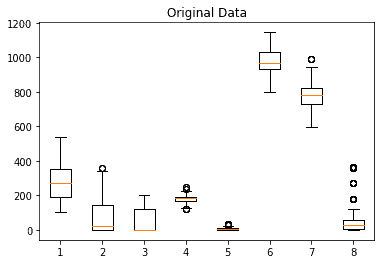
可以看到,各特征的取值范围差异很大,且部分特征存在明显的离群点。
3.1 归一化处理
使用 MinMaxScaler 对数据进行归一化:
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler().fit(X_train) # 仅用训练集拟合
X_norm = min_max_scaler.transform(X) # 对整个数据集进行转换
归一化后的箱型图如下:
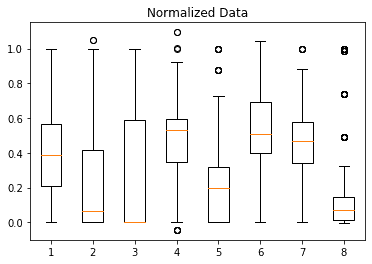
✅ 所有特征都被压缩到 [0, 1] 范围内
❌ 但离群值的存在可能导致大部分数据被压缩到一个更小的区间,丢失了部分信息
3.2 标准化处理
使用 StandardScaler 对数据进行标准化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train) # 仅用训练集拟合
X_std = scaler.transform(X) # 对整个数据集进行转换
标准化后的箱型图如下:
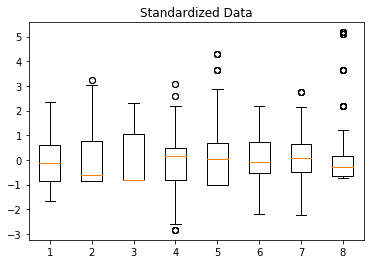
✅ 保留了离群值的信息
✅ 分布更集中,适合后续建模
3.3 归一化 vs 标准化对比
我们选取第 4 和第 5 个特征进行可视化对比:
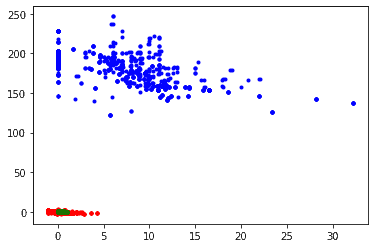
- 蓝色点:原始数据
- 红色点:标准化后的数据
- 绿色点:归一化后的数据
可以看出,归一化将数据点压缩得更紧密,而标准化保留了更多原始分布的结构信息。
4. 线性回归建模
接下来,我们使用线性回归模型来训练原始数据、归一化数据和标准化数据,并比较它们的表现。
4.1 模型训练代码
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
# 创建线性回归模型
regr = linear_model.LinearRegression()
# 训练模型
regr.fit(X_train, y_train)
# 预测
y_pred = regr.predict(X_test)
4.2 输出模型参数
print('Intercept: \n', regr.intercept_)
print('Coefficients: \n', regr.coef_)
输出示例:
Intercept:
-59.61868838556004
Coefficients:
[ 0.12546445 0.11679076 0.09001377 -0.09057971 0.39649115 0.02810985
0.03637553 0.1139419 ]
4.3 性能评估指标
print('MSE: %.2f' % mean_squared_error(y_test, y_pred))
print('R^2: %.2f' % r2_score(y_test, y_pred))
输出示例:
MSE: 109.75
R^2: 0.59
4.4 不同缩放方法的对比结果
| 数据集类型 | MSE | R² |
|---|---|---|
| 原始数据 | 109.75 | 0.59 |
| 归一化后的数据 | 109.75 | 0.59 |
| 标准化后的数据 | 109.75 | 0.59 |
✅ 线性回归本身对特征缩放不敏感,因此三种数据的模型性能一致
⚠️ 但如果是使用正则化的线性模型(如 Ridge、Lasso),特征缩放会影响模型表现
5. 结论
本文我们介绍了两种常见的特征缩放方法:归一化 和 标准化,并通过 Concrete 数据集展示了它们在实际数据上的应用。
我们还训练了线性回归模型,并发现:
- 特征缩放对线性回归模型的预测性能没有提升
- 但这并不意味着特征缩放无用
- 不同数据集和模型对特征缩放的敏感程度不同,应根据实际情况选择是否使用
✅ 小结建议:
- 对于线性回归模型,特征缩放不是必须的
- 但对于正则化模型、梯度下降类模型(如神经网络),特征缩放非常关键
- 推荐优先使用标准化(StandardScaler)
📌 参考资料