1. 引言
在本文中,我们将探讨一种计算机视觉技术 —— 目标检测(Object Detection),并重点分析两种主流的检测架构:SSD(Single-Shot MultiBox Detector) 和 YOLO(You Only Look Once)。
这两类算法的核心目标是通过在图像中生成边界框(bounding box)来识别和定位特定的目标对象。虽然它们都属于“单次检测”(Single Shot)模型,但在实现方式、检测精度和速度方面存在显著差异。本文将从架构设计、处理多框重叠的策略、性能表现以及应用场景等多个维度进行对比。
2. SSD 架构解析
SSD 模型的基本结构如下图所示:
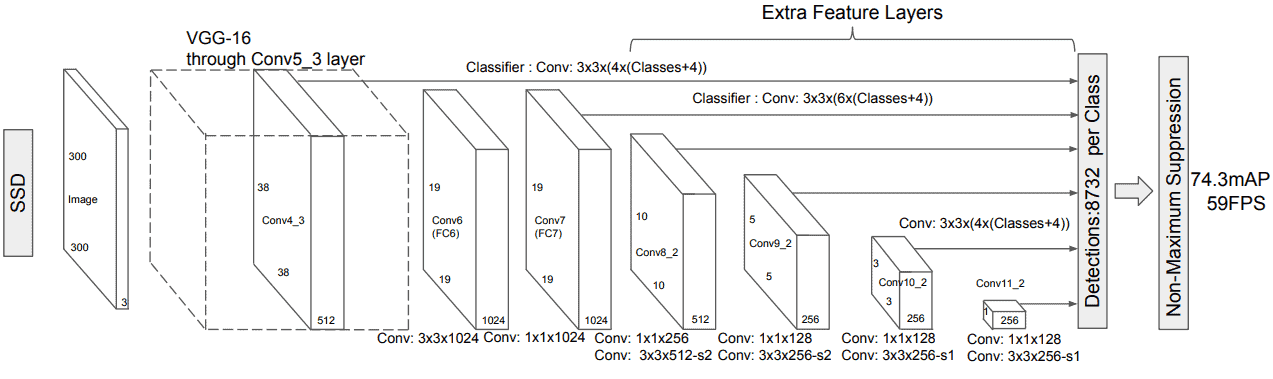
SSD 由 Wei Liu 等人在 2016 年提出,其核心思想是通过一次前向传播(forward pass)完成目标检测与分类任务。其名称中的 “Single-Shot” 即指此特性。
其模型结构基于 VGG-16 作为主干网络,并在其后添加多个卷积层,逐步降低特征图的尺寸,从而在不同尺度上提取特征。这些不同尺度的特征图被用于生成默认边界框(default bounding boxes),并通过卷积操作预测每个框中是否包含目标对象以及其类别。
✅ 关键特性:
- 多尺度特征图:提升对不同大小目标的检测能力
- 默认锚框(anchor boxes)机制:提升检测精度
- 使用 IoU(交并比)作为匹配真实框与预测框的标准,阈值通常设为 0.5
最终输出结果通过 NMS(Non-Maximum Suppression) 去除冗余的边界框,保留置信度高的预测。
3. YOLO 架构解析
YOLO 的模型结构如下图所示:
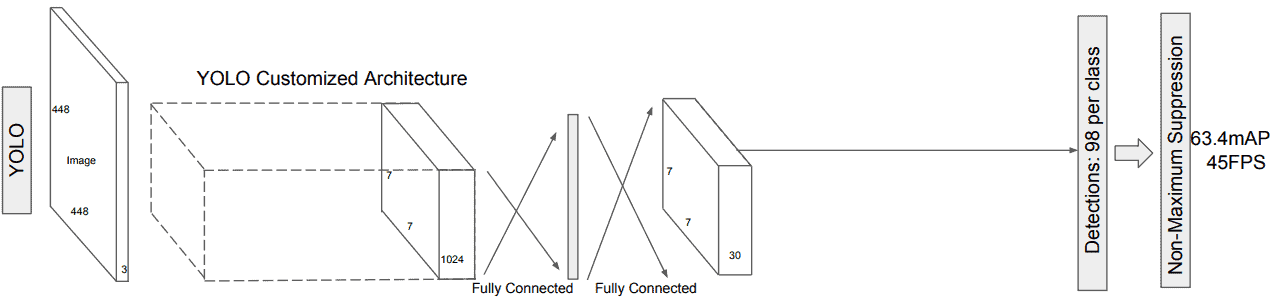
YOLO 由 Joseph Redmon 于 2016 年提出,是一种端到端(end-to-end)的目标检测方法。与 SSD 类似,它也只需一次推理即可完成目标检测,但其处理方式有所不同。
YOLO 将输入图像划分为一个固定大小的网格(如 7x7),每个网格负责预测多个边界框(bounding boxes)以及这些框的置信度(confidence score)和类别概率(class probabilities)。
⚠️ 关键限制:
- 每个网格只能预测两个边界框
- 每个网格只能属于一个类别
- 如果多个边界框的中心落在同一个网格中,容易造成预测重叠
与 SSD 类似,YOLO 同样使用 NMS 去除重叠度高的边界框(通常设置 IOU 阈值为 0.5)。
4. SSD 与 YOLO 的核心差异对比
| 对比维度 | SSD | YOLO |
|---|---|---|
| 检测机制 | 使用多尺度特征图和默认锚框 | 使用固定网格划分和边界框预测 |
| 边界框数量 | 每个特征图位置对应多个锚框 | 每个网格最多预测两个边界框 |
| 多框处理 | 使用 IoU 阈值 0.5 匹配真实框 | 使用 NMS 去除重叠框 |
| 小目标检测 | 表现更好,得益于多尺度特征 | 相对较弱,受限于网格粒度 |
| 模型结构 | 多个卷积层处理不同尺度特征 | 固定尺寸特征图处理 |
| 准确率 vs 速度 | 准确率较高,速度略慢 | 速度快,但精度略低 |
✅ 总结:
- SSD 更适合对检测精度要求较高的场景,如医学图像分析
- YOLO 更适合对实时性要求较高的场景,如自动驾驶、视频监控等
5. 应用场景分析
5.1 医疗影像识别
- 用途:肿瘤检测、DNA链识别、细胞分类等
- 推荐模型:SSD(精度高,适合对误检容忍度低的场景)
5.2 自动驾驶
- 用途:行人识别、交通灯识别、车道线检测等
- 推荐模型:YOLO(响应速度快,适合实时决策)
5.3 农业遥感图像分析
- 用途:作物健康监测、灌溉区域识别、杂草检测等
- 推荐模型:SSD(可处理多尺度目标,如不同大小的农田作物)
5.4 视频监控系统
- 用途:行为识别、异常检测、目标追踪等
- 推荐模型:YOLO(低延迟,适合视频流处理)
6. 总结
本文我们系统地分析了目标检测领域中两个经典模型:SSD 和 YOLO。
尽管它们都属于“单次检测”模型,但在架构设计、多框处理机制、精度与速度之间存在明显差异:
- SSD:精度更高,适合对准确率要求严苛的场景
- YOLO:速度更快,适合需要实时响应的应用
选择哪一种模型,应根据具体业务需求进行权衡。如果你的系统需要快速响应但允许一定误检率,YOLO 是更好的选择;如果追求高精度,尤其是对小目标敏感的场景,SSD 更加合适。
✅ 建议:在实际部署前,务必在目标数据集上进行充分的模型评估与调参。