1. 简介
在编写循环逻辑时,Off-by-One 错误(简称 OBOE)是一种非常常见但又容易被忽视的逻辑错误。它通常发生在遍历数组、字符串、集合等连续数据结构时,由于边界条件处理不当,导致循环多执行一次或少执行一次。
这种错误虽然不会导致编译失败,但会在运行时造成数据访问错误、内存越界、甚至程序崩溃等严重后果。尤其在系统底层或安全敏感的代码中,其影响更不可忽视。
2. 核心概念
Off-by-One 错误本质上是对连续内存块起始和结束位置的误判。我们通常用一块大小为 N 的内存来存储 N 个元素,每个元素占一个单位。当我们循环访问这些元素时,如果循环次数是 N-1 或 N+1,就会出现 OBOE。
比如:
- 少访问一个元素(漏掉末尾)
- 多访问一个元素(越界访问)
下图形象地展示了 Off-by-One 错误的表现形式:
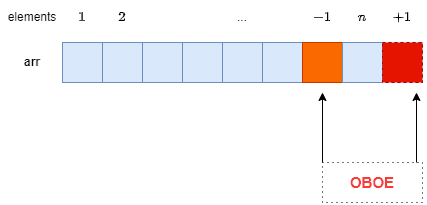
3. 典型场景
3.1. 索引方式不一致
这是最常见的 OBOE 场景之一。Java 中数组索引从 0 开始,而有些程序员习惯从 1 开始计数,就会导致越界访问或漏掉第一个/最后一个元素。
举个例子:我们有一个长度为 5 的数组 arr = {2, 4, 6, 8, 10},如果使用 1~5 作为索引进行访问:
arr[1]实际访问的是 4(不是预期的 2)arr[5]会越界,抛出ArrayIndexOutOfBoundsException
✅ 踩坑提醒:这类错误在逻辑上不容易察觉,但在运行时会直接导致异常。
解决方法很简单:始终使用 0-based 索引遍历数组。
3.2. 遍历子数组时的边界错误
当我们想访问数组中从 m 到 m+n 的子数组时,如果不注意循环条件,很容易出错。
错误示例(Java 伪代码):
for (int index = m; index <= m + n; index++) {
tmp = arr[index];
}
上面的循环会多访问一次 arr[m + n],如果数组长度不够就会越界。
正确做法是:
for (int index = m; index < m + n; index++) {
tmp = arr[index];
}
⚠️ 注意:这里使用的是 < 而不是 <=,因为我们希望访问 m 到 m + n - 1 范围内的元素。
4. 安全隐患
Off-by-One 错误在内存操作中可能引发严重的安全问题,特别是在使用 C/C++ 这类没有边界检查的语言时。
举个例子:我们分配了 n 字节的内存空间,但试图写入 n+1 字节的数据。这会导致:
- 覆盖相邻内存中的数据
- 破坏内存结构
- 触发段错误(Segmentation Fault)
- 甚至可能被黑客利用,注入恶意代码
在 Little-Endian 架构中,这种错误可能覆盖内存地址的低位字节,从而修改跳转地址,引导程序执行恶意代码。
✅ 解决方案:
- 在更新结构前检查目标结构的大小
- 若大小不一致,抛出异常或拒绝操作
- 使用安全函数(如
strncpy而不是strcpy)避免缓冲区溢出
5. 解决方案
5.1. 手动模拟循环逻辑
在写代码之前,先用纸笔手动模拟一遍循环逻辑,尤其是边界条件。这样可以提前发现索引设置是否合理。
5.2. 使用半开区间表示法
推荐使用半开区间 [start, end) 表示范围,比如:
[0, n)表示从 0 到 n-1 的范围(共 n 个元素)
这种方式在 Java、Python、C++ 等语言中广泛使用,有助于统一索引逻辑,减少边界判断错误。
5.3. 编写边界测试用例
在单元测试中覆盖所有边界情况:
- 空数组
- 只有一个元素的数组
- 刚好等于最大索引的值
- 比最大索引大 1 的值
使用 JUnit、TestNG 等测试框架编写自动化测试,确保每次代码变更后仍能通过这些边界测试。
6. 总结
Off-by-One 错误虽然简单,但非常容易被忽视。它通常出现在:
- 数组遍历
- 字符串处理
- 内存操作
- 循环边界判断
这类错误可能导致程序崩溃、数据异常、甚至安全漏洞。因此:
✅ 在编写循环时务必仔细检查边界条件
✅ 使用半开区间表示法统一逻辑
✅ 编写全面的单元测试覆盖边界情况
只有对边界条件保持高度警惕,才能有效避免 Off-by-One 错误的发生。