1. 引言
在本教程中,我们将探讨两种训练强化学习(Reinforcement Learning, RL)智能体的方法:On-policy(同策略)学习与 Off-policy(异策略)学习。
我们会先回顾它们各自解决的问题,分析其优缺点,并通过具体算法如 SARSA 和 Q-learning 来说明两者的区别。
2. 强化学习基础
当我们面对一个复杂的环境时,强化学习是一个非常有效的工具。这个环境可以是游戏、导航路径,甚至是任何可以被建模为一系列状态  的系统。
的系统。
我们的目标是找到一个最优策略  ,使得智能体在每个状态 下都能选择最优动作
,使得智能体在每个状态 下都能选择最优动作  。当找到这样一个策略时,我们通常说“解决了”这个环境。
。当找到这样一个策略时,我们通常说“解决了”这个环境。
示例:虫子找苹果
考虑一个虫子在网格中寻找苹果的例子。虫子是智能体,网格中的每个格子代表一个状态。每个状态都有一个奖励值:
- 普通格子奖励为 -1
- 苹果所在格子奖励为 +5
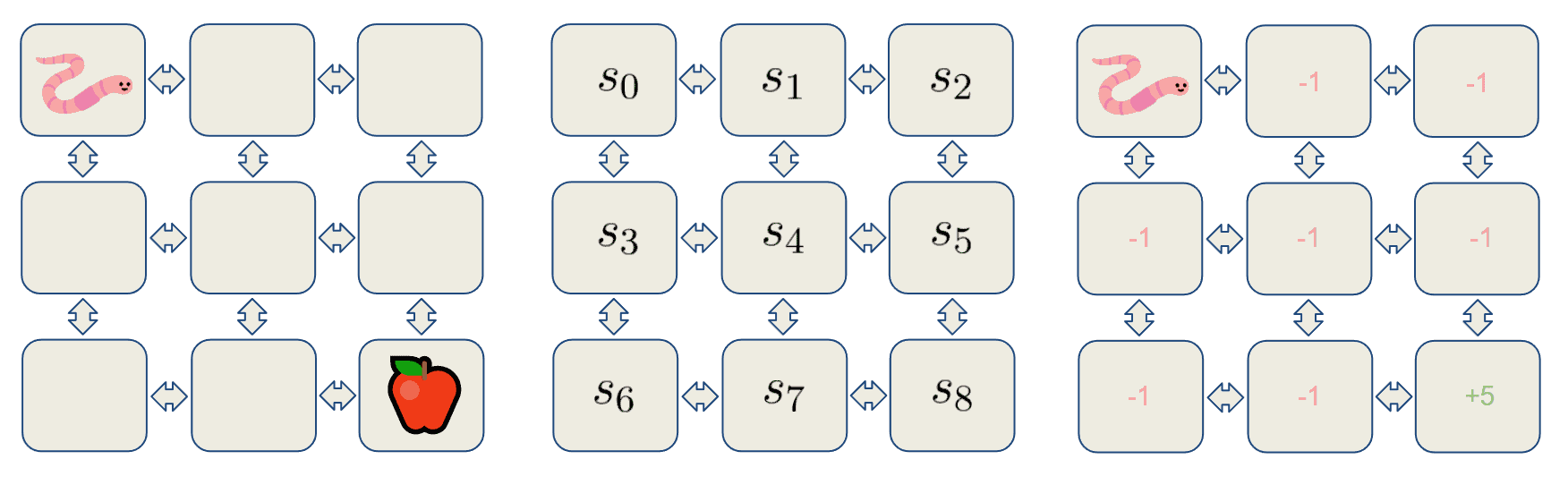
这是一个最简化的 RL 问题。但在实际中,环境通常非常复杂,因此我们使用蒙特卡洛方法采样环境,逐步学习其规律。
我们让智能体根据策略  与环境交互,直到达到终止状态(时间步为 T),这一过程称为一个 episode(回合)。一个 episode 包含一系列状态、动作和奖励:
与环境交互,直到达到终止状态(时间步为 T),这一过程称为一个 episode(回合)。一个 episode 包含一系列状态、动作和奖励:
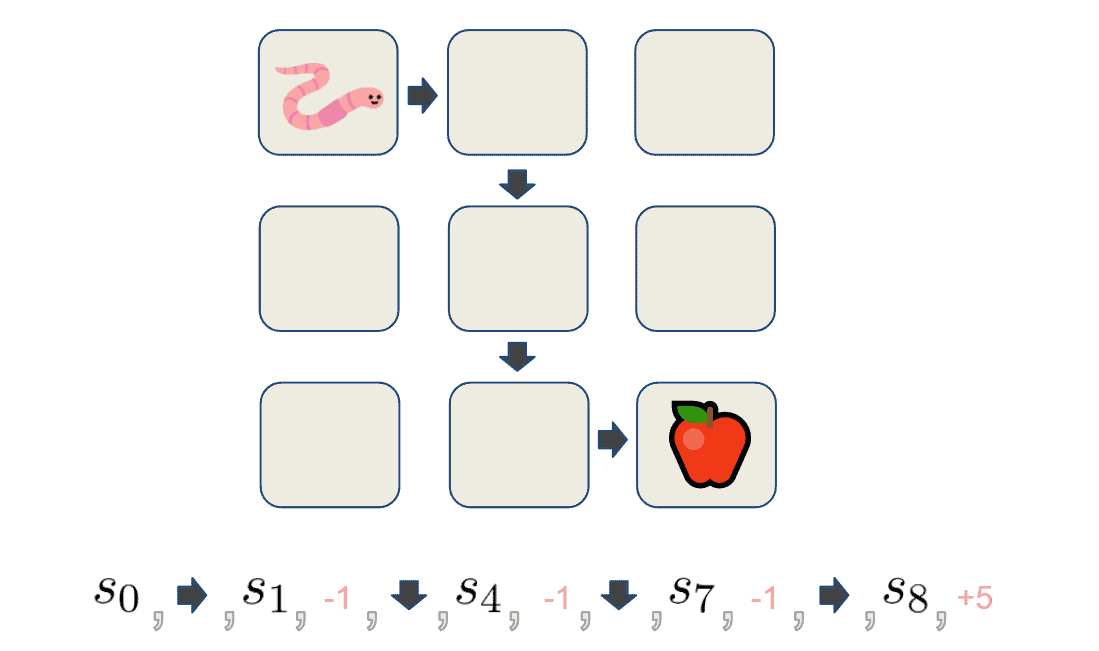
我们通过收集多个 episode 来估计状态价值函数  或状态-动作价值函数
或状态-动作价值函数  。
。
✅ 状态价值函数:表示从状态 s 出发,按策略 π 行动所能获得的期望累计奖励。 ✅ 状态-动作价值函数:表示在状态 s 下采取动作 a 后,按策略 π 行动能获得的期望累计奖励。
这两个函数用于评估和改进策略。一旦我们准确估计了它们,就可以构建出最优策略。
3. 探索 vs 利用
收集的 episode 越多,对函数的估计就越准确。但这里存在一个关键问题:如果策略改进算法总是贪心更新策略,那么它只会选择当前已知最优动作,忽略其他可能带来更高奖励的动作。
这就引出了强化学习中的经典问题:探索 vs 利用(Exploration vs. Exploitation)。
- Exploitation(利用):选择当前已知最优动作
- Exploration(探索):尝试未知动作,发现更高奖励
我们通常在这两者之间寻求平衡。完全探索会耗费大量时间;完全利用则容易陷入局部最优。
为了解决这个问题,有两种主流方法:On-policy 和 Off-policy。
4. On-policy 方法
On-policy 方法通过在策略中引入随机性来解决探索与利用的矛盾。也就是说,它以一定概率选择非最优动作。这类策略通常称为  -greedy 策略。
-greedy 策略。
具体来说,它以 的概率随机选择动作,以  的概率选择当前最优动作。
的概率选择当前最优动作。
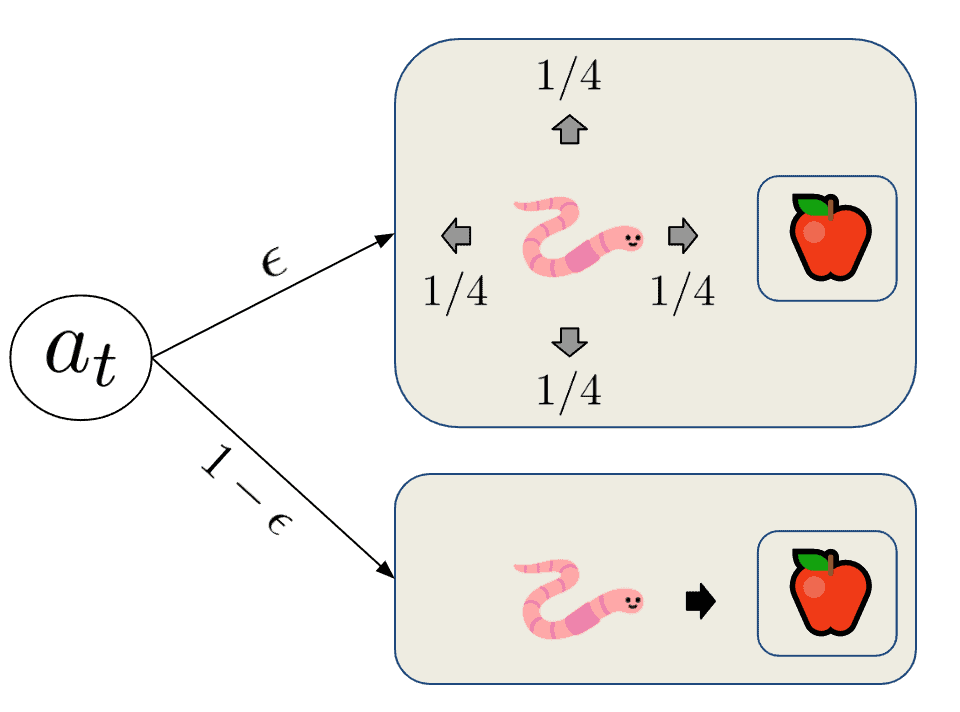
其中,非最优动作的概率为  ,最优动作的总概率为:
,最优动作的总概率为:
$$ P(a_t^{*}) = 1 - \epsilon + \epsilon / |\mathcal{A}(s)| $$
✅ 优点:收敛速度快,因为最优动作被采样得更频繁
❌ 缺点:容易陷入局部最优,探索能力有限
4.1 SARSA
SARSA 是一种典型的 On-policy 算法,使用 -greedy 策略。它的名字来源于其更新方式:
$$ Q^{new}(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)) $$
其中:
 :新的 Q 值
:新的 Q 值 :当前状态与动作
:当前状态与动作 :下一状态的奖励
:下一状态的奖励 :下一状态与动作
:下一状态与动作 :学习率
:学习率 :折扣因子
:折扣因子
⚠️ 注意:SARSA 的更新依赖于当前策略选择的下一个动作  ,因此它是 On-policy 的。
,因此它是 On-policy 的。
5. Off-policy 方法
Off-policy 方法提供了一种不同的探索与利用平衡机制。与 On-policy 不同,它使用两个策略:
- Behavior Policy(行为策略):用于探索和生成 episode
- Target Policy(目标策略):用于估计和改进函数
行为策略  通常是 -greedy,用于探索;目标策略 通常是贪心策略,用于学习。
通常是 -greedy,用于探索;目标策略 通常是贪心策略,用于学习。
✅ 优点:可以从其他策略的数据中学习,灵活性强
❌ 缺点:存在分布不匹配问题,需要使用重要性采样(Importance Sampling)来解决
5.1 Q-learning
Q-learning 是一种非常流行的 Off-policy 方法,也被称为 SARSA Max。它的更新公式如下:
$$ Q^{new}(S_t, A_t) \leftarrow (1 - \alpha) Q(S_t, A_t) + \alpha \left( R_{t+1} + \gamma \max_a Q(S_{t+1}, a) \right) $$
其中:
 :由行为策略 b 选择
:由行为策略 b 选择 :由目标策略选择
:由目标策略选择
⚠️ 关键区别:Q-learning 的更新总是选择下一个状态中 Q 值最大的动作,而不是根据当前策略选择。因此它是 Off-policy 的。
6. 总结
在本文中,我们回顾了强化学习的基本概念,并比较了两种主要策略:
| 类型 | 策略数量 | 是否使用当前策略生成数据 | 是否使用贪心更新 | 代表算法 |
|---|---|---|---|---|
| On-policy | 1 | 是 | 是 | SARSA |
| Off-policy | 2 | 否 | 是 | Q-learning |
✅ On-policy 更适合需要策略本身探索的场景,收敛快但易陷入局部最优
✅ Off-policy 更灵活,可以从其他策略的数据中学习,适合大规模或复杂环境
两种方法各有优劣,选择时应根据具体任务需求权衡。