1. 简介
在机器学习中,特征工程(Feature Engineering)是提升模型准确率的关键环节之一。通过从原始数据中生成新的变量,我们可以让模型更好地捕捉数据中的规律。
本文将重点讲解一种常用的特征编码方式:One-Hot 编码(One-Hot Encoding),并说明其适用场景、实现方式以及使用过程中可能遇到的问题。
2. 为什么要对数据进行编码?
在训练模型时,很多算法(如线性回归、神经网络等)要求输入为数值型数据,而不能直接处理字符串或类别型数据。
但实际业务中,很多字段是名义型类别变量(Nominal Categorical Features),即它们的取值之间没有顺序关系。例如:
- 性别:男、女
- 天气:晴、雨、风
- 商品类别:食品、电器、服装
如果我们简单地将这些类别映射为数字(如 男=0, 女=1),模型可能会错误地认为“女 > 男”,从而引入不必要的偏见(Bias)。
✅ 所以我们不能直接用数字编码,而是要用一种能保留无序性的编码方式 —— One-Hot 编码。
3. 什么是 One-Hot 编码?
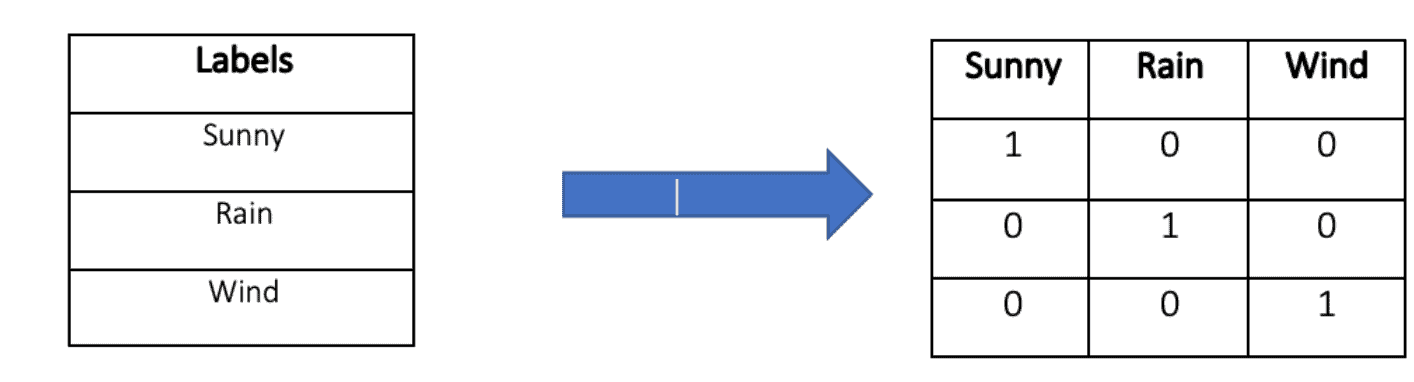
One-Hot 编码是一种将类别变量转换为多维二进制向量的方法。
每个类别对应一个维度,向量中仅有一个位置为 1,其余为 0。例如:
- 天气有三个类别:晴、雨、风
- 对应的 One-Hot 向量如下:
晴 = [1, 0, 0]
雨 = [0, 1, 0]
风 = [0, 0, 1]
这样处理后,每个类别在空间中是独立的,不会产生顺序关系。
4. 实战示例
我们来看一个 Pokémon 数据集的例子:
| Name | Total | HP | Attack | Defence | Type |
|---|---|---|---|---|---|
| Beedrill | 395 | 65 | 90 | 40 | Poison |
| Gastly | 310 | 30 | 35 | 30 | Poison |
| Pidgey | 251 | 40 | 45 | 40 | Flying |
| Wigglytuff | 435 | 140 | 70 | 45 | Fairy |
其中 Type 是类别变量。我们对其进行 One-Hot 编码后,结果如下:
| Name | Total | HP | Attack | Defence | Type-Poison | Type-Flying | Type-Fairy |
|---|---|---|---|---|---|---|---|
| Beedrill | 395 | 65 | 90 | 40 | 1 | 0 | 0 |
| Gastly | 310 | 30 | 35 | 30 | 1 | 0 | 0 |
| Pidgey | 251 | 40 | 45 | 40 | 0 | 1 | 0 |
| Wigglytuff | 435 | 140 | 70 | 45 | 0 | 0 | 1 |
5. 维度爆炸问题
⚠️ One-Hot 编码的一个显著缺点是会导致维度爆炸(Dimensionality Explosion)。
比如:
- 如果一个类别变量有 1000 个不同的值,就会生成 1000 个新特征
- 如果多个变量都进行 One-Hot 编码,特征维度会迅速膨胀
这会导致:
- 模型训练变慢
- 内存占用增加
- 容易过拟合
解决方案:
- 只保留高频类别:选择前 n 个最常见的类别进行编码,其余归为“Other”类
- 使用其他编码方式:如 Target Encoding、Embedding 编码等
- 使用树模型:部分树模型可以直接处理类别变量,如 LightGBM、CatBoost
✅ 一般建议设置 n 为 10 或 20,具体取决于你的数据规模和计算资源。
6. 小结
One-Hot 编码是一种将类别变量转换为数值型向量的有效方法,适用于大多数机器学习模型输入要求。它保留了类别之间的无序性,避免了引入人为偏序关系。
但要注意:
- 它会显著增加特征维度
- 可能影响模型训练效率和性能
- 不适合类别值过多的变量
✅ 在实际项目中,建议根据数据分布和模型特性选择合适的编码方式,One-Hot 并非万能解药。