1. 参数与超参数的核心区别
在机器学习中,参数(Parameters)和超参数(Hyperparameters)是两个常见但容易混淆的概念。理解它们之间的区别,有助于我们更好地构建和调优模型。
2. 参数(Parameters)
参数是模型通过训练数据自动学习得到的变量,它们决定了模型的具体行为。比如在经典的线性回归模型中:
$$ \widehat{y}(x) = ax + b $$
其中 $ a $ 和 $ b $ 就是这个模型的参数。模型训练的目标就是找到一组最优的 $ a $ 和 $ b $,使得预测值 $ \widehat{y} $ 尽可能接近真实值 $ y $。
下图展示了一个线性模型的拟合过程:
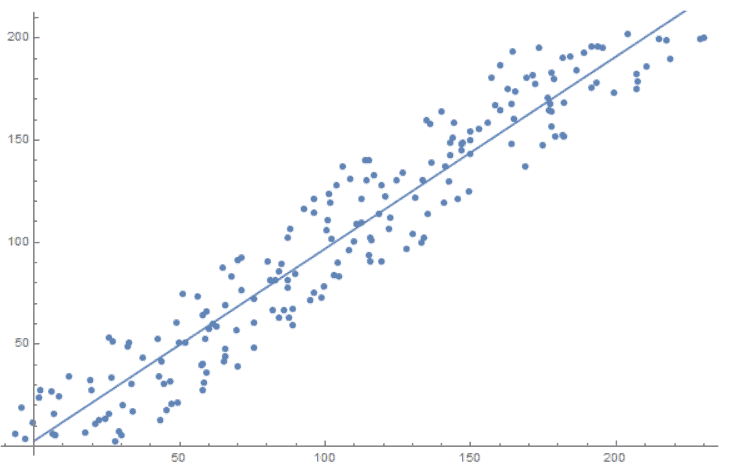
✅ 参数是由训练算法自动优化得出的,我们不需要手动设置它们的值。
3. 超参数(Hyperparameters)
与参数不同,超参数不是通过训练数据学习得到的,而是我们在训练开始前手动设定的配置项。它们用于控制训练过程或定义模型的结构。
举几个常见例子:
- 学习率(Learning Rate):控制梯度下降过程中每一步的步长
- 神经网络的层数(Number of Layers):决定了模型的复杂度
- 正则化系数(Regularization Strength):用于控制模型的泛化能力
- 批次大小(Batch Size):影响训练速度和内存使用
✅ 超参数通常在训练前设定,训练过程中不会改变。
⚠️ 选择合适的超参数对模型性能影响很大,但它们不像参数那样可以直接通过训练算法优化。我们需要通过交叉验证、网格搜索等方式尝试不同的组合,找到最优配置。
4. 参数 vs. 超参数:总结对比
| 维度 | 参数 | 超参数 |
|---|---|---|
| 来源 | 训练算法自动学习得出 | 人为在训练前设定 |
| 目的 | 描述模型的具体行为 | 控制训练过程或定义模型结构 |
| 搜索空间 | 通常非常大甚至无限 | 有限,通常通过实验尝试 |
| 调整方式 | 不需要手动调整 | 需要手动调优或使用自动化工具 |
| 示例 | 线性模型中的系数和偏置项 | 学习率、神经网络层数、正则化系数等 |
5. 总结
参数和超参数在机器学习中扮演着不同但互补的角色:
- 参数 是模型通过训练学习到的变量,决定了模型的具体行为
- 超参数 是我们提前设定的配置项,用于控制训练过程或模型结构
理解和区分这两者,有助于我们在模型调优时更有针对性地进行决策,避免在错误的方向上“踩坑”。
✅ 推荐做法:使用自动化工具(如 GridSearchCV、贝叶斯优化等)来高效搜索超参数空间,而参数则交给训练算法自动优化即可。