1. 概述
本文将讨论 管道(Pipe) 与 套接字(Socket) 的区别,并介绍一些关于进程间通信(IPC)机制的基本知识,以及我们为何需要这些机制。
2. IPC机制简介
进程之间的地址空间、堆栈和寄存器等资源是相互隔离的,因此我们必须通过IPC(Inter-Process Communication)机制来实现进程间的数据交换。常见的IPC机制包括:
- 管道(Pipe)
- 套接字(Socket)
- 共享内存(Shared Memory)
- 消息队列(Message Queue)
其中,管道和套接字是我们本文讨论的重点。虽然共享内存效率更高,但在跨机器通信时,我们更倾向于使用管道或套接字。
3. 管道(Pipe)
管道是一种最常见的进程间通信方式,其本质是一个具有两个端点的数据通道。在Linux/Unix系统中,调用 pipe() 系统调用会创建一个管道,并返回两个文件描述符:
fd[0]:用于读取数据fd[1]:用于写入数据
管道通常与 fork() 配合使用,实现父子进程间的通信。如下图所示,管道是通过内核空间实现的:
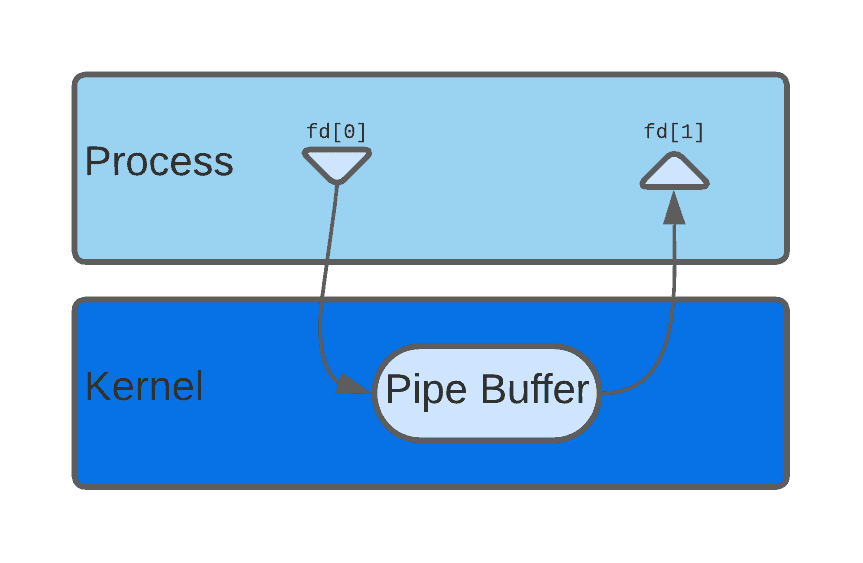
3.1 管道的工作原理
管道一般需要配合 fork() 使用。父进程创建管道后,子进程继承文件描述符,从而实现进程间通信。
下图展示了未关闭无用描述符时的双向通信情况:
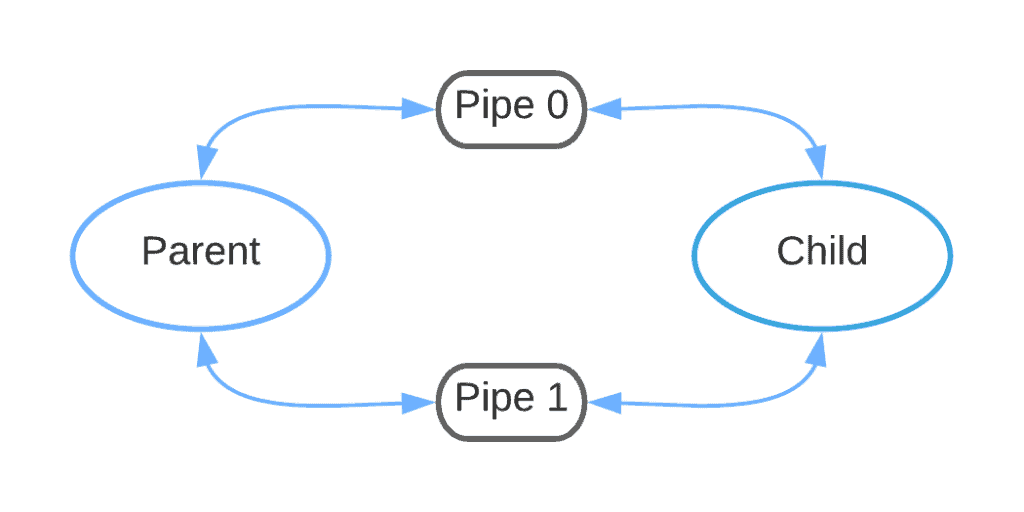
如果我们关闭了不必要的描述符,结构如下图所示:
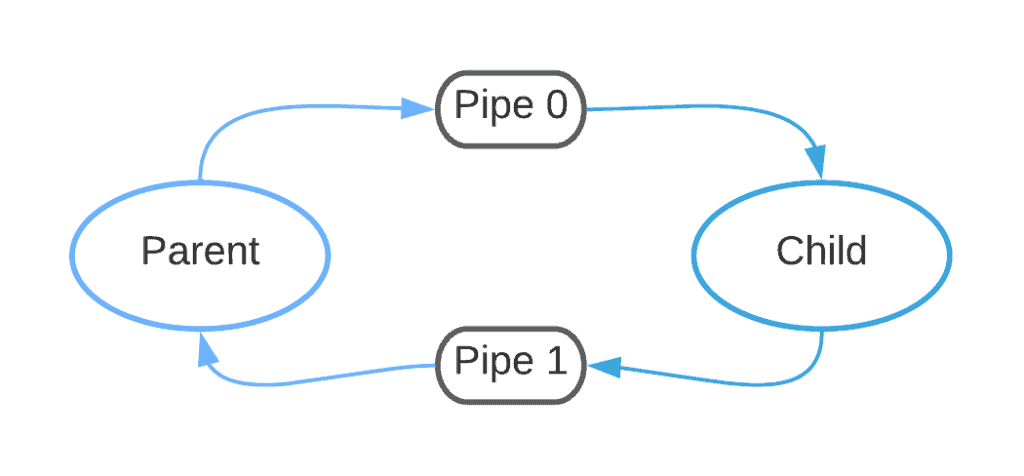
可以看到,管道是单向通信机制,如果希望实现双向通信,必须创建两个管道:一个从父进程到子进程,另一个从子进程到父进程。
3.2 管道的限制
- ✅ 适用于父子进程或相关进程之间通信
- ❌ 无法跨机器通信
- ❌ 仅支持一对一通信
- ❌ 不支持数据分包传输
4. 套接字(Socket)
套接字是现代网络通信的核心机制之一。早在1971年ARPANET时期,RFC 147中就首次提到了“socket”这个术语。如今的套接字接口源自伯克利套接字(Berkeley Sockets)API,广泛应用于Unix/Linux系统中。
套接字本质上是一个与网络协议绑定的通信端点,包含:
- 网络地址(IP)
- 端口号(Port)
每个端口代表一个服务入口,允许其他主机连接并进行通信。
4.1 套接字的工作原理
每个套接字都绑定到一个特定的网络协议(如TCP/IP或UDP)。应用程序通过调用 socket() 创建一个套接字,并返回一个文件描述符,用于后续的 read() 和 write() 操作。
与管道不同,套接字可以实现跨机器通信,适用于:
- 客户端-服务器通信
- 分布式系统
- 多播/广播通信
4.2 套接字的优势
- ✅ 支持双向通信
- ✅ 可跨机器通信
- ✅ 支持数据分包(基于IP协议)
- ✅ 支持多种协议(TCP、UDP等)
5. 管道与套接字的主要区别
| 特性 | 管道(Pipe) | 套接字(Socket) |
|---|---|---|
| 通信方向 | 单向 | 双向 |
| 进程关系 | 必须为父子进程 | 无限制 |
| 通信范围 | 同一主机 | 可跨主机 |
| 数据分包 | 不支持 | 支持(基于IP) |
| 使用场景 | 本地进程通信 | 网络通信、分布式系统 |
6. 总结
本文简要介绍了进程间通信的基本概念,并重点分析了管道与套接字的实现机制和主要区别。
- 管道适用于本地、父子进程间的简单通信
- 套接字则适用于跨机器、复杂网络环境下的通信
虽然本文主要以Unix/Linux系统为背景,但这些概念在Windows系统中也有对应的实现(如命名管道、Winsock)。
✅ 小贴士:在实际开发中,选择IPC机制时应根据通信范围、数据量、实时性等多方面综合考虑。例如本地通信优先考虑管道或共享内存,而网络通信则应使用套接字。