1. 引言
在本文中,我们将探讨机器学习中的两个核心概念:精确率(Precision) 和 平均精确率(Average Precision)。虽然这两个术语听起来相似,但它们在模型评估中扮演着截然不同的角色。
为简化理解,我们以二分类任务为例进行讲解,即模型需要将样本分为正类(positive)和负类(negative)。
2. 分类模型评估指标
在评估分类模型时,我们通常会关注多个指标,包括但不限于:
- 准确率(Accuracy)
- F1 分数(F1 Score)
- AUROC(Area Under the ROC Curve)
这些指标帮助我们判断模型在区分正负类方面的表现。为了计算这些指标,我们需要以下四个基本统计量:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | TP | FN |
| 实际为负类 | FP | TN |
其中:
- TP(True Positive):正确预测为正类的样本数
- FP(False Positive):错误预测为正类的样本数
- FN(False Negative):错误预测为负类的样本数
- TN(True Negative):正确预测为负类的样本数
3. 精确率(Precision)
精确率衡量的是模型预测为正类的样本中,有多少是真正的正类。
公式如下:
$$ \text{Precision} = \frac{TP}{TP + FP} $$
举个例子,假设模型预测了 150 个样本为正类,其中 120 个是真正的正类,则:
$$ \text{Precision} = \frac{120}{150} = 80% $$
这个指标告诉我们:模型预测为正类的结果有多可靠。
4. 平均精确率(Average Precision)
4.1 基于阈值的二分类模型
许多分类器(如 SVM、Logistic Regression)并不是直接输出类别标签,而是先输出一个连续值(score),然后通过一个阈值(threshold)来决定最终类别:
$$ f(x) = \begin{cases} 1, & \text{if } t(x) \geq \tau \ 0, & \text{otherwise} \end{cases} $$
其中:
- $ t(x) $:模型输出的置信度得分
- $ \tau $:决策阈值
通过调整 $ \tau $,我们可以得到一系列不同的分类结果,也就对应不同的精确率。
4.2 平均精确率的定义
平均精确率是对一系列阈值下精确率的加权平均值。
一种简单的计算方式如下:
$$ \text{AP} = \frac{1}{n} \sum_{i=1}^{n} p(\tau_i) $$
其中 $ p(\tau_i) $ 是在第 $ i $ 个阈值下的精确率。
更常用的一种加权平均方式是考虑召回率(Recall)的变化:
$$ \text{AP} = \sum_{i=1}^{n} (r_i - r_{i-1}) \cdot p_i $$
其中:
- $ r_i $ 是在第 $ i $ 个阈值下的召回率
- $ p_i $ 是在该阈值下的精确率
这种方式更合理,因为它将精确率的变化与召回率的提升结合起来。
5. 在精确率-召回率空间中的平均精确率
5.1 召回率(Recall)
召回率衡量的是模型在所有实际正类样本中,能正确识别出多少个正类:
$$ \text{Recall} = \frac{TP}{TP + FN} $$
它与精确率不同之处在于:
- 精确率关注的是预测为正类的样本是否准确
- 召回率关注的是所有正类样本是否都被识别出来
5.2 平均精确率的几何意义
在精确率-召回率(Precision-Recall, PR)坐标系中,平均精确率可以被看作是精确率曲线下的面积(Area Under the Precision Curve, AUPRC):
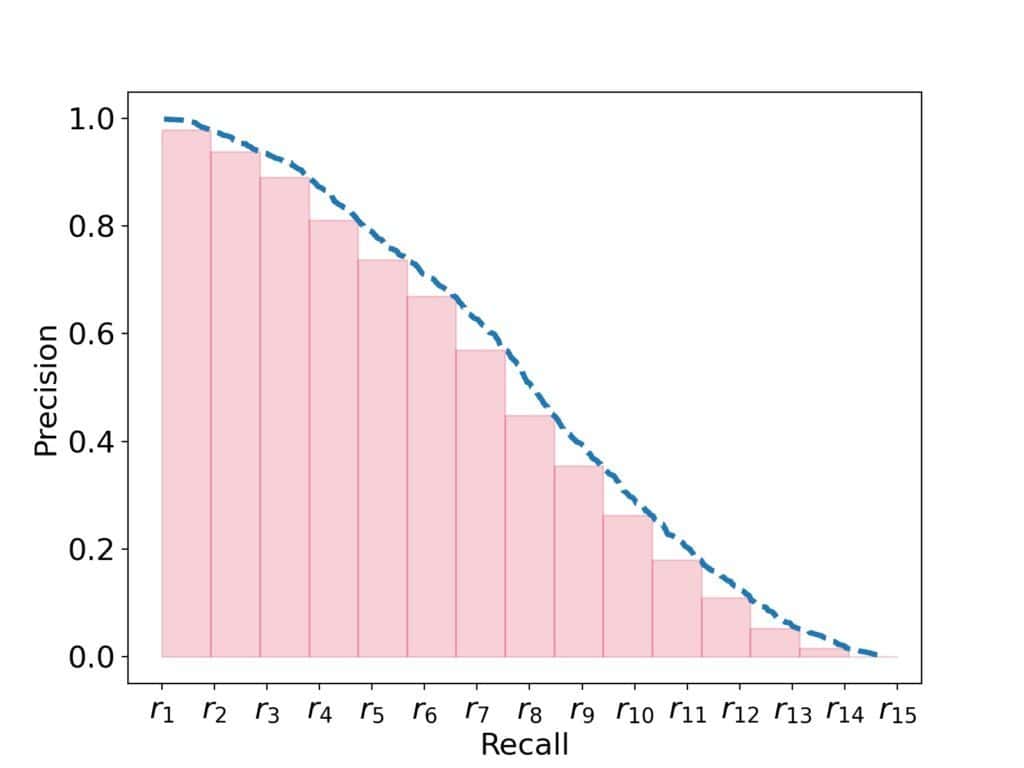
通过在 PR 空间中绘制曲线,我们可以更直观地比较不同模型的表现:
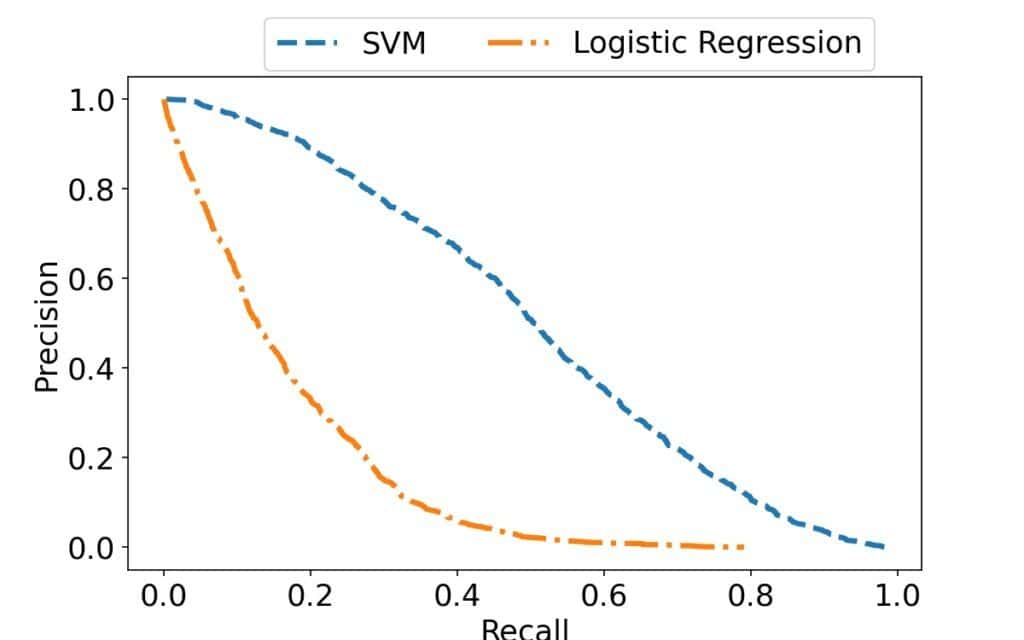
6. 使用建议与注意事项
⚠️ 精确率和平均精确率主要适用于正类样本更重要、负类影响较小的场景。
如果你的应用场景中:
- 假阴性(FN)影响很大(如医疗诊断)
- 需要同时关注正负类样本的表现
那么建议使用其他更全面的指标,如 AUROC 或 F1 分数。
7. 小结
| 指标 | 描述 | 适用场景 |
|---|---|---|
| 精确率(Precision) | 预测为正类的样本中真正为正类的比例 | 关注预测正类的准确性 |
| 平均精确率(AP) | 多个阈值下精确率的加权平均值 | 模型整体性能评估,尤其适合类别不平衡 |
✅ 精确率关注单个模型的表现,而平均精确率评估的是模型在不同阈值下的综合表现。
❌ 在负类样本同样重要的场景中,仅使用精确率或 AP 可能会忽略重要信息。