1. 简介
顾名思义,主成分分析(Principal Component Analysis,PCA)是用于提取模型中“主要”特征的一种方法。
在本教程中,我们将从三个不同层面来讲解PCA:
- 应用层面:PCA能提供哪些信息?我们如何利用这些信息?
- 实现层面:如何编写PCA程序?涉及哪些核心算法?
- 原理层面:PCA背后的数学和几何直觉是什么?
2. PCA 概述
假设我们有一个包含大量参数的数据集,其中一些参数对模型有显著影响,而另一些则毫无意义。
举个例子,在预测天气时,“星期几”这个参数可能没有意义,但“日期”可能有意义。也许更好的参数是“月份”或“季节”。当然还有温度、气压、风向、昨天的天气等其他参数。
关键在于:我们有很多参数可选。虽然我们可以凭经验选择“合理”的参数,但更科学的做法是使用一种定量方法来自动选择最优参数。
这就是主成分分析(PCA)的作用。它是一种定量方法,能帮助我们找到描述系统行为的最佳参数。
3. 奥卡姆剃刀原理与PCA
奥卡姆剃刀原理(Occam’s Razor)的核心是“如无必要,勿增实体”。
在建模中,这意味着我们应该优先使用简单模型。而PCA正是这种思想的体现:它帮助我们找到一组“足够好”的坐标,用来解释我们建模的数据。
简化模型不仅更美观,还能提升分析效率和结果质量。聚焦于关键参数(如PCA提供的主成分)几乎在任何数据分析技术中都能提高性能。包含无关参数只会降低效率,并引入噪声。
4. 主成分是什么?
4.1. 二维数据示例
我们来看一个二维数据的例子:
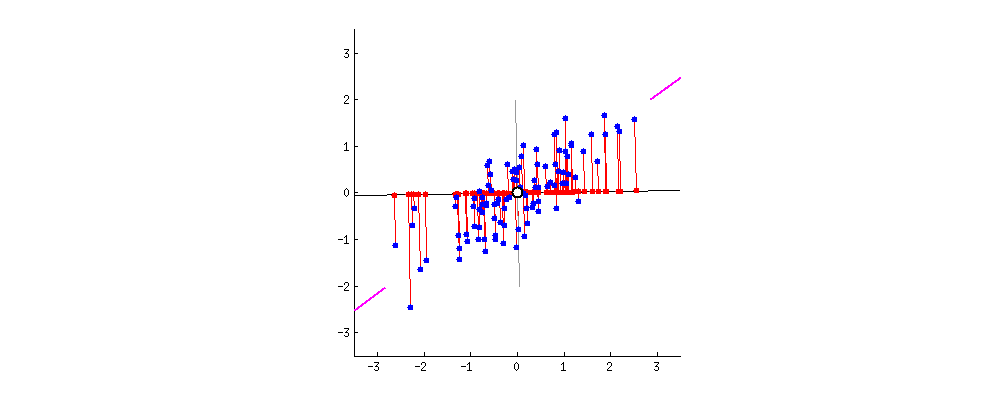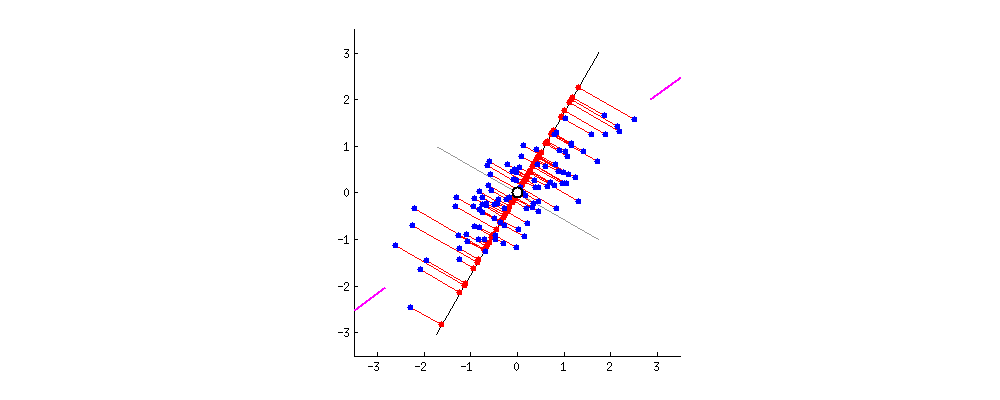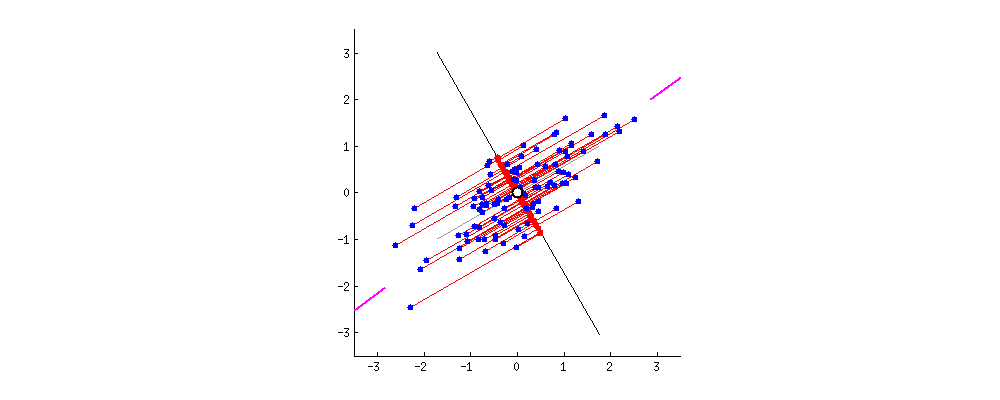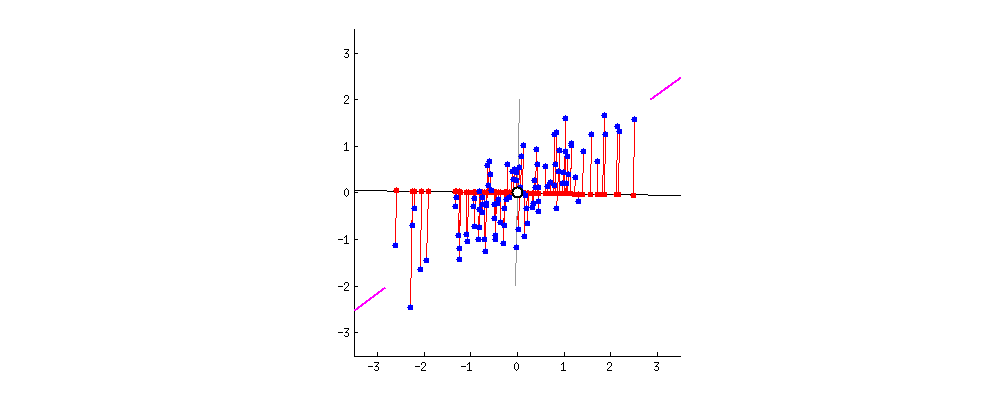
从图中可以看出,这些点大致呈椭圆形分布,说明x和y之间存在某种相关性。随着x的增加,y也倾向于增加。
我们可以通过绘制一条穿过这些点“主方向”的直线来量化这种关系,这条线就是主成分。
4.2. 主成分是否足够?
我们可以提出一个定量问题:“主成分是否足够?”与主成分垂直的方向(即正交方向)代表如果我们只使用主成分进行建模时可能产生的误差。
- ✅ 如果误差很小,说明主成分足以解释数据,模型可以从2维简化为1维。
- ❌ 如果误差较大,则说明我们需要保留更多维度。
4.3. 如何找到主成分?
我们首先计算所有点的中心点(即x和y的均值),然后以该点为原点建立新坐标系。接着旋转坐标轴,直到与主成分垂直方向的误差最小。
当主成分穿过椭圆长轴时,误差最小,此时我们找到了主成分的位置。
4.4. 新的坐标系
PCA的结果是找到一个新的坐标系,该坐标系以数据点的均值为中心,并旋转到最佳方向。
在二维例子中,新的x轴沿主成分方向旋转,表示“穿过点集的最佳直线”:

图中每个点在原始坐标系和新坐标系中都可以表示,只是数值不同。
4.5. 坐标旋转
坐标旋转是无损的,只是表示方式不同。例如,在原始坐标系中,点(1,1)在新坐标系中变为(√2, 0),说明x和y之间存在强相关性。
旋转后的坐标系中,y值接近于零,说明我们可以通过保留x值来近似整个数据。
4.6. PCA结果:成分向量
PCA的输出是一组正交单位向量,指向每个主成分的方向。
在二维例子中,PCA给出两个单位向量:
$$ \left(\frac{\sqrt{2}}{2},\frac{\sqrt{2}}{2}\right), \quad \left(-\frac{\sqrt{2}}{2},\frac{\sqrt{2}}{2}\right) $$
第一个向量指向主成分方向,第二个与其垂直。
将这些向量作为行组成一个矩阵T,就得到了从原始坐标到新坐标的变换矩阵:
$$ T = \begin{pmatrix} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2}\ -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \end{pmatrix} $$
乘以原始坐标即可得到新坐标。
4.7. 降维
PCA在n维空间中会生成一组“优化后的”单位向量。每个向量都有一个对应的特征值λ,表示该方向对数据的解释能力。
- ✅ 第一主成分具有最大λ值。
- ❌ λ值越小,说明该方向解释能力越弱。
我们可以通过保留前m个主成分(m < n)来实现降维。保留的主成分越多,数据保留的信息越多。
我们还可以通过以下公式计算每个主成分解释的数据比例:
$$ \text{解释比例} = \frac{\lambda_i}{\sum_j^n \lambda_j} $$
5. PCA 的实现步骤
5.1. 数据格式化为矩阵
将数据组织成一个矩阵,每行表示一个对象,每列表示一个参数。例如UCI Iris数据集有5个属性:
- 花萼长度(cm)
- 花萼宽度(cm)
- 花瓣长度(cm)
- 花瓣宽度(cm)
- 类别(Setosa, Versicolour, Virginica)
类别属性是非数值的,但可以映射为数字(如1, 2, 3)。
5.2. 数据均值归一化
PCA要求数据按列中心化(即每列减去该列均值)。
例如,原始数据为:
5.1, 3.5, 1.4, 0.2, 1
减去均值后变为:
-0.74, 0.45, 2.36, -1, -1
5.3. PCA 算法步骤
- 构建数据矩阵;
- 对矩阵按列进行均值归一化;
- 计算协方差矩阵;
- 计算协方差矩阵的特征向量和特征值;
- 根据特征值大小选择前m个主成分;
- 返回降维后的数据。
伪代码如下:
algorithm PCA(dataset):
dataMatrix <- FormDataAsMatrix(dataset)
meanAdjustedMatrix <- AdjustMatrixToMean(dataMatrix)
transposedMatrix <- TransposeMatrix(meanAdjustedMatrix)
covarianceMatrix <- Multiply(meanAdjustedMatrix, transposedMatrix)
(eigenvectors, eigenvalues) <- EigenvectorsAndEigenvalues(covarianceMatrix)
reducedData <- FilterOutUnusedCoordinates(eigenvectors, eigenvalues)
return reducedData
6. PCA 的数学原理
6.1. 向量基底
PCA的核心是坐标变换,这是线性代数中的基本概念。同一个向量可以用不同基底表示。
原始坐标系中的基底为:
$$ (1,0),\quad (0,1) $$
旋转后变为:
$$ \left(\frac{\sqrt{2}}{2},\frac{\sqrt{2}}{2}\right),\quad \left(-\frac{\sqrt{2}}{2},\frac{\sqrt{2}}{2}\right) $$
6.2. 维度压缩
如果所有点都落在一条直线上,那么我们只需要一个参数就可以描述整个数据集。即使这些点在二维空间中,我们也可以将其压缩到一维空间。
PCA的目标就是找到这样的“最优”坐标系。
6.3. 向量投影
PCA使用单位向量来将原始坐标投影到新坐标系中。投影的数学本质是点积。
- ✅ 向量完全一致:点积为1;
- ❌ 向量垂直:点积为0;
- ⚠️ 中间情况:点积为0~1之间的值。
6.4. 变换矩阵
PCA的结果是变换矩阵T,它由主成分单位向量组成。
在二维旋转-45度的例子中,变换矩阵为:
$$ T = \begin{pmatrix} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2}\ -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \end{pmatrix} $$
乘以原始坐标即可得到新坐标。
6.5. 协方差矩阵
协方差矩阵用于衡量各个参数之间的相关性。
计算公式:
$$ \text{Cov}(X, Y) = \frac{1}{N} \sum_i (X_i - \bar{X})(Y_i - \bar{Y}) $$
PCA通过计算协方差矩阵的特征值和特征向量来确定主成分。
6.6. 特征值与特征向量
特征向量是数据在新坐标系中的方向,特征值表示该方向上的数据方差。
- ✅ 特征值越大,说明该方向越重要;
- ❌ 特征值小的方向可以忽略。
7. 总结
在本教程中,我们从三个层面深入讲解了PCA:
- 应用层面:PCA能帮助我们识别数据中的关键特征,并进行降维;
- 实现层面:我们给出了PCA的实现步骤和伪代码;
- 原理层面:我们解释了PCA背后的数学和几何原理,包括协方差矩阵、特征值分解等。
掌握PCA不仅有助于理解数据,还能提升模型效率和可解释性。它是数据科学和机器学习中不可或缺的工具。