1. 概述
优先队列是一种非常基础但应用广泛的数据结构,它在操作系统调度、网络数据包处理、图算法(如 Dijkstra、Prim)等领域都有重要应用。与普通队列不同,优先队列中的元素不是按照“先进先出”顺序出队,而是根据优先级决定出队顺序。
本文将从优先队列的基本概念、实现方式、操作原理、时间复杂度分析以及实际应用场景等方面进行讲解,并使用二叉堆(Binary Heap)作为实现优先队列的核心结构。
2. 优先队列(Priority Queue)
优先队列是一种特殊的队列结构,其每个元素都带有一个优先级值。元素的出队顺序由优先级决定,优先级高的元素优先出队。如果两个元素优先级相同,则按入队顺序出队(FIFO)。
✅ 特性总结:
- 每个元素都有一个优先级
- 优先级高的元素先出队
- 优先级相同时按 FIFO 出队
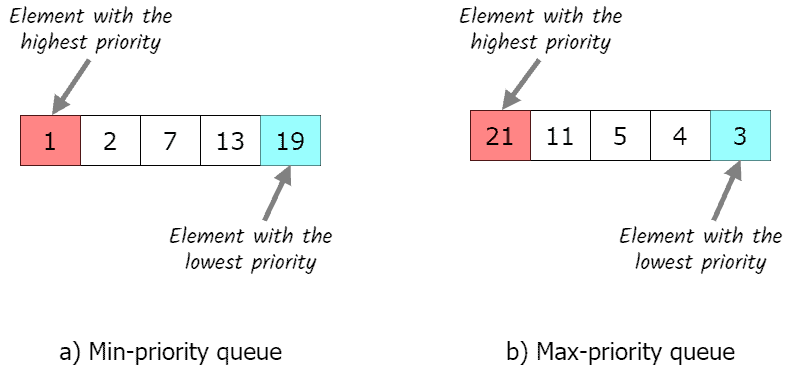
2.1. 类型(Type)
根据优先级的判断方式,优先队列可以分为两类:
- 最大优先队列(Max-priority Queue):优先级高的元素优先出队(如数字越大优先级越高)
- 最小优先队列(Min-priority Queue):优先级小的元素优先出队(如数字越小优先级越高)
本章主要讲解最大优先队列的实现和使用。
3. 实现方式
优先队列可以通过多种方式实现,常见的包括:
| 实现方式 | 插入时间复杂度 | 查看最大值 | 删除最大值 |
|---|---|---|---|
| 无序数组 | O(1) | O(n) | O(n) |
| 有序数组 | O(n) | O(1) | O(1) |
| 无序链表 | O(1) | O(n) | O(n) |
| 有序链表 | O(n) | O(1) | O(1) |
| 平衡二叉搜索树(BST) | O(log n) | O(log n) | O(log n) |
| 二叉堆(Heap) | O(log n) | O(1) | O(log n) |
✅ 推荐使用二叉堆实现优先队列,因其在插入和删除操作上时间复杂度稳定,且结构简单高效。
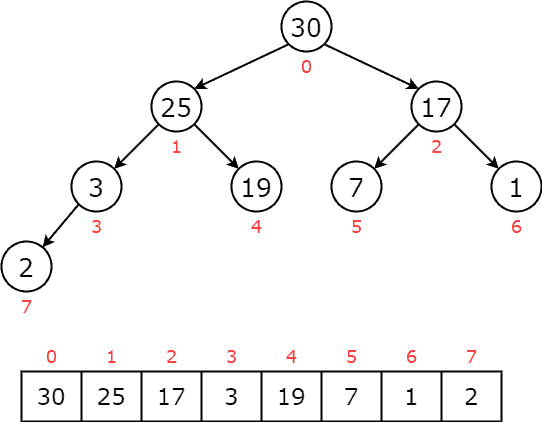
4. 二叉堆(Binary Heap)
二叉堆是实现优先队列最常用的数据结构,其具有以下特性:
- 是一个完全二叉树
- 每个节点的值都大于等于(最大堆)或小于等于(最小堆)其子节点的值
我们以最大堆为例进行讲解。
4.1. 堆结构表示
堆通常用数组实现,节点索引满足如下关系:
- 左子节点索引:
2 * i + 1 - 右子节点索引:
2 * i + 2 - 父节点索引:
(i - 1) / 2
5. 优先队列操作
5.1. 插入(Add)
插入操作流程如下:
- 将新元素插入数组末尾
- 向上调整(heapify up)直到堆性质恢复
✅ 示例代码(Java风格伪代码):
algorithm insertIntoPriorityQueue(heap, n, val):
i <- n
heap[n] <- val
n <- n + 1
while i > 0 and heap[(i - 1) / 2] < heap[i]:
swap(heap[(i - 1) / 2], heap[i])
i <- (i - 1) / 2
return heap
示例图解:
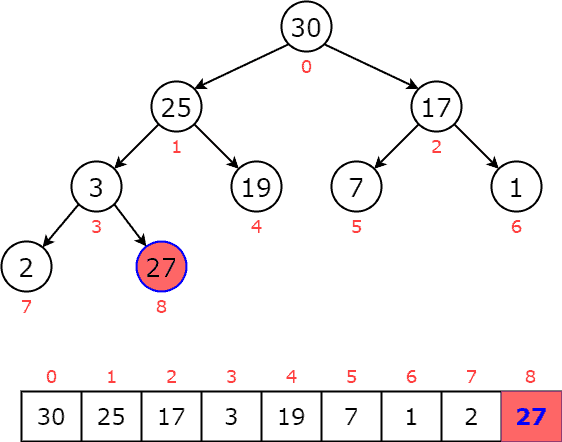
插入 27 后,不断向上交换直到堆结构恢复。
5.2. 删除最大值(Remove)
删除最大值操作流程如下:
- 将根节点(最大值)与最后一个节点交换
- 删除最后一个节点
- 向下调整(heapify down)直到堆性质恢复
✅ 示例代码(Java风格伪代码):
algorithm removeFromPriorityQueue(heap, n):
if n == 0:
return -1 // 队列为空
max <- heap[0]
heap[0] <- heap[n - 1]
n <- n - 1
i <- 0
while 2 * i + 1 < n:
left <- 2 * i + 1
right <- 2 * i + 2
selected_child <- left
if right < n and heap[right] > heap[left]:
selected_child <- right
if heap[i] >= heap[selected_child]:
break
swap(heap[i], heap[selected_child])
i <- selected_child
return max
示例图解:
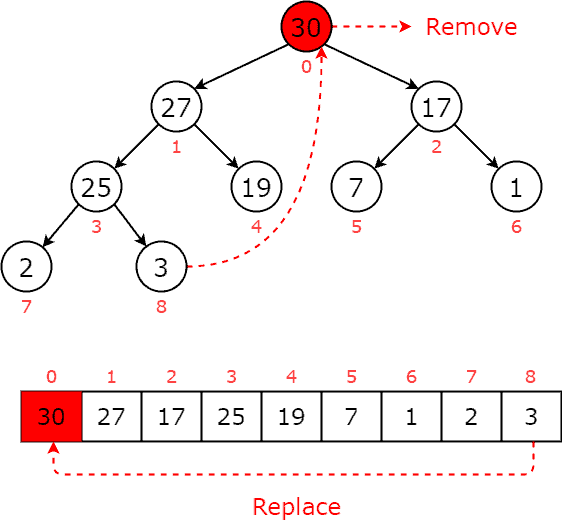
删除根节点后,向下交换直到堆结构恢复。
5.3. 查看最大值(Peek)
直接返回根节点即可,时间复杂度为 O(1)
✅ 示例代码:
algorithm peekPriorityQueue(heap, n):
if n == 0:
return -1
return heap[0]
6. 时间复杂度分析
| 操作 | 时间复杂度 |
|---|---|
| 插入(Add) | O(log n) |
| 删除(Remove) | O(log n) |
| 查看(Peek) | O(1) |
⚠️ 插入和删除操作都需要进行堆调整(heapify),所以时间复杂度为 O(log n)
7. 应用场景
优先队列因其高效性和灵活性,被广泛应用于以下领域:
- 算法:Dijkstra 最短路径、Prim 最小生成树、堆排序(Heap Sort)
- 数据压缩:如 Huffman 编码
- 操作系统:进程调度、中断处理、负载均衡
- 网络通信:带宽管理、数据包优先级调度
8. 小结
优先队列是一种非常实用的数据结构,适用于需要根据优先级处理数据的场景。使用二叉堆实现的优先队列,在插入、删除和查看操作上都具有良好的性能表现,是实现优先队列的首选方式。
✅ 关键点回顾:
- 优先队列根据优先级出队
- 二叉堆是实现优先队列的最佳选择
- 插入和删除的时间复杂度均为 O(log n)
- 优先队列广泛应用于算法设计和系统调度中