1. Introduction
In this tutorial, we’ll discuss how the Raft consensus algorithm works and examine its key benefits for distributed systems.
In distributed systems, keeping multiple servers in sync is a major challenge. If one node fails, the system should continue running without inconsistencies.
2. Why Consensus Matters in Modern Computing
Picture a distributed database handling millions of user accounts. When someone tries to register a new username like “Alice123,” every server in the system must immediately know whether that name is available.
Without a reliable consensus mechanism, chaos ensues; one server might accept the registration while another still shows the name as available. This inconsistency creates serious problems, from duplicate accounts to data corruption that could crash entire applications.
Consensus algorithms serve as the foundation for keeping distributed systems synchronized. They act as an organizational framework that coordinates multiple servers to work as a single, coherent unit.
These algorithms don’t just prevent conflicts, enable systems to maintain accuracy even when components fail or network connections become unreliable.
3. The Three Pillars of Consensus
Modern consensus algorithms provide three fundamental guarantees that keep distributed systems running smoothly:
First, they ensure agreement across all nodes. Every server arrives at the same conclusion about the system’s state, whether they’re determining if a username is taken or processing a financial transaction. This eliminates the risk of conflicting responses to client requests.
Second, they deliver fault tolerance. When servers crash or networks partition, the system continues operating without missing a beat. The remaining healthy nodes automatically compensate for failed components, maintaining service availability. This resilience transforms what would be catastrophic failures in single-server systems into minor, recoverable incidents.
Finally, they guarantee consistency. Clients always interact with the most up-to-date version of the system’s state. Whether a user checks their account balance from their phone in Tokyo or their laptop in New York, they’ll see the same, accurate information. This consistency builds trust in applications and prevents frustrating discrepancies that drive users away.
4. How Raft Works?
Raft’s operation centers around two fundamental processes that work in concert to maintain distributed system consistency. Leader election and log replication. During the leader election process, the system selects one node to act as the leader. Once the nodes elect a leader, the protocol proceeds to log replication, in which the leader sends new log entries to the follower nodes.
4.1. Leader Election
Raft organizes operations into sequential terms marked by monotonically increasing integers, serving as logical clocks that maintain event ordering and prevent leadership conflicts.
Nodes transition between three roles: Followers (passively awaiting heartbeats), Candidates (initiating elections after the timeout), and Leaders (managing cluster operations). When a Follower’s randomized 150-300ms election timeout expires without heartbeat reception, it becomes a Candidate by incrementing its term, self-voting, and soliciting peer votes.
Election safety is enforced through strict voting rules requiring majority approval and log recency verification (comparing last entry terms and log lengths), which together guarantee single-leader elections while prioritizing up-to-date candidates:

To handle split votes, Raft employs randomized timeouts that naturally stagger subsequent election attempts. Practical deployments should use odd-sized clusters (3, 5, or 7 nodes) and configure election timeouts to be at least 10 times the network broadcast latency.
4.2. Log Replication
Raft’s log replication follows a rigorous leader-coordinated process to ensure cluster-wide consistency. When a leader receives a client request, it validates and assigns a unique ID before appending the command to its log as uncommitted.
The leader then broadcasts AppendEntries RPCs containing its current term, previous log position (for continuity verification), new entries, and commit index. Followers perform three critical checks before persisting entries: term validation, log continuity confirmation, and stable storage verification:
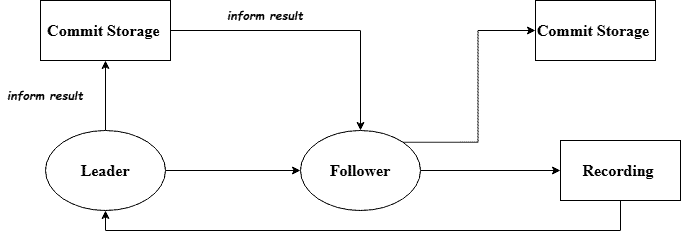
Commitment requires majority replication and sequential processing – entries only commit after all preceding ones are secured. The leader monitors progress through follower-specific indices (nextIndex/matchIndex), advancing the commitIndex upon quorum confirmation before applying changes to the state machine and responding to clients. This phased approach guarantees linearizability while maintaining availability.
Raft’s consistency mechanisms enforce two key invariants: the Log Matching Property ensures identical (index, term) entries share identical histories, while State Machine Safety preserves committed entries through failures via leader completeness requirements and a no-rewrite policy.
4.3. Practical Example
To better understand the operation of the Raft consensus algorithm, let’s consider a distributed system consisting of five servers: A, B, C, D, and E.
Initially, all servers start in a follower state. If a follower does not receive a heartbeat message signal indicating an active leader within a specified timeout, it transitions to the candidate state and initiates an election by incrementing its term and requesting votes from other servers.
For example, if server C’s timeout elapses first, it will request votes from A, B, D, and E. If C receives a majority of votes, it becomes the leader for the current term. The leader then begins sending periodic heartbeat messages to the followers to maintain its leadership and prevent new elections.
Once a leader is elected, client requests, such as “add transaction X,” are sent directly to the leader. The leader appends the request as a new log entry to its log and then sends AppendEntries remote procedure calls (RPCs) to all followers. For instance, if a client sends a command to server C, now the leader, it adds the entry X to its log and forwards it to A, B, D, and E. Once a majority of servers confirm they have received and written the entry, the leader commits the entry to its state machine and notifies the followers to commit as well.
This process ensures that all servers agree on the same sequence of committed log entries and that committed entries remain durable even if the leader fails after committing them. Furthermore, Raft’s mechanism guarantees that any new leader elected will always have an up-to-date log, preserving consistency throughout the system.
If the leader crashes, for example, if server C unexpectedly fails, the remaining follower servers detect the absence of heartbeat messages. This triggers a new leader election. The same election process repeats, and a new leader is elected among the remaining servers. This seamless recovery process ensures the continuity of the system’s operation without compromising the consistency of the replicated log.
5. Client Interaction and Consistency Management
Raft processes client requests through a structured pipeline where the leader validates commands, assigns unique IDs, and appends them as uncommitted log entries. The leader then replicates these entries via AppendEntries RPCs containing its current term, previous log position, new commands, and commit index.
Followers verify term validity and log continuity before persisting entries and acknowledging them. A majority must replicate each entry, and all prior entries must commit before the leader applies changes to its state machine and responds to clients, ensuring linearizability.
The protocol maintains two key invariants: the Log Matching Property guarantees identical entries share identical histories, enforced through append-only logs and consistency checks. State Machine Safety ensures committed entries survive failures via majority commitment, leader completeness requirements, and immutable committed logs. These properties work together to prevent data loss or inconsistency during normal operation and failure scenarios.
For fault tolerance, Raft automatically handles leader crashes through timeout-based elections and log reconciliation by new leaders. Network partitions are managed by preventing minority leaders from committing entries and forcing them to step down upon encountering higher terms. The log repair protocol efficiently synchronizes divergent logs by truncating at the first mismatch and resending subsequent entries, maintaining consistency while minimizing unnecessary data transfer.
6. Comparative Overview of Consensus Algorithms
We see several consensus algorithms in distributed systems, each optimized for different needs. Some prioritize simplicity, while others focus on Byzantine fault tolerance or high throughput.
Let’s examine the key players.
Raft is designed for clarity and ease of implementation. It separates leader election from log replication, making it more approachable than alternatives. Unlike Raft’s structured approach, Paxos offers robust consistency but with greater complexity – we often find it harder to implement correctly.
For Byzantine environments, we use PBFT when facing potential malicious actors. It powers many blockchain platforms that need strong security guarantees. Viewstamped Replication (VR) gives us Paxos-like guarantees with clearer operational separation.
In coordination services, we typically deploy ZAB – the engine behind ZooKeeper. It specializes in atomic broadcasts for high availability. For blockchain needs, we often choose Tendermint or HotStuff, which combine BFT with efficient leader-based consensus.
Let’s look at the example table below, a summary comparison of consensus algorithms:
Algorithm
Fault Model
Leader Role
Complexity
Use Cases
Key Features
Raft
Crash faults
Yes
Low
Distributed DBs, configuration services
Simplicity, clear log replication
Paxos
Crash faults
Optional
High
Critical services, distributed systems
Strong consistency, proven safety
PBFT
Byzantine faults
Yes
High
Blockchains, secure distributed systems
Tolerates malicious nodes
Viewstamped Rep.
Crash faults
Yes
Medium
Fault-tolerant services
Clear separation of leader/log roles
ZAB
Crash faults
Yes
Medium
Apache ZooKeeper
Atomic broadcast, high availability
Tendermint
Byzantine faults
Yes
Medium
Blockchains
Fast finality, high throughput
HotStuff
Byzantine faults
Yes
Medium
Scalable blockchains
Linear message complexity, modular
7. Conclusion
In this article, we discussed the Raft consensus algorithm, a distributed consensus protocol designed to be both understandable and practical for real-world systems. We examined how Raft achieves consensus through two key mechanisms: leader election and log replication.
The leader election process ensures cluster stability through term-based voting and randomized timeouts, while log replication guarantees consistency by requiring majority acknowledgment of entries before commitment.
The algorithm’s structured approach to distributed coordination makes it particularly valuable for systems requiring reliability and maintainability.