1. 概述
在本篇文章中,我们将学习备份(Backup)和灾难恢复(Disaster Recovery)之间的区别。虽然它们的目标都是保护企业免受数据或服务中断的影响,但它们的实现方式、使用场景和目标存在明显差异。
理解这两者的区别,有助于我们更好地制定系统容灾策略,避免在关键时刻“踩坑”。
2. 什么是备份?
备份是指手动或自动地对数据进行复制(例如创建 Linux 系统镜像)。
备份的主要目的是防止因数据损坏、硬盘故障、系统崩溃等原因导致的数据永久丢失。它通常用于以下场景:
- 意外删除数据
- 勒索软件加密
- 系统崩溃或损坏
- 审计或合规需求(如税务归档)
✅ 优点:实现简单,成本较低
❌ 缺点:恢复时间较长,不能保证数据实时性
3. 什么是灾难恢复?
灾难分为自然灾害和人为灾难两类:
- 自然灾难:如洪水、火灾、断电、硬件损坏(如网卡故障)
- 人为灾难:如程序 bug、误删数据、危险品泄漏等
灾难恢复指的是在灾难发生后,快速恢复应用程序、数据和服务的过程。
其核心机制包括:
- 应用故障转移(failover)到备用节点
- 数据切换到备用存储设备
- 等待主节点或主存储恢复后,再切换回来
✅ 优点:恢复时间短,服务连续性高
❌ 缺点:实施复杂,成本高
4. 备份与灾难恢复的区别
下面从多个维度来对比这两者的差异:
4.1 解决目标不同
| 类型 | 目标 |
|---|---|
| 备份 | 恢复数据(包括应用、开发数据、生产数据库等) |
| 灾难恢复 | 保证应用高可用,消除单点故障(SPOF) |
备份更注重数据完整性,而灾难恢复更注重服务可用性。
举个例子:
如果生产环境的应用还在运行,企业肯定希望尽可能减少停机时间。这时候,灾难恢复比从备份中恢复要快得多。
下图展示了一个典型的备份方案:
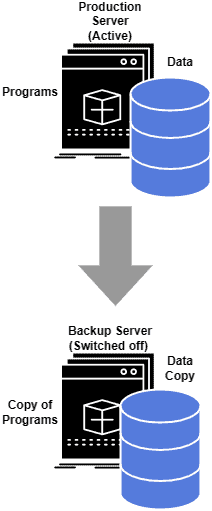
4.2 数据复制方式不同
| 类型 | 数据复制方式 |
|---|---|
| 备份 | 定时复制(如每小时或每天) |
| 灾难恢复 | 实时复制(持续同步应用状态和数据) |
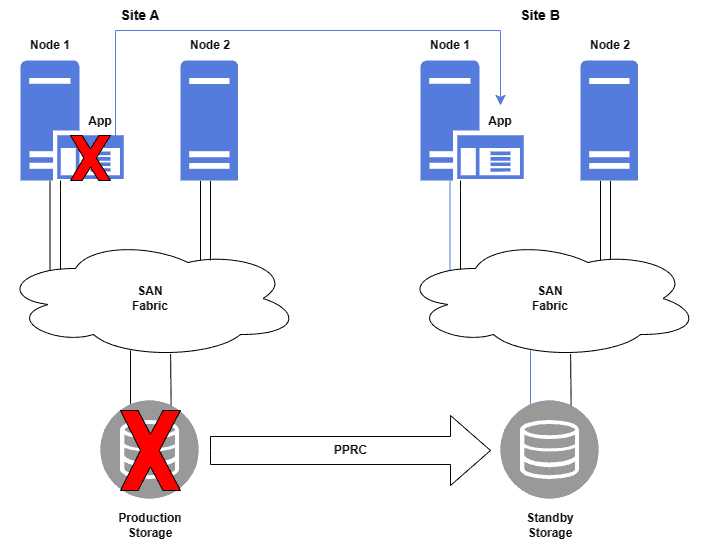
灾难恢复中,备用站点的数据与生产站点保持一致。例如,IBM 的 Metro Mirror 就是一种实现两地数据同步的技术。
下图展示了一个灾难恢复架构,使用了 Metro Mirror 技术:
4.3 自动化程度不同
| 类型 | 自动化程度 |
|---|---|
| 备份 | 多为手动操作(备份和恢复) |
| 灾难恢复 | 支持自动故障转移(failover) |
灾难恢复方案中,当主节点出现故障时,系统可以自动切换到备用节点,从而保证服务不中断。
4.4 实施时间和成本不同
| 类型 | 实施时间 | 成本 |
|---|---|---|
| 备份 | 短 | 低(仅需存储设备和维护) |
| 灾难恢复 | 长 | 高(需额外节点、存储设备、甚至备用站点) |
灾难恢复需要工程师全面分析生产环境中的单点故障点,并设计冗余方案,工程量和复杂度远高于普通备份。
5. 总结
| 对比维度 | 备份 | 灾难恢复 |
|---|---|---|
| 核心目标 | 数据恢复 | 服务可用性 |
| 数据复制 | 定时 | 实时 |
| 自动化 | 低 | 高 |
| 成本 | 低 | 高 |
| 恢复时间 | 长 | 短 |
备份是基础,灾难恢复是保障。两者可以互补,但不能互相替代。
在实际项目中,建议根据业务需求制定合适的策略:
- 对于非关键系统,可以只做备份
- 对于高并发、高可用要求的系统,必须部署灾难恢复机制
最后提醒一句:
别等到系统崩溃了才想起来没有灾难恢复机制。那时候,不是数据恢复慢的问题,而是整个业务停摆的风险。⚠️