1. 引言
在本篇文章中,我们将对比两种用于动态系统决策的方法:强化学习(Reinforcement Learning, RL) 和 最优控制(Optimal Control)。我们将分别介绍它们的基本概念、数学方法,并分析它们的核心区别与应用场景。
2. 强化学习
强化学习是一种用于决策问题的数学框架,最早由 John von Neumann 和 Oskar Morgenstern 在 1950 年代的著作《博弈论与经济行为》中提出。
在机器学习领域,强化学习通过训练“智能体(Agent)”来做出决策。这些智能体在特定环境中执行动作(action),根据动作的结果获得奖励(reward)或惩罚(penalty),从而不断优化其策略(policy)以最大化长期回报。
✅ 强化学习的本质是一个试错过程:智能体通过与环境交互来学习最优策略。
下图展示了强化学习的基本结构:
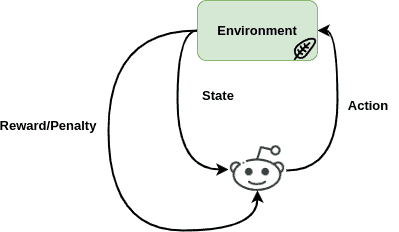
2.1 数学建模
强化学习问题通常建模为 马尔可夫决策过程(Markov Decision Process, MDP),其定义包括以下几个核心元素:
- 状态集合 $ S $
- 动作集合 $ A $
- 转移函数 $ T(s' | s, a) $:表示在状态 $ s $ 执行动作 $ a $ 后转移到状态 $ s' $ 的概率
- 奖励函数 $ R(s, a) $:表示在状态 $ s $ 执行动作 $ a $ 所获得的即时奖励
定义价值函数 $ V_{\pi}(s) $ 为从状态 $ s $ 出发,遵循策略 $ \pi $ 所获得的期望累计奖励:
$$ V_{\pi}(s) = \mathbb{E}[R(s, \pi(s)) + \gamma \cdot \sum_{s' \in S} T(s'|s, \pi(s)) \cdot V_{\pi}(s')] $$
其中 $ \gamma $ 是折扣因子,用于权衡当前奖励与未来奖励的重要性。
强化学习的目标是找到一个最优策略 $ \pi^* $,使得价值函数最大化。
2.2 算法分类
强化学习算法大致可分为三类:
- 基于价值的方法(Value-based methods):如 Q-learning、SARSA
- 基于策略的方法(Policy-based methods):如 REINFORCE、Actor-Critic
- 基于模型的方法(Model-based methods):如 Dyna 架构,结合了环境模型与策略学习
3. 最优控制
与强化学习不同,最优控制主要用于物理系统和工程系统的设计,目标是找到一个最优的控制输入,使得系统在固定时间内达到最佳性能。
通常,最优控制的目标是最小化一个代价函数(cost function),该函数通常由系统的状态和控制输入组成。
最优控制的系统结构如下图所示:
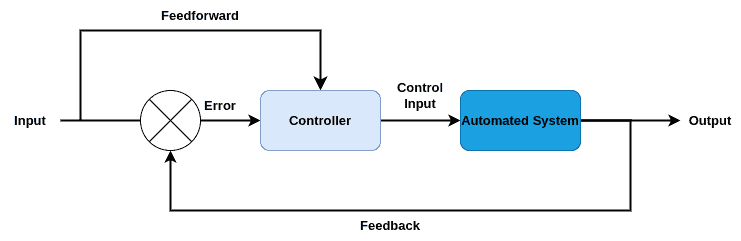
3.1 常见数学方法
常见的最优控制方法包括:
| 方法 | 说明 |
|---|---|
| 动态规划(Dynamic Programming, DP) | 适用于状态有限且系统动态已知的问题,通过递归求解子问题 |
| 庞特里亚金最小值原理(Pontryagin's Minimum Principle, PMP) | 利用哈密顿函数求解最优控制输入,适用于连续状态和控制问题 |
| 哈密顿-雅可比-贝尔曼方程(Hamilton-Jacobi-Bellman, HJB) | 使用偏微分方程求解价值函数,适用于连续状态和控制 |
这些方法都依赖于系统模型的精确数学描述,通常不涉及试错学习。
4. 核心区别
尽管强化学习和最优控制都致力于动态系统的最优决策,但它们之间存在几个关键区别:
| 维度 | 强化学习 | 最优控制 |
|---|---|---|
| 模型依赖 | 通常不依赖模型(model-free),也可以是 model-based | 依赖精确的系统模型 |
| 学习方式 | 试错交互,通过经验学习 | 数学推导,解析求解 |
| 奖励/代价函数 | 通常定义为奖励最大化 | 通常定义为代价最小化 |
| 应用领域 | 机器人、游戏、推荐系统等 | 航空航天、汽车控制、电力系统等 |
| 状态空间 | 可处理离散和连续状态,尤其适合复杂环境 | 更适合连续状态和已知模型的系统 |
5. 实际应用
5.1 强化学习应用
- ✅ 机器人:用于训练机械臂抓取、行走机器人控制等
- ✅ 游戏 AI:AlphaGo、星际争霸 AI 等
- ✅ 推荐系统:个性化内容推荐、广告投放优化
5.2 最优控制应用
- ✅ 航空航天:飞行器姿态控制、导航系统
- ✅ 汽车工程:自动驾驶路径规划、发动机控制
- ✅ 电力系统:电网调度、发电机组控制
6. 总结
本文对比了强化学习与最优控制的基本概念、数学建模方法、核心区别与典型应用场景。
- ✅ 强化学习 是一种基于试错的学习方法,适用于复杂、不确定性强的环境;
- ✅ 最优控制 是一种基于数学模型的解析方法,适用于系统模型已知、状态连续的工程问题。
在实际项目中,可以根据系统是否具有精确模型、是否需要在线学习、是否需要适应复杂环境等因素,选择合适的方法或结合使用两者。