1. 概述
词向量的表示有助于更好地分析文本语义。在某些任务中,例如词性标注(POS tagging),我们只需要单个词的向量表示即可。但在其他任务中,例如主题建模和情感分析,我们需要整个句子的向量表示。
本文将介绍几种常见的句子向量构建方法:
- 基于词向量的句子表示方法:简单平均、加权平均、DAN(Deep Averaging Network)
- 可直接输出句子向量的方法:Doc2vec、SentenceBERT、Universal Sentence Encoder、BERT Embedding
2. 简单平均法(Simple Averaging)
最直接的方法是将句子中所有词的词向量进行平均,得到该句子的向量表示。
✅优点:实现简单,计算效率高
❌缺点:
- 忽略了词序信息,相当于一种“词袋模型”
- 所有词权重相同,对某些任务(如情感分析)不敏感
- 高频词可能导致信息稀释,影响表达准确性
示例代码如下:
public double[] averageWordVectors(List<double[]> wordVectors) {
int vectorSize = wordVectors.get(0).length;
double[] sentenceVector = new double[vectorSize];
for (double[] vector : wordVectors) {
for (int i = 0; i < vectorSize; i++) {
sentenceVector[i] += vector[i];
}
}
for (int i = 0; i < vectorSize; i++) {
sentenceVector[i] /= wordVectors.size();
}
return sentenceVector;
}
3. 加权平均法(Weighted Averaging)
为了解决简单平均的问题,我们可以为每个词赋予不同的权重。常见做法是使用 TF-IDF:
$$ W_{ij} = TF_{ij} \times \log \frac{N}{DF_i} $$
其中:
- $TF_{ij}$:词 i 在句子 j 中出现的次数
- $DF_i$:包含词 i 的句子数量
- $N$:总句子数
✅优点:缓解了简单平均中权重均等的问题
❌缺点:
- 依然忽略词序
- 无法捕捉词之间的依赖关系
- 丢失语义信息
4. 深度平均网络(Deep Averaging Network, DAN)
DAN 的结构如下图所示:
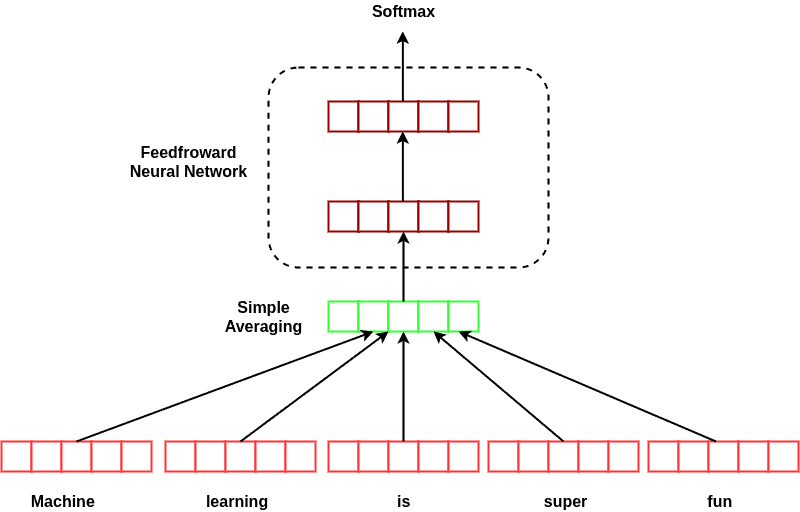
步骤:
- 对词向量做平均
- 输入一个前馈神经网络(可多层)
- 输出句子向量
⚠️注意:虽然 DAN 没有考虑词序,但其神经网络结构能捕捉句子中的语义信息。
✅优点:比简单平均效果好
✅优点:结构简单,训练快
❌缺点:不如基于序列模型(如 RNN)的效果好
5. Doc2vec(Paragraph Vector)
Doc2vec 是 Word2vec 的扩展,其训练目标是:根据前文和段落向量预测下一个词。
结构如下图所示:
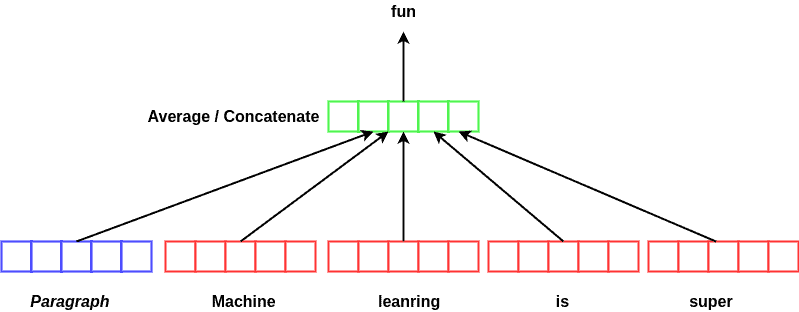
✅优点:
- 考虑了词序和句法信息
- 支持无监督训练,适合无标签数据
⚠️注意:训练成本略高于 DAN,但泛化能力更强。
6. SentenceBERT
SentenceBERT 是基于 BERT 的句子编码器,其结构如下图所示:
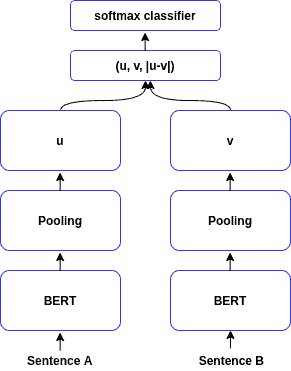
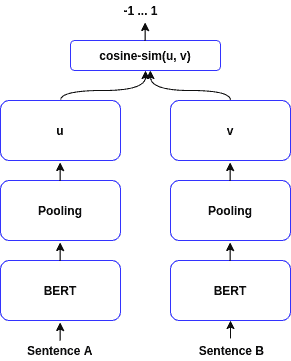
训练目标:
- 分类任务(如句子对相似度判断)
- 回归任务(如句子相似度打分)
✅优点:
- 支持句子级别的快速相似度计算
- 比原始 BERT 更高效(避免枚举所有句子对)
⚠️注意:SentenceBERT 是目前句子编码领域最流行的模型之一。
7. Universal Sentence Encoder(USE)
USE 是一种通用句子编码器,适用于多种任务(如情感分析、句子相似度)。
结构基于 Transformer 编码器:

✅优点:
- 支持多种下游任务
- 比 DAN 和词袋模型效果好
❌缺点:
- 计算复杂度为 O(n²),效率不如 SentenceBERT
⚠️注意:USE 的性能在某些任务上略逊于 SentenceBERT。
8. BERT Embedding
BERT 本身也可以用于提取句子表示。其输入结构如下图所示:
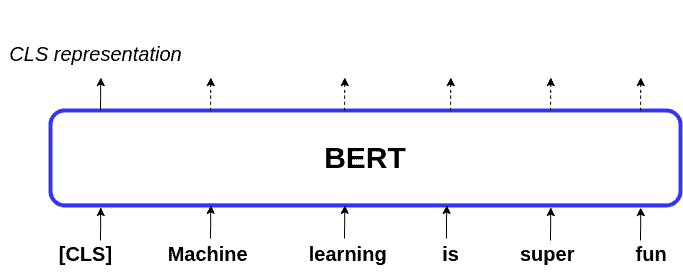
BERT 的输入中包含一个特殊的 [CLS] 标记,其输出可视为整个句子的表示。
获取方式:
- 使用
[CLS]的隐藏状态作为句子向量 - 对所有 token 的向量取平均
✅优点:
- 保留上下文信息
- 适合下游任务微调
⚠️注意:BERT 输出的句子向量不适用于直接比较,需配合 SentenceBERT 使用。
9. 总结
本文介绍了多种从词向量中获取句子向量的方法,包括:
| 方法 | 是否考虑词序 | 是否需训练 | 优点 | 缺点 |
|---|---|---|---|---|
| 简单平均 | ❌ | ❌ | 实现简单 | 忽略词序、权重均等 |
| 加权平均 | ❌ | ✅ | 提升语义表达 | 依赖 TF-IDF |
| DAN | ❌ | ✅ | 表达能力强 | 仍忽略词序 |
| Doc2vec | ✅ | ✅ | 支持无监督训练 | 训练成本高 |
| SentenceBERT | ✅ | ✅ | 效果好、效率高 | 模型大 |
| USE | ✅ | ✅ | 多任务通用 | 效率低 |
| BERT Embedding | ✅ | ✅ | 上下文强 | 不适合直接比较 |
✅推荐:
- 快速部署:SentenceBERT
- 无监督场景:Doc2vec 或 USE
- 简单任务:DAN 或加权平均
根据你的具体场景选择合适的句子编码方法,才能达到最佳效果。