1. 概述
在编程中,序列化(Serialization)与反序列化(Deserialization) 是两个非常核心的概念。它们允许我们将对象的状态以字节流的形式保存、传输,并在需要时重新构建对象。这些操作广泛应用于数据持久化、网络传输、缓存、分布式系统等多个场景。
本文将深入讲解这两个概念,帮助你理解它们的工作原理、使用方式以及需要注意的问题。
2. 什么是序列化
一个对象通常包含三个要素:身份(Identity)、状态(State)和行为(Behavior)。其中状态代表了对象的数据内容。
✅ 序列化就是将对象的状态转换为字节流的过程。这个字节流可以被保存到文件中、通过网络传输、或存储到数据库中。
通过序列化,我们可以将对象的“快照”持久化下来,以便在不同的上下文中重建该对象。
如下图所示,展示了对象序列化的基本流程:
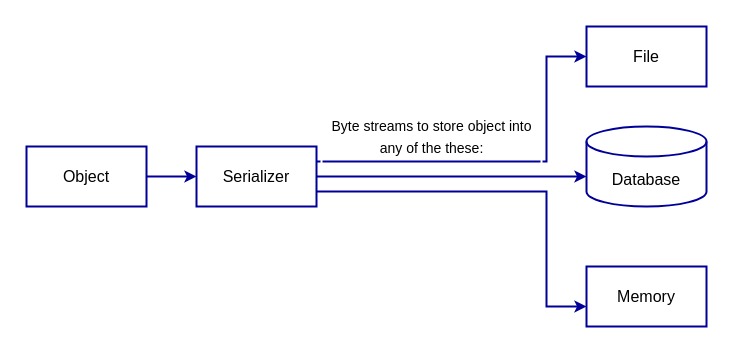
要实现序列化,程序员需要先选择一个合适的格式,再使用对应的工具将对象转换为该格式。
2.1 序列化格式
目前常见的序列化格式包括:
- ✅ JSON:结构清晰、可读性强,适合前后端通信
- ✅ XML:历史悠久,结构复杂,适合配置文件
- ✅ 二进制格式:如 Java 的
ObjectOutputStream,效率高但不可读 - ✅ Protobuf / Thrift / Avro:用于高性能 RPC 场景,支持跨语言
⚠️ JSON 和 XML 是文本格式,便于调试和查看;而二进制格式在性能上更优,但可读性差。
3. 什么是反序列化
✅ 反序列化是序列化的逆过程。它是指将字节流还原为对象的过程。
Java 中可以使用 ObjectInputStream 来反序列化二进制数据;对于 JSON 格式,推荐使用 Jackson 这样的库来处理。
下图展示了反序列化的过程:
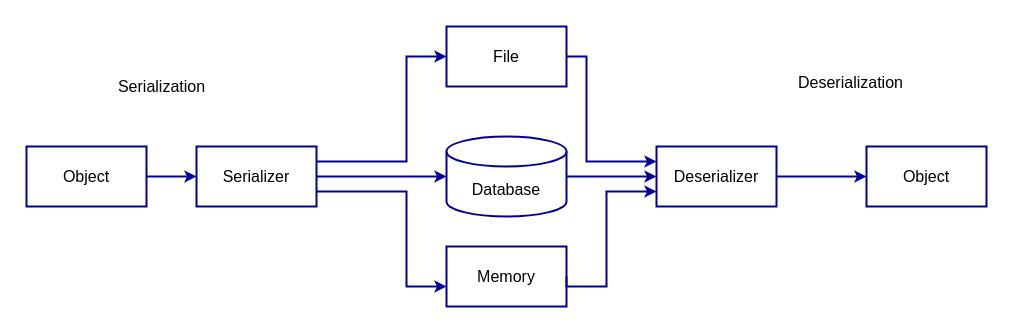
4. 应用场景:存储与传输
序列化与反序列化在实际开发中应用广泛,主要体现在两个方面:
4.1 数据存储
- 将对象状态保存到数据库中(如用户会话、配置信息)
- 对象缓存(如使用 Redis 缓存 Java 对象)
4.2 网络传输
- 分布式系统中节点间通信(如 RPC 调用)
- Web 应用前后端数据交互(如 REST API 使用 JSON 传输对象)
✅ 举个例子:用户在 Web 应用中保存了一个文档,系统需要将文档对象序列化后存入数据库。当用户再次打开文档时,系统从数据库中读取字节流并进行反序列化,重建文档对象并展示给用户。
5. 注意事项与潜在问题
尽管序列化和反序列化功能强大,但在使用过程中也存在一些需要注意的地方。
5.1 性能问题
- 大对象或复杂结构的序列化/反序列化会消耗较多 CPU 和内存资源
- 二进制格式虽然快,但 JSON 等文本格式在大对象时效率较低
5.2 平台与语言依赖性
- 不同语言或平台对同一数据结构的序列化结果可能不同
- 跨语言通信时需选择通用格式(如 JSON、Protobuf)
5.3 版本控制问题
- 如果对象结构发生变化(如新增字段、修改字段类型),旧版本系统可能无法正确反序列化新数据
- 建议使用支持版本兼容的序列化方案(如 Avro、Thrift)
5.4 不可序列化的对象
- 有些对象包含不能被序列化的资源,如文件句柄、网络连接、线程等
- 在 Java 中,未实现
Serializable接口的类不能直接序列化
5.5 安全风险
⚠️ 反序列化操作存在潜在安全风险。攻击者可能通过构造恶意输入,触发反序列化漏洞,从而执行任意代码。
✅ 推荐做法:
- 使用经过验证的序列化库(如 Jackson、Gson)
- 只反序列化来自可信源的数据
- 对敏感数据进行加密或签名处理
5.6 可读性差
- 二进制序列化数据通常不可读,不利于调试和日志分析
- 文本格式如 JSON 可读性好,但在复杂对象中仍可能难以理解
6. 总结
本文详细介绍了序列化与反序列化的概念、实现方式、应用场景以及需要注意的问题。
✅ 关键点总结如下:
| 内容 | 说明 |
|---|---|
| 序列化 | 将对象状态转换为字节流 |
| 反序列化 | 将字节流还原为对象 |
| 常见格式 | JSON、XML、二进制、Protobuf 等 |
| 应用场景 | 数据存储、网络传输、缓存、分布式系统 |
| 注意事项 | 性能、版本控制、安全风险、平台依赖性 |
✅ 建议:
- 优先选择 JSON 等通用格式
- 使用成熟库如 Jackson、Gson
- 避免对不可控来源的数据进行反序列化
如果你在开发中遇到对象传输、缓存、跨平台通信等需求,合理使用序列化与反序列化机制,将大大提升开发效率和系统稳定性。