1. 引言
在机器学习领域,SGD(Stochastic Gradient Descent,随机梯度下降) 和 BP(Backpropagation,反向传播) 经常被混淆。甚至一些从业者也会错误地使用这两个术语,进一步加剧了理解上的混乱。
简单来说:
✅ SGD 是一种优化算法,用于更新模型参数以最小化损失函数。BP 则是一种用于高效计算这些梯度的方法。
本文将从基础讲起,帮助你理清两者之间的关系和各自职责。
2. 梯度下降法(Gradient Descent)
GD 是一种优化算法,通过迭代更新输入参数来最小化目标函数。
理解 GD 对掌握 SGD 非常有帮助,原因有二:
- SGD 和 GD 的算法结构非常相似;
- SGD 的出现正是为了解决 GD 在大规模数据下的效率问题。
2.1 GD 的公式
考虑一个目标函数 $ f(\mathbf{x}) $,其中输入为 $ N $ 个变量:
$$
\mathbf{x} = {x_1, x_2, \cdots, x_N }
$$
GD 从一个初始点 $ \mathbf{a} $ 开始,计算该点的梯度:
$$ \nabla f(\mathbf{a}) = \left[ \frac{ \partial f(\mathbf{a}) }{ \partial a_1}, \frac{ \partial f(\mathbf{a}) }{ \partial a_2}, \cdots, \frac{ \partial f(\mathbf{a}) }{ \partial a_N} \right] $$
然后,根据梯度方向更新参数:
$$ \mathbf{a}_{n+1} = \mathbf{a}_n - \gamma_n \nabla f(\mathbf{a}_n) $$
其中,$\gamma_n$ 是学习率(learning rate),控制每次更新的步长。
⚠️ 注意:如果 $\gamma$ 太大,可能导致算法震荡甚至发散;太小则收敛速度慢。选择合适的学习率是关键。
2.2 GD 的局限性
GD 的主要问题是:每次迭代都需要计算整个数据集的梯度,这在数据量大、参数多的情况下非常耗时。
这就引出了我们今天的主角:SGD。
3. 随机梯度下降(Stochastic Gradient Descent)
SGD 是 GD 的一种改进版本,适用于大规模数据集和复杂模型。
3.1 数据的底层分布(Underlying Distribution)
现实世界的数据是由复杂的数据生成过程产生的。我们通常无法直接观察到这些过程,但可以通过数据来近似它们的概率分布。
例如,MNIST 数据集包含了 70,000 张手写数字图像,每张是 28×28 像素。这些图像可以看作是某种“手写数字生成过程”的样本。
我们训练模型的目标是:从这些样本中提取出底层结构(特征)。
但数据本身是带有噪声的,因此模型的性能也受限于数据质量。
3.2 SGD 的公式
假设我们有一个数据集 $ S = {\mathbf{s}_1, \mathbf{s}_2, \cdots , \mathbf{s}_N } $,以及一个预测模型 $ Q(\mathbf{s}, \mathbf{w}) $,其中 $ \mathbf{w} $ 是模型参数。
我们定义一个成本函数(cost function)来衡量模型输出 $ \hat{y} $ 和真实值 $ y $ 的差异,例如均方误差(MSE):
$$ C(S,\mathbf{w}) = \frac{1}{N} \sum_{i=1}^N \left( \mathbf{\hat{y}}_i - \mathbf{y}_i \right)^2 $$
GD 会使用整个数据集来计算梯度,而 SGD 每次只使用一个样本:
$$ \mathbf{w}_{n+1} = \mathbf{w}_n - \gamma_n \nabla C(\mathbf{s}_i, \mathbf{w}_n) $$
✅ 优点:每次更新更快,适合大数据集。
❌ 缺点:由于每次使用的是一个样本,梯度估计有噪声,训练过程会更波动。
4. 反向传播(Backpropagation)
BP 是 SGD 的“好搭档”。它负责高效地计算梯度。
4.1 BP 的作用
在神经网络中,每个参数都会影响后续层的输出。因此,计算梯度时需要使用链式法则(chain rule)。
如果每个参数单独计算梯度,计算量将指数级增长。BP 利用动态规划思想,从输出层反向计算梯度,逐层复用中间结果,使计算复杂度线性增长。
4.2 BP 的效率优势
下图展示了 BP 与朴素方法在单次更新中的时间对比:
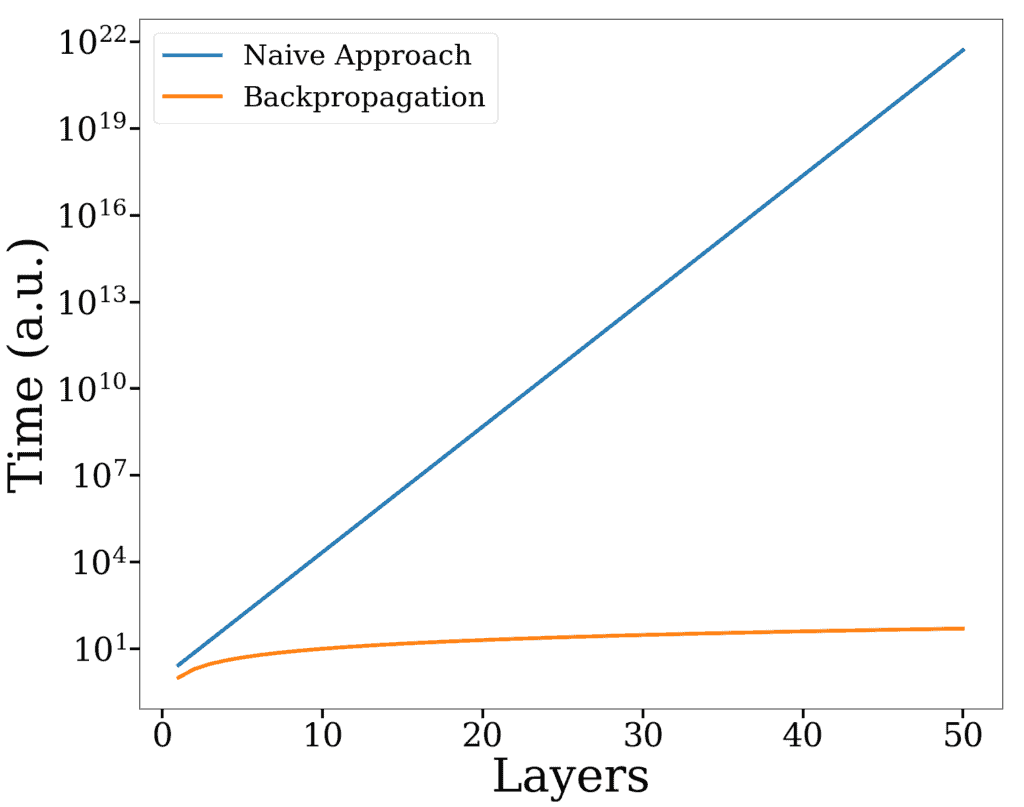
对于一个 20 层的网络,BP 比朴素方法快约 2400 万倍。
✅ 关键点:BP 只是计算梯度的一种方式,不是优化算法本身。
5. 总结
- ✅ SGD 是优化算法,用于更新模型参数以最小化损失函数。
- ✅ BP 是计算梯度的方法,是 SGD 在训练神经网络时的重要工具。
- ❌ 常见误解:很多人说“用 BP 训练了模型”,其实应理解为“用 SGD 训练模型,并用 BP 来计算梯度”。
理解这两者的区别和协作关系,有助于你在构建和调优模型时做出更明智的选择。