1. 概述
本文将深入探讨神经网络中常用的两个激活函数:Sigmoid 和 Tanh。我们将介绍它们的基本特性、数学表达式、图像表现、梯度行为,以及在实际神经元中的应用。最后还会给出在 Python 中的实现示例。
对于有经验的开发者来说,激活函数的基础概念可能已经耳熟能详。因此,我们不会在最基础的部分过多展开,而是聚焦于这两个函数之间的异同、优劣,以及它们在训练过程中的实际影响。
2. 激活函数简介
神经网络的核心组成部分之一是激活函数(Activation Function),它决定了一个神经元是否被激活。
在前馈神经网络中,一个神经元的输出值通常由如下公式计算:
$$ Y = \sum_{i=1}^m (x_i \cdot w_i) + b $$
其中:
- $ x_i $ 是输入特征
- $ w_i $ 是对应的权重
- $ b $ 是偏置项
然后,激活函数 $ f $ 作用于这个值,决定神经元的输出:
$$ \text{output} = f(Y) $$
如下图所示,激活函数在神经元结构中起到非线性变换的作用:
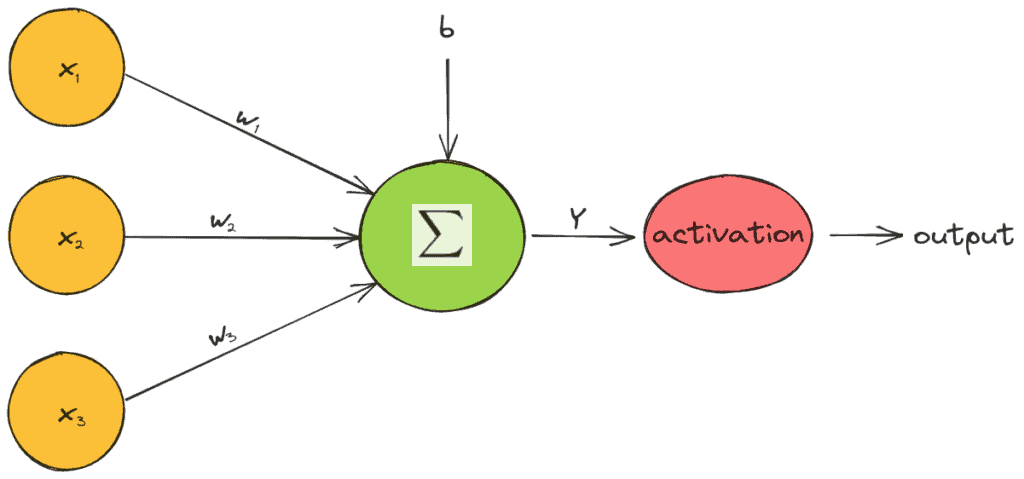
激活函数通常是单变量且非线性的。如果使用线性激活函数,整个网络等价于一个线性回归模型。而通过引入非线性激活函数,神经网络才能学习到复杂的语义结构并取得优异的性能。
3. Sigmoid 函数
**Sigmoid 函数(也称为 Logistic 函数)是一个非线性激活函数,其输入为任意实数,输出范围为 (0, 1)**。其数学表达式如下:
$$ s(x) = \frac{1}{1 + e^{-x}} $$
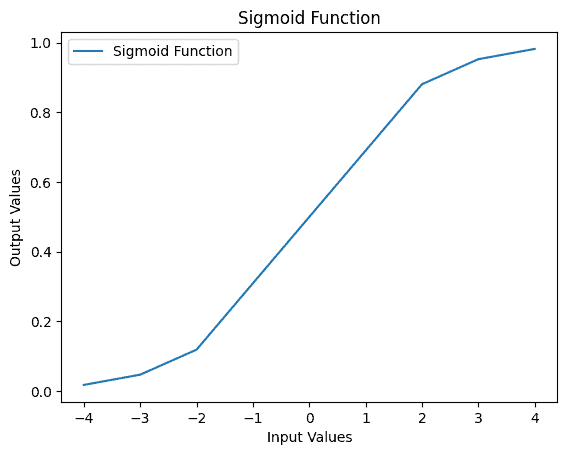
当输入范围为 [-10, 10] 时,Sigmoid 函数的图像如下:
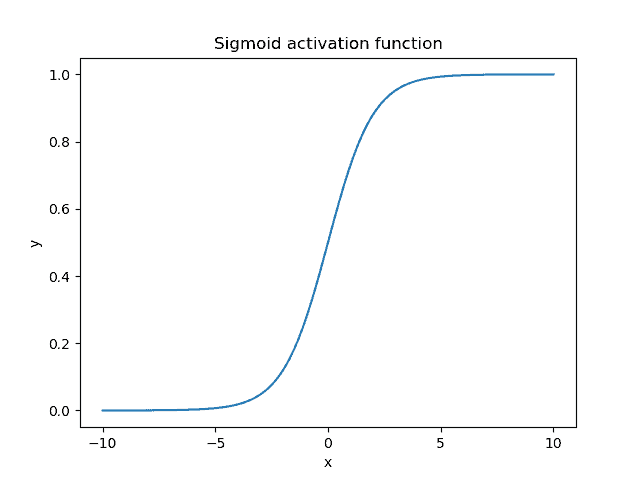
主要特点:
- 输出范围为 (0, 1),适合表示概率值
- S 形曲线特性使得输入值在接近 0 时变化敏感,远离 0 时趋于饱和
- 当输入小于 -5 时输出几乎为 0,大于 5 时几乎为 1
- 常用于输出层(如二分类问题)
缺点:
- 梯度消失问题:当输入值较大或较小时,梯度接近于 0,导致反向传播更新缓慢
- 输出非零中心化(non-zero-centered),可能影响收敛速度
4. Tanh 函数
**Tanh(双曲正切)函数是另一个广泛使用的激活函数,其输入为任意实数,输出范围为 (-1, 1)**。其数学表达式如下:
$$ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} = 2 \cdot \text{sigmoid}(2x) - 1 $$
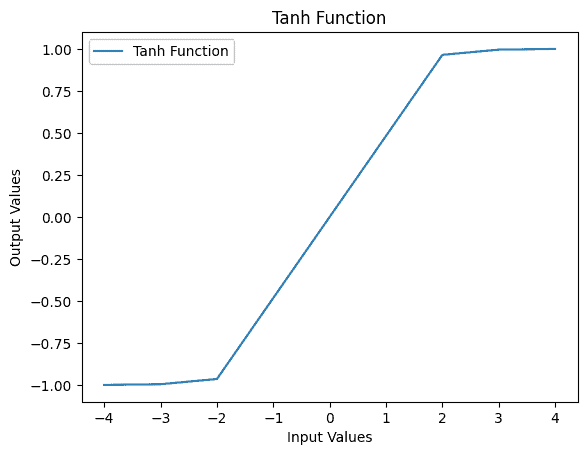
当输入范围为 [-10, 10] 时,Tanh 函数的图像如下:
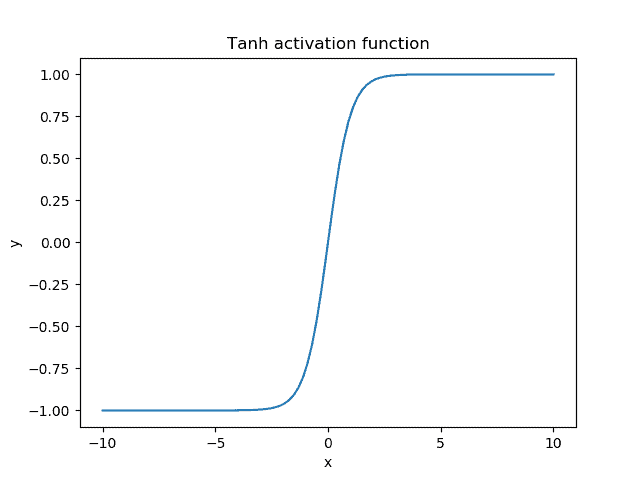
主要特点:
- 输出范围为 (-1, 1),具有对称性
- 相比 Sigmoid,Tanh 的输出是零中心化的,有助于加快训练过程
- 梯度更大,训练时更新更明显
缺点:
- 同样存在梯度消失问题
- 输出值范围更广,可能导致数值不稳定
5. 对比分析
✅ 相同点
| 特性 | Sigmoid | Tanh |
|---|---|---|
| 非线性 | ✅ | ✅ |
| 输出范围 | (0, 1) | (-1, 1) |
| S 形曲线 | ✅ | ✅ |
| 梯度消失问题 | ✅ | ✅ |
| 适用于多层网络 | ✅ | ✅ |
两者都属于 S 型函数,能将输入压缩到一个有界区间,有助于防止梯度爆炸(Exploding Gradient)。
❌ 不同点
| 特性 | Sigmoid | Tanh |
|---|---|---|
| 输出中心化 | ❌ | ✅ |
| 梯度大小 | 小 | 更大(约为 Sigmoid 的 4 倍) |
| 收敛速度 | 较慢 | 更快 |
| 输出解释 | 可解释为概率 | 无明确概率意义 |
梯度对比
Sigmoid 的导数:
$$ s'(x) = s(x) \cdot (1 - s(x)) $$
Tanh 的导数:
$$ \tanh'(x) = 1 - \tanh^2(x) $$
下图展示了两者导数的图像(红:Sigmoid,蓝:Tanh):
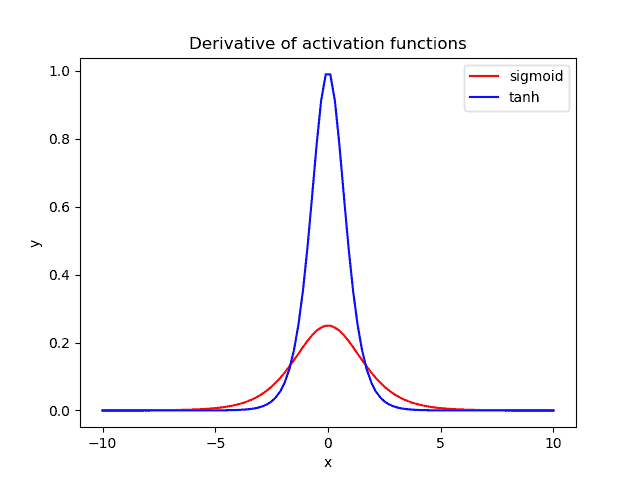
可以看到,Tanh 的梯度在中间区域明显更大,这意味着在训练过程中权重更新会更显著。
6. 梯度消失问题(Vanishing Gradient)
尽管 Sigmoid 和 Tanh 曾广泛使用,但它们都存在一个致命缺陷:梯度消失问题。
在深度神经网络中,误差通过反向传播层层传递。如果每一层的激活函数梯度都很小,误差在反向传播时会迅速衰减,导致靠近输入层的权重几乎无法更新。
这就是为什么 ReLU(及其变体)逐渐取代 Sigmoid 和 Tanh 成为现代深度学习主流激活函数的原因。
7. 示例对比
考虑一个简单的神经元,输入为:
- $ x_1 = 0.1 $, $ x_2 = 0.4 $
- 权重为:$ w_1 = 0.5 $, $ w_2 = -0.5 $
计算其输出值:
$$ Y = x_1 \cdot w_1 + x_2 \cdot w_2 = 0.1 \cdot 0.5 + 0.4 \cdot (-0.5) = 0.05 - 0.2 = -0.15 $$
分别使用 Sigmoid 和 Tanh 函数计算输出和梯度:
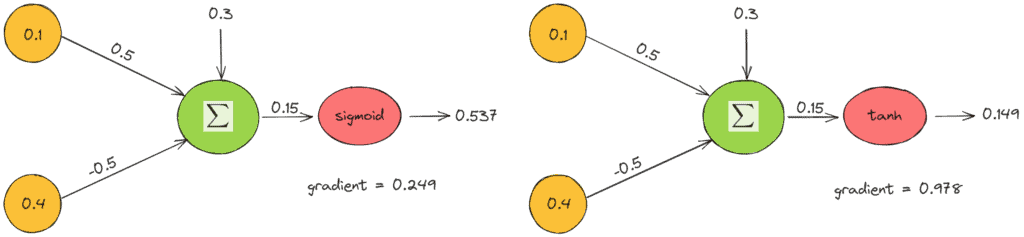
结论:
- Tanh 的输出更接近 0
- Tanh 的梯度是 Sigmoid 的 4 倍,意味着更新更强烈
8. Python 实现
8.1 Sigmoid 函数实现
使用 math 模块:
import math
def sigm(x):
return 1 / (1 + math.exp(-x))
使用 numpy:
import numpy as np
def sigm(x):
return 1 / (1 + np.exp(-x))
使用 scipy:
from scipy.special import expit
def sigm(x):
return expit(x)
示例输出:
Input: -4, Output: 0.01798620996209156
Input: -3, Output: 0.04742587317756678
Input: -2, Output: 0.11920292202211755
Input: 0, Output: 0.5
Input: 2, Output: 0.8807970779778823
Input: 3, Output: 0.9525741268224334
Input: 4, Output: 0.9820137900379085
可视化:
import matplotlib.pyplot as plt
ip = [-4, -3, -2, 0, 2, 3, 4]
op = [sigm(i) for i in ip]
plt.plot(ip, op, label='Sigmoid Function')
plt.xlabel('Input Values')
plt.ylabel('Output Values')
plt.title('Sigmoid Function')
plt.legend()
plt.show()
输出图像如下:
8.2 Tanh 函数实现
使用 math 模块:
import math
def tanh(x):
return (math.exp(x) - math.exp(-x)) / (math.exp(x) + math.exp(-x))
使用 numpy:
import numpy as np
def tanh(x):
return np.tanh(x)
使用 scipy:
from scipy.special import tanh
def tanh(x):
return tanh(x)
示例输出:
Input: -4, Output: -0.9993292997390669
Input: -3, Output: -0.9950547536867306
Input: -2, Output: -0.964027580075817
Input: 0, Output: 0.0
Input: 2, Output: 0.964027580075817
Input: 3, Output: 0.9950547536867306
Input: 4, Output: 0.9993292997390669
可视化:
ip = [-4, -3, -2, 0, 2, 3, 4]
op = [tanh(i) for i in ip]
plt.plot(ip, op, label='Tanh Function')
plt.xlabel('Input Values')
plt.ylabel('Output Values')
plt.title('Tanh Function')
plt.legend()
plt.show()
输出图像如下:
9. 总结
| 对比项 | Sigmoid | Tanh |
|---|---|---|
| 输出范围 | (0, 1) | (-1, 1) |
| 是否零中心化 | ❌ | ✅ |
| 梯度大小 | 小 | 大(约 4 倍) |
| 收敛速度 | 较慢 | 更快 |
| 是否有概率意义 | ✅ | ❌ |
| 是否存在梯度消失 | ✅ | ✅ |
✅ 推荐使用场景:
- Sigmoid:输出层(特别是二分类)
- Tanh:隐藏层(尤其在早期网络中)
⚠️ 注意事项:
- 在现代深度学习中,ReLU 及其变体(如 Leaky ReLU、Swish)更受欢迎,因其能缓解梯度消失问题
- 如果使用 Sigmoid 或 Tanh,建议使用合适的初始化方法(如 Xavier)以避免训练困难
希望这篇文章能帮助你更好地理解 Sigmoid 和 Tanh 激活函数的本质和适用场景。如有任何疑问或补充,欢迎留言交流!