1. 引言
在处理数据时,一个常见的任务是识别输入信号中的峰值(peak)。例如在电信号、地震波、风速等场景中,我们经常需要从数据流中找出显著的波峰。
本文将介绍几种常用的峰值检测方法,并探讨它们的适用场景与局限性。我们会从最简单的峰值检测开始,逐步深入到更复杂的噪声处理和宽峰识别技术。
2. 简单峰值检测
当我们面对一个信号数据流时,最直观的方法是直接找出最大值点。这种方法适用于背景值稳定、峰值非常突出的场景。
例如下图中,峰值出现在时间点18,非常容易识别:
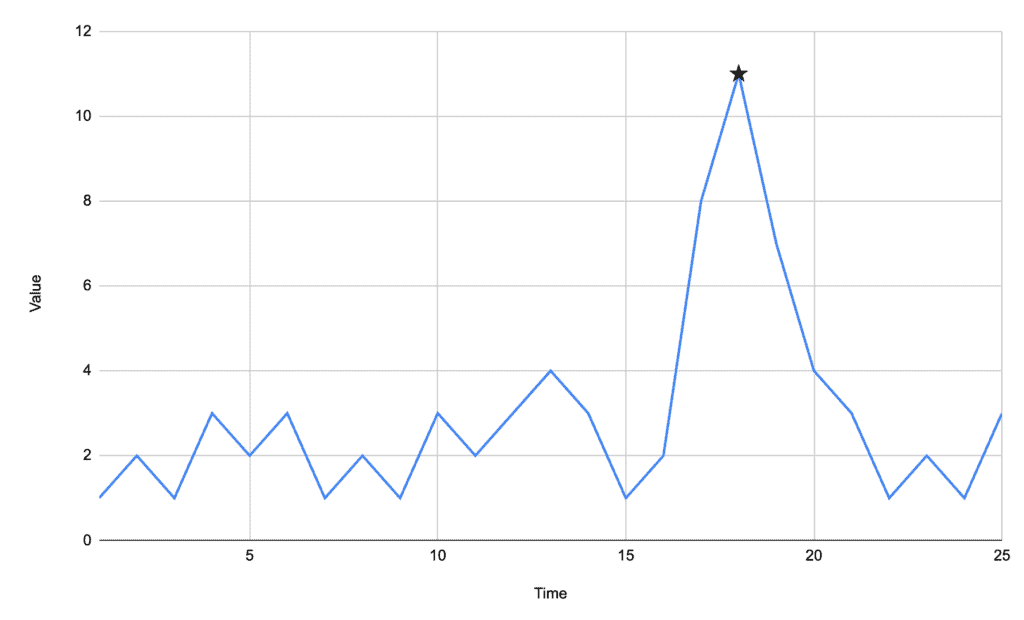
2.1. 算法实现
该算法非常简单:遍历整个信号数组,记录当前最大值及其索引。遍历完成后返回最大值的索引即可。
algorithm NaivePeakFinding(signal):
// INPUT
// signal = an array of signal values
// OUTPUT
// index = the index of the peak value in the signal
peakIndex <- null
peakValue <- null
for index, value in signal:
if peakValue = null or value > peakValue:
peakIndex <- index
peakValue <- value
return peakIndex
✅ 优点:实现简单,效率高
❌ 缺点:仅适用于单个显著峰值,无法处理多个或噪声干扰下的峰值
3. 多峰值检测 – 使用基线法
上述方法只能找到一个最大值。如果我们希望识别多个峰值,比如下面这个信号:
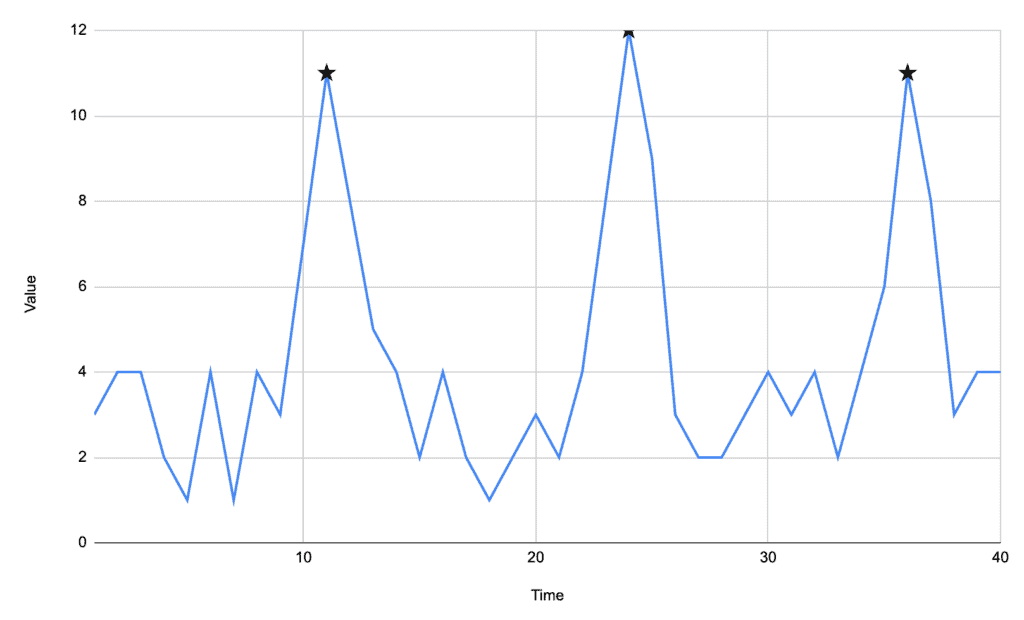
信号中有三个明显峰值,但简单方法只能找到最大值所在的24时刻。
此时,我们可以通过设定一个“基线”(baseline)来识别多个峰值。当信号值高于基线时,记录当前最大值;当信号值低于基线时,说明当前峰值结束,可以将其加入结果并重置。
3.1. 算法实现
algorithm MultiplePeakFinding(signal):
// INPUT
// signal = an array of signal values
// OUTPUT
// indices = an array of indices of the peak values in the signal
peakIndices <- an empty array
peakIndex <- null
peakValue <- null
baseline <- average(signal)
for index, value in signal:
if value > baseline:
if peakValue = null or value > peakValue:
peakIndex <- index
peakValue <- value
else if value < baseline and peakIndex != null:
peakIndices.append(peakIndex)
peakIndex <- null
peakValue <- null
if peakIndex != null:
peakIndices.append(peakIndex)
return peakIndices
✅ 优点:可识别多个峰值
⚠️ 注意:基线设置对结果影响较大,需根据信号特点调整
4. 噪声信号处理
当信号中存在较大噪声时,简单的基线法可能产生大量误判。例如下图中的信号:
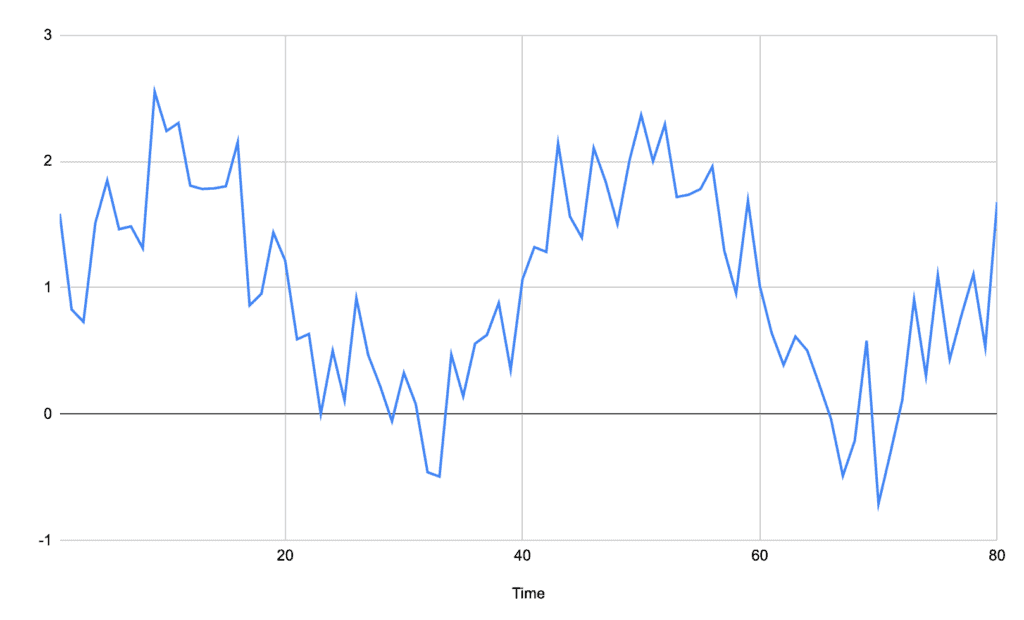
如果直接使用平均基线,会识别出7个峰值,而实际我们期望只有2个。
4.1. 解决方案:移动平均
为了减少噪声影响,我们可以使用移动平均(moving average)来平滑信号。例如,对每个点取其前后两个点的平均值进行处理:
处理后信号如下图所示,峰值更清晰:
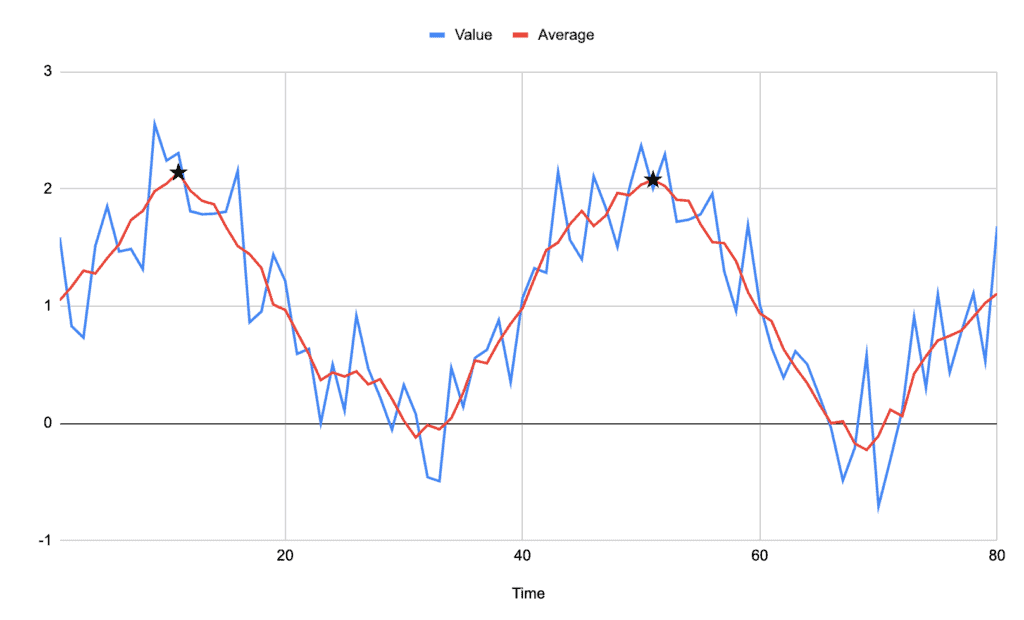
4.2. 算法实现
algorithm NoisyPeakFinding(signal):
// INPUT
// signal = an array of signal values
// OUTPUT
// indices = an array of indices of the peak values in the signal
smoothed <- []
for index in signal:
smoothed.append(average(signal[index-2 : index + 2]))
peakIndices <- an empty array
peakIndex <- null
peakValue <- null
baseline <- average(smoothed)
for index, value in smoothed:
if value > baseline:
if peakValue = null or value > peakValue:
peakIndex <- index
peakValue <- value
else if value < baseline and peakIndex != null:
peakIndices.append(peakIndex)
peakIndex <- null
peakValue <- null
if peakIndex != null:
peakIndices.append(peakIndex)
return peakIndices
✅ 优点:能有效抑制噪声干扰
⚠️ 注意:移动窗口大小需根据信号特征调整
5. 宽峰识别
有时我们希望识别的不是一个点,而是一段连续的高值区域。例如下面这个信号:
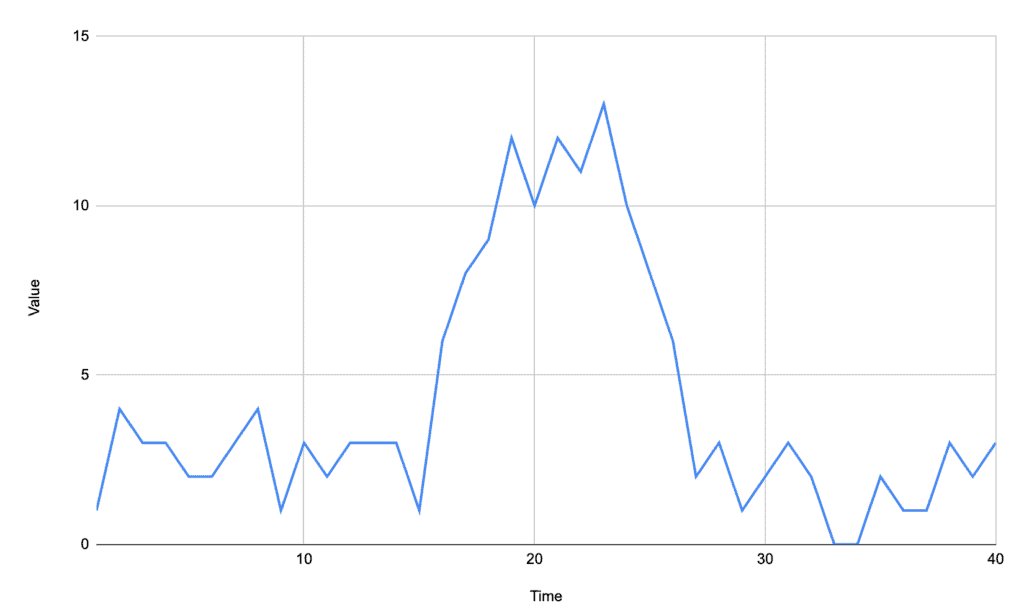
该信号中存在一个明显的“高值区域”,而不是单一峰值。我们希望将整个区域识别为一个“宽峰”。
5.1. 实现思路
不再寻找单一最大值,而是将所有高于基线的点都标记为峰值区域的一部分。
5.2. 算法实现
algorithm WidePeakFinding(signal):
// INPUT
// signal = an array of signal values
// OUTPUT
// indices = an array of indices that are part of a wide peak in the signal
peakIndices <- an empty array
baseline <- average(signal)
for index, value in signal:
if value > baseline:
peakIndices.append(index)
return peakIndices
✅ 优点:适合识别“宽峰”或信号“开启”区域
⚠️ 注意:需要后续处理将连续索引分组为独立峰值
6. 基于标准差的峰值检测
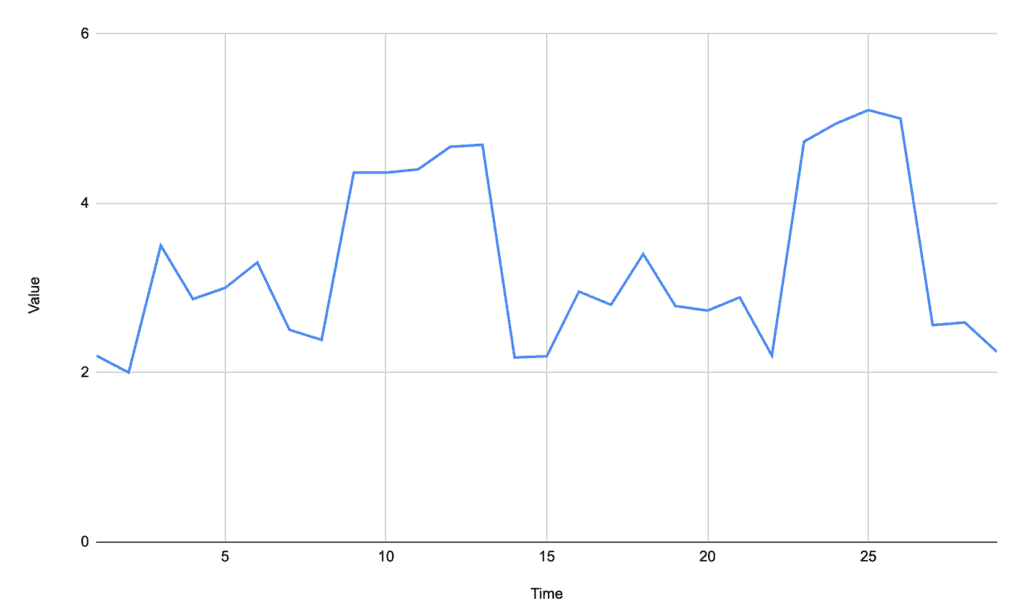
当信号中存在多个波动但只有少数几个是显著异常时,使用标准差(standard deviation)可以更精确地识别出“异常”峰值。
例如下图中,我们希望识别出两个显著高峰,而不是所有高于基线的小峰:
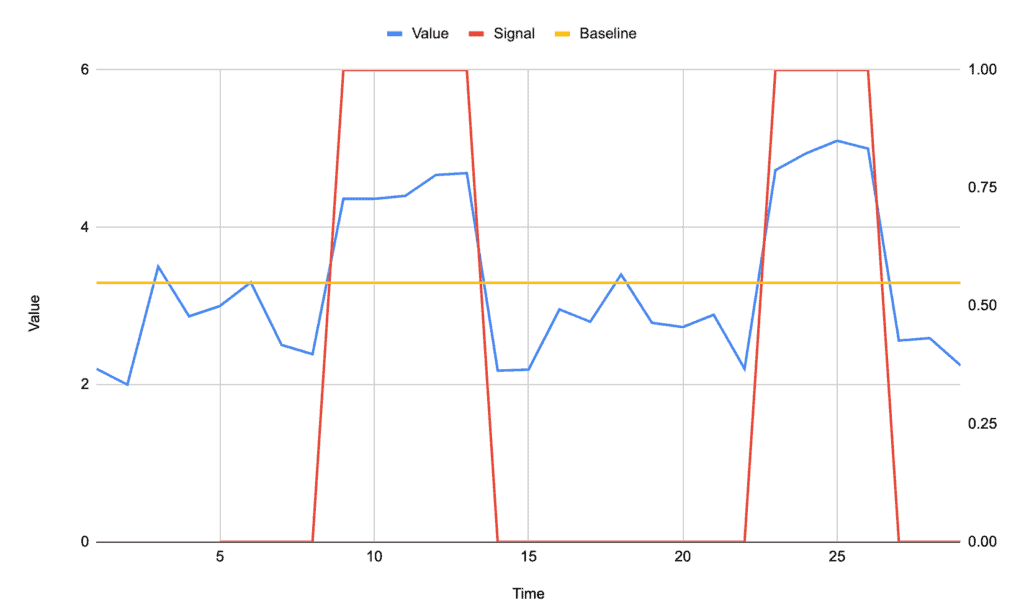
使用标准差后,我们只识别出这两个显著峰值:
6.1. 算法实现
algorithm Dispersion(signal, lag, influence, threshold):
// INPUT
// signal = an array of signal values
// lag = the number of values to consider for the moving average
// influence = the influence of a peak on the moving average
// threshold = the standard deviation multiplier for peak detection
// OUTPUT
// indices = an array of indices considered to be peaks based on dispersion
peakIndices <- an empty array
processedSignal <- signal[0 : lag]
for index <- lag to length(signal):
y <- signal[index]
avg <- average(processedSignal[(index-lag) : index])
sd <- stdev(processedSignal[(index-lag) : index])
if y - avg > sd * threshold:
peakIndices.push(index)
adjustedValue <- (influence * y) + ((1 - influence) * processedSignal[index - 1])
else:
processedSignal.push(y)
return peakIndices
参数说明:
lag:用于计算移动平均的前N个点数threshold:标准差倍数,决定多少才算异常influence:异常点对后续移动平均的影响程度(0~1)
✅ 优点:能识别显著异常峰值,对噪声有较好鲁棒性
⚠️ 注意:参数敏感,需根据数据特征调整
7. 总结
本文介绍了几种常见的信号峰值检测方法:
| 方法 | 适用场景 | 特点 |
|---|---|---|
| 简单最大值法 | 单个显著峰值 | 简单高效 |
| 基线法 | 多个峰值识别 | 需合理设置基线 |
| 移动平均 | 噪声信号处理 | 可平滑信号 |
| 宽峰识别 | 区域性高值 | 适合“开启”检测 |
| 标准差法 | 异常峰值识别 | 精度高,参数敏感 |
在实际应用中,应根据信号特性、噪声水平和业务需求选择合适的算法,必要时结合多种方法进行优化。
✅ 建议:对于复杂信号,建议先做可视化分析,再选择算法,避免“踩坑”。