1. 引言
在本篇文章中,我们将深入探讨内部排序(Internal Sorting)与外部排序(External Sorting)之间的区别,以及各自适用的场景和常用算法。
2. 内部排序与外部排序的核心区别
✅ 内部排序指的是所有待排序数据都能一次性加载到内存中进行排序的过程。这种排序方式适用于数据量较小、内存容量足够的情况。
❌ 外部排序则用于处理数据量远超内存容量的场景。此时,排序过程必须借助磁盘等外部存储介质,通过分块加载、排序、合并等步骤完成整个排序任务。
📌 两者的本质区别在于:是否完全依赖内存进行排序操作。
3. 内部排序常用算法
以下是一些常见的内部排序算法,适用于内存中可容纳的数据集。
3.1 冒泡排序(Bubble Sort)
冒泡排序是一种基础但效率较低的排序算法。其核心思想是:
- 依次比较相邻元素
- 若顺序错误则交换位置
- 重复遍历数组直到有序
它的时间复杂度为 O(n²),空间复杂度为 O(n)。
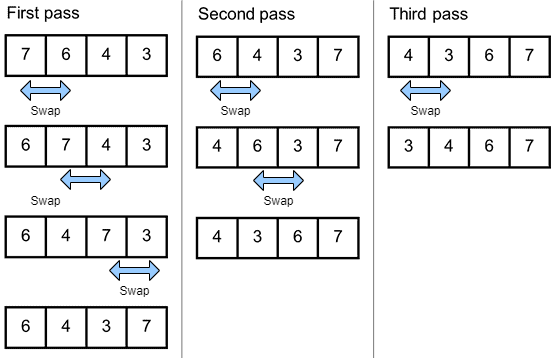
✅ 适合教学理解,不推荐用于实际生产环境。
3.2 插入排序(Insertion Sort)
插入排序模拟的是我们整理扑克牌的方式:
- 将数组分为“已排序”和“未排序”两部分
- 逐个将未排序元素插入到已排序部分的合适位置
时间复杂度 O(n²),空间复杂度 O(n)
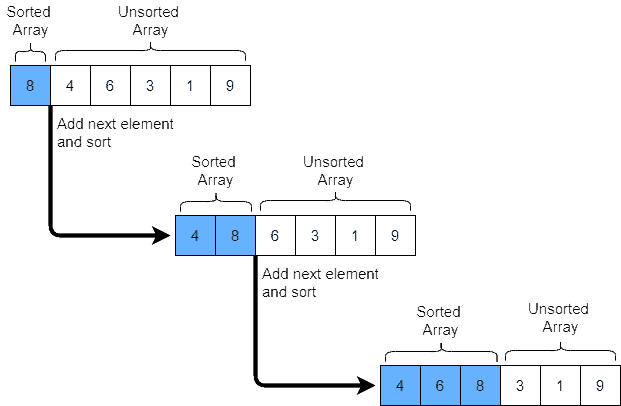
✅ 对小数据集效率尚可,适合近乎有序的数据。
3.3 快速排序(Quick Sort)
快速排序是一种典型的分治算法:
- 选择一个“基准”元素(pivot)
- 将数组划分为两部分:一部分小于 pivot,另一部分大于 pivot
- 对两部分递归执行上述过程
平均时间复杂度为 O(n log n),最差为 O(n²),空间复杂度为 O(n)
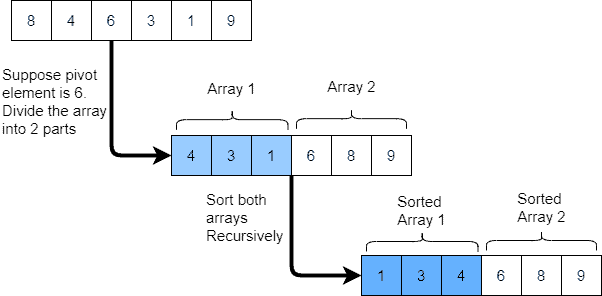
✅ 常用于实际系统中,效率高,实现简单。
4. 外部排序常用算法
外部排序适用于数据量巨大、无法全部加载到内存中的情况。其核心思想是:
- 分块排序(利用内部排序算法)
- 合并已排序的块
4.1 数据流图示
下图展示了一个使用 8GB 内存对 50GB 数据进行排序的流程:
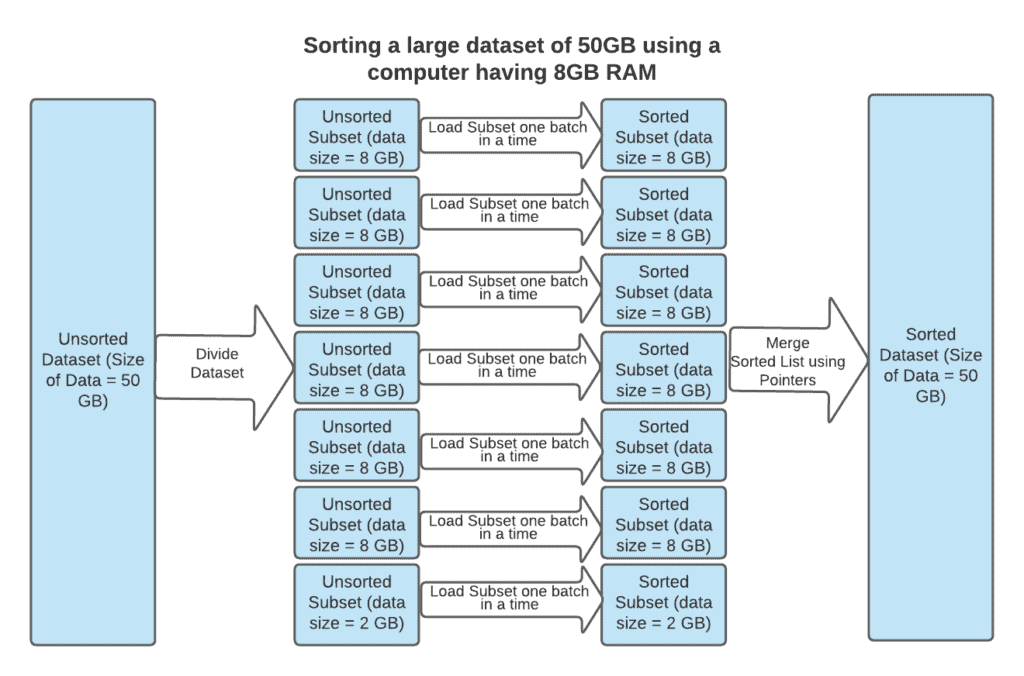
主要步骤如下:
- 分块读取:将数据按内存大小切分为若干小块
- 内部排序:对每个小块使用内部排序算法排序
- 归并排序:使用归并技术将多个有序块合并成一个完整有序数据集
💡 归并排序(Merge Sort)是外部排序中最常用的算法之一。其空间复杂度通常为 O(n),但可以通过优化使其归并过程空间复杂度降为 O(1)。
4.2 示例详解
我们以以下数据为例:
A S O R T I N G A N D M E R G I N G E X A M P L E
假设内存最多能容纳 10 个元素。
第一步:分块处理
将原始数据划分为 3 个子集:
- A S O R T I N G A N
- D M E R G I N G E X
- A M P L E
第二步:逐个排序
分别加载到内存中进行排序:
- A A G I N N O R S T
- D E E G G I M N R X
- A E L M P
第三步:归并排序
初始化三个指针分别指向每个子集头部,一个输出指针指向输出位置:
- 加载当前指针指向的元素(A、D、A)到内存
- 找出最小值 A,写入输出
- 移动该子集的指针和输出指针
- 重复上述过程,直到所有元素处理完毕
最终输出结果:
A A A D E E E G G G I I L M M N N N O P R R S T X
✅ 外部排序的关键在于合理利用内存 + 高效归并策略。
5. 总结
| 对比维度 | 内部排序 | 外部排序 |
|---|---|---|
| 数据规模 | 小,可全部加载到内存中 | 大,需借助外部存储 |
| 常用算法 | 冒泡、插入、快速排序 | 归并排序 |
| 空间复杂度 | O(n) | 可优化为 O(1) |
| 实现难度 | 简单 | 复杂,需考虑磁盘读写 |
| 应用场景 | 常规排序任务 | 大数据量排序(如日志处理) |
📌 内部排序适用于内存可容纳的数据,外部排序用于处理超出内存限制的大数据集。
踩坑提醒:在处理大数据量排序任务时,不要盲目使用快速排序等内部排序算法,否则可能导致内存溢出或性能急剧下降。建议优先考虑归并排序的外部实现方式。