1. 概述
本文介绍了在不同场景下可用于垃圾邮件检测的几种主要方法,并讨论了可用于构建英文及其他语言垃圾邮件识别系统的公开训练数据集。
2. 什么是垃圾邮件(Spam)?
如果一条消息是接收者不想要的,那它就被称为垃圾邮件。换句话说,没有哪条消息本质上就是垃圾邮件,它是否为垃圾邮件取决于接收者的态度。
这对我们构建垃圾邮件检测系统来说是个挑战:不同用户有不同的偏好,我们无法事先判断他们想接收哪些内容,又不想要哪些内容。举个例子说明一下:
常见的垃圾邮件类型包括:
- 推销药品
- 金融服务广告
- 成人内容
但如果用户:
- 正在寻找止痛药
- 想要贷款
- 对成人内容感兴趣
那么这些信息就不是垃圾邮件。
理论上,我们希望用户能明确表达他们的偏好,从而我们可以构建一个能准确过滤垃圾邮件的系统。我们假设这种情况已经发生,那接下来该如何构建一个垃圾邮件过滤器呢?
3. 垃圾邮件过滤的规则方法与统计方法
3.1. 规则方法(Rule-Based Approach)
有三种主要方法可以用于构建垃圾邮件识别系统。第一种是规则方法,它通过预设的正则表达式(RegEx)模式来判断是否为垃圾邮件:
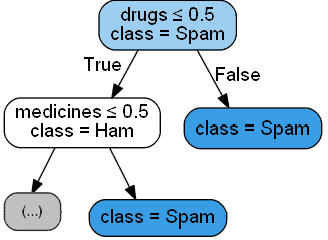
这些规则是由开发人员手动定义的,因此它们是静态且不可自动调整的。
✅ 适用场景:
- 多用户共享同一个垃圾邮件过滤器
- 规则可维护性要求不高
❌ 缺点:
- 随着规则数量增加,维护成本高
- 不易扩展
3.2. 统计方法(Statistical Approach)
第二种方法是统计方法,通常通过机器学习实现。
该方法需要从文本中提取特征(如关键词频率、出现模式等),并将其与垃圾邮件标签进行比对。机器学习算法就可以基于这些数据学习如何分类新消息。
例如,训练后的朴素贝叶斯分类器中,特征权重矩阵可能如下所示:
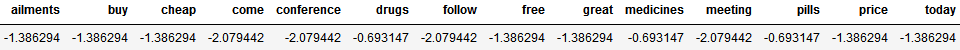
✅ 优点:
- 可扩展性强
- 能适应不同用户的偏好(通过再训练)
❌ 缺点:
- 需要大量标注数据
- 初期训练成本较高
3.3. 混合方法(Hybrid Approaches)
第三种方法是混合方法,结合了规则方法和统计方法的优点。
虽然在英文邮件中较少见,但在某些语言(如中文)中,混合方法表现更好。这是因为语言结构差异,某些语言更适合结合规则与统计。
⚠️ 注意:
- 构建多语言垃圾邮件过滤器时,一定要考虑语言本身的结构特性
- 不同语言可能需要不同的模型策略
4. 垃圾邮件检测可用的数据集
4.1. 用户偏好为何不能总是使用?
理想情况下,我们应使用用户自己标注的数据来训练垃圾邮件过滤器。这样可以最贴近用户的实际需求。
但现实中,我们很难一开始就获取这些数据,原因如下:
- 新用户需要时间接收并标记足够多的垃圾邮件
- 老用户不愿意手动标注历史邮件
✅ 结论:
- 用户偏好数据虽理想,但实践中难以快速获取
- 只能在用户持续使用过程中逐步收集
4.2. 公开可用的数据集
实际中更常见的是使用预训练的公开数据集来构建基础模型。以下是一些常见且广泛使用的英文垃圾邮件数据集:
| 数据集名称 | 描述 | 适用场景 |
|---|---|---|
| Spambase | UCI 提供的经典垃圾邮件数据集 | 初学者入门 |
| SMS Spam | 短信垃圾信息数据集 | 短文本分类 |
| SpamAssassin | 包含难度分级的垃圾邮件 | 测试模型鲁棒性 |
| Enron Spam | 包含完整邮件内容(含邮件头) | 特征工程训练 |
4.3. 其他语言的数据集
对于非英文语言,公开可用的垃圾邮件训练数据集相对较少。以下是一些可用资源:
阿拉伯语:
- Extended Arabic Web Spam 2011 Dataset
- ✅ 包含网页文本,可用于垃圾邮件特征提取
- ⚠️ 需自行标注
德语:
- CodE ALLTAG
- ✅ 包含大量匿名邮件
- ⚠️ 缺乏垃圾邮件标签,需手动或自动标注
意大利语:
- CORIS EPHEMERA
- ✅ 包含信件类文本
- ⚠️ 仅限研究使用,不可商用
法语:
- CoMeRe simuligne
- ✅ 包含正常邮件
- ⚠️ 缺少垃圾邮件样本,需补充数据
4.4. 专有数据集(Proprietary Datasets)
由于电子邮件包含敏感信息,大多数邮件数据集并不公开。以下是一些获取途径:
- 各大邮件服务商(如 Gmail、Outlook)拥有内部数据
- 可通过商业合作或科研合作获取访问权限
- 通常需签署协议并遵守数据使用规范
✅ 建议:
- 如果你是在企业内部开发垃圾邮件过滤系统,最好与数据团队合作获取内部邮件数据
- 注意数据脱敏与隐私保护
5. 总结
本文我们介绍了垃圾邮件过滤的三种主要方法:
✅ 规则方法:
- 适用于多用户共享场景
- 易于部署但扩展性差
✅ 统计方法:
- 更适合可扩展系统
- 需要大量标注数据训练
✅ 混合方法:
- 在非英文语言中更有效
- 需考虑语言结构差异
同时我们还介绍了常见的公开训练数据集,包括英文和其他语言的数据集,并分析了它们的特点和使用限制。
如果你正在开发一个垃圾邮件过滤系统,建议从公开数据集入手,构建基础模型后再结合用户反馈进行优化。