1. 引言
统计独立性是概率论和统计学中的一个核心概念。理解它对于数据分析、建模、实验设计等领域至关重要。本文将从基本定义出发,逐步讲解独立事件、多个事件的独立性、条件独立性以及随机变量的独立性,并通过示例帮助加深理解。
2. 为什么统计独立性重要?
在日常语言中,“独立”通常意味着“互不相关”。但在统计学中,它的定义更为精确:如果一个事件的发生不会改变另一个事件发生的概率,那么这两个事件就是统计独立的。
举个实际场景:假设你在开发一种疫苗,并想测试某种昂贵成分是否能提高保护率。你将受试者随机分为两组,一组使用含该成分的疫苗,另一组不含。如果两组的疾病发病率相同,那么“疫苗是否含该成分”和“是否受保护”这两个事件是统计独立的,说明该成分对效果没有影响,可以省去以降低成本。
3. 两个事件的统计独立性
统计上,事件 A 和 B 是独立的(记作 A ⊥ B),当且仅当它们的联合概率等于各自概率的乘积:
$$ P(A \cap B) = P(A) \times P(B) $$
✅ 举例说明:
- 若 $ P(A) = 0.5 $,$ P(B) = 0.7 $,则只有当 $ P(A \cap B) = 0.35 $ 时,A 和 B 才是独立的。
3.1 条件概率的解释
根据条件概率定义:
$$ P(A \cap B) = P(A \mid B) \times P(B) = P(B \mid A) \times P(A) $$
若 A 和 B 独立,则:
$$ P(A) = P(A \mid B), \quad P(B) = P(B \mid A) $$
这说明,知道 B 是否发生,并不会改变 A 发生的概率,反之亦然。
⚠️ 踩坑提示:很多人误以为“两个事件独立”就意味着它们之间没有任何联系。实际上,统计独立性是一个严格的数学定义,和日常语言中的“无关”不完全等价。
3.2 可视化理解
我们可以将事件 A 和 B 的概率关系用图形表示。如果 A 和 B 独立,那么 A ∩ B 在 B 中所占的比例应该等于 A 在整个样本空间中的比例。
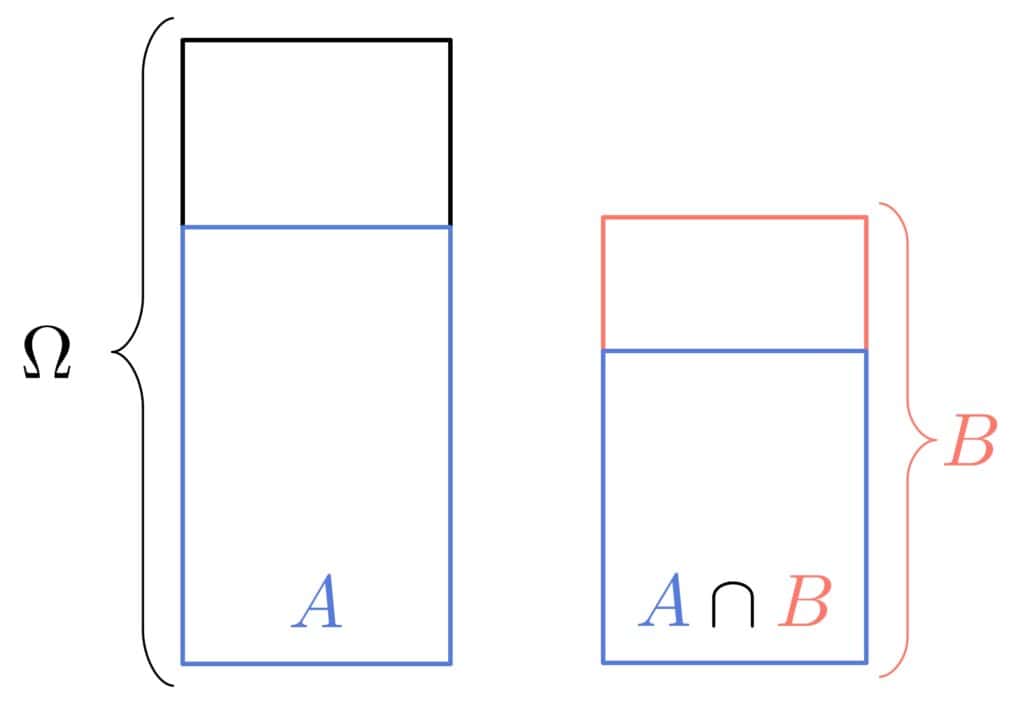
4. 多个事件的统计独立性
多个事件之间的独立性有两种形式:成对独立(pairwise independence)和互独立(mutual independence)。
4.1 成对独立(Pairwise Independence)
如果任意两个事件 A_i 和 A_j 都满足独立性条件(即 $ P(A_i \cap A_j) = P(A_i) \times P(A_j) $),那么这些事件是成对独立的。
📌 示例:
抛一枚公平硬币两次,样本空间为 {HH, HT, TH, TT}。
定义事件:
- A:第一次为正面
- B:第一次为反面
- C:两次结果相同
计算可得:
$$ P(A) = P(B) = P(C) = 0.5 $$ $$ P(A \cap B) = P(A \cap C) = P(B \cap C) = 0.25 $$
所以 A、B、C 是成对独立的。但:
$$ P(A \cap B \cap C) = 0 \neq 0.125 = P(A) \times P(B) \times P(C) $$
这说明它们不是互独立的。
4.2 互独立(Mutual Independence)
如果任意一个事件与任意其他事件的交集也满足独立性条件,那么这些事件是互独立的。
数学定义如下:
$$ \forall k \geq 2, \quad \forall {i_1, i_2, \ldots, i_k} \subseteq {1, 2, \ldots, n}, \quad P\left( \bigcap_{\ell=1}^k A_{i_\ell} \right) = \prod_{\ell=1}^k P(A_{i_\ell}) $$
✅ 互独立一定意味着成对独立,但成对独立不一定意味着互独立。
5. 条件独立性(Conditional Independence)
在给定某个事件 C 的条件下,两个事件 A 和 B 可能独立,这种独立性称为条件独立性。
定义如下:
$$ P(A \cap B \mid C) = P(A \mid C) \times P(B \mid C) $$
✅ 举例:
在医学诊断中,如果症状 A 和 B 在已知疾病 C 的前提下是独立的,那么知道 A 的发生不会提供关于 B 的额外信息。
📌 与统计独立性对比:
- 统计独立性:不考虑任何其他信息
- 条件独立性:在已知某些信息的前提下才独立
6. 随机变量的独立性
随机变量之间的独立性可以类比事件的独立性来定义。
两个随机变量 A 和 B 是独立的,当且仅当对于任意 a 和 b,事件 {A ≤ a} 和 {B ≤ b} 是独立的。
用分布函数表示:
设 F_A 和 F_B 分别为 A 和 B 的边缘分布函数,F_AB 为联合分布函数,则:
$$ F_{AB}(a, b) = F_A(a) \times F_B(b) $$
✅ 举例:
两个独立的正态分布变量的联合分布是二维正态分布,其协方差为 0。
7. 统计独立性 vs 日常语言中的独立性
日常语言中,“独立”往往意味着“互不相关”,但在统计学中,独立性是一个严格的数学定义。
📌 举例:
抛一枚硬币两次,有人会说这两个事件不独立,因为是同一枚硬币。但统计上,只要结果互不影响,它们就是独立的。
✅ 理解这一点非常重要,避免在实际建模中产生误判。
8. 小结
- 统计独立性是指两个事件或变量之间没有概率上的依赖关系。
- 成对独立 ≠ 互独立,后者要求任意子集的联合概率都等于各自概率的乘积。
- 条件独立性是在给定某些信息后才成立的独立性。
- 随机变量的独立性可以通过其分布函数来判断。
- 统计独立性不同于日常语言中的“无关”概念,需用数学定义严格判断。
掌握这些概念,有助于我们在数据分析、建模和实验设计中做出更准确的判断和决策。