1. 概述
在自然语言处理(NLP)和信息检索领域,词干提取(Stemming) 和 词形还原(Lemmatization) 是两个非常常见的文本预处理技术。
它们的核心目标都是将词语进行归一化处理,从而让不同形式的同一词最终映射到一个统一的形式。例如:
- “running” → “run”
- “dogs” → “dog”
虽然两者目的相似,但实现方式、适用场景和效果上存在明显差异。本文将从原理、优缺点和使用场景几个方面对两者进行对比分析,帮助你在实际项目中做出合适的选择。
2. 为什么需要词干提取和词形还原
✅ 词干提取和词形还原都属于词语归一化技术。
它们常用于搜索引擎、文本分类、语义分析等任务中,目的是处理词语的不同变体。例如:
- 用户搜索“dog foods”,我们希望也能匹配到“dog food”
- 用户搜索“running”,我们希望也能匹配到“run”
如果不进行归一化处理,系统就无法识别这些词之间的语义关联,从而影响检索或分析效果。
3. 词干提取(Stemming)
✅ 词干提取是一种较为简单的归一化方法,通常通过一系列预定义规则逐步对词语进行处理。
- 每种语言有其对应的规则集
- 规则通常基于语言的形态结构设计
- 例如英文中,常见规则是去掉“s”表示复数,去掉“ed”表示过去式等
⚠️ 注意:词干提取的结果不一定是合法的单词。
比如使用 Porter Stemmer 对 “engine” 和 “engines” 进行处理,结果都是 “engin”,虽然这不是一个标准英文单词,但只要它们归一到同一个词干,就能满足索引匹配的需求。
✅ 适用场景:
- 搜索引擎中的文档索引
- 对速度要求高、对结果准确性要求不苛刻的场景
4. 词形还原(Lemmatization)
✅ 词形还原可以看作是词干提取的高级版本。它将词语还原为在词典中可以查到的标准词形(Lemma)。
⚠️ 与词干提取不同的是,词形还原依赖于词性(POS)信息。
例如:
- “following” 作为名词 → “following”
- “following” 作为动词 → “follow”
- “better” 作为形容词 → “good”
词干提取器通常无法区分这些情况,会统一处理为“follow”或“bet”。
✅ 词形还原的优势在于:
- 生成的结果是合法词汇
- 更适合需要语义理解的 NLP 任务,如词义消歧、文本摘要、问答系统等
示例对比
以下是一个英文句子的词干提取与词形还原对比:
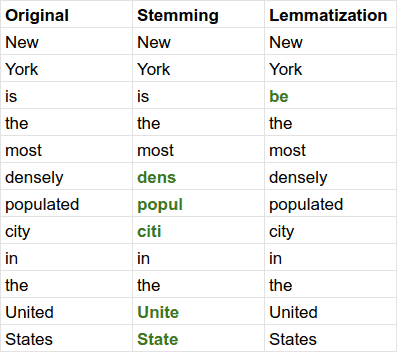
5. 对比与选择建议
| 特性 | 词干提取(Stemming) | 词形还原(Lemmatization) |
|---|---|---|
| 实现复杂度 | ✅ 简单 | ❌ 复杂 |
| 运行速度 | ✅ 快 | ❌ 慢 |
| 结果准确性 | ❌ 低(可能不合法) | ✅ 高(合法词) |
| 是否依赖词性 | ❌ 否 | ✅ 是 |
| 适用场景 | 搜索引擎、快速文本处理 | 高精度 NLP 任务 |
✅ 总结建议:
- 如果你对处理速度要求极高,且不需要语义准确的词语形式,可以考虑使用 词干提取
- 如果你处理的是语义敏感任务,比如文本分类、问答系统、语义相似度计算,建议使用 词形还原
⚠️ 踩坑提醒:有些项目初期用词干提取,后期发现语义偏差严重,再切换词形还原成本高,建议一开始就根据业务需求选型。
6. 总结
本文介绍了自然语言处理中两个重要的词语归一化技术:词干提取 和 词形还原。
- 两者都能帮助我们处理词语的多种变形
- 词干提取速度快但准确性低,适合对性能敏感的场景
- 词形还原更准确但实现复杂,更适合语义敏感的应用
在实际项目中,选择哪种方式取决于你的业务需求和资源限制。随着计算资源的提升,词形还原已经成为越来越多项目的首选方案。