1. 引言
损失函数是机器学习过程中不可或缺的一部分。它提供了一个重要的反馈信号,告诉我们模型的表现如何。在很多情况下,尤其是神经网络中,我们通过对模型参数求导来利用损失函数直接指导学习过程。
因此,选择一个合适的损失函数至关重要,而这个“合适”的函数并不总是直观可见的。本文将介绍代理损失函数(Surrogate Loss Function)的概念,并说明它为何在实际训练中如此重要。
2. 什么是损失函数?
损失函数用于量化模型预测值与真实值之间的差异。 在分类任务中,我们通常希望最小化经验风险(empirical risk),即错误分类的概率。
以二分类问题为例,我们有一个数据集  ,其中:
,其中:
 是输入特征向量
是输入特征向量 是类别标签,取值为 -1 或 1
是类别标签,取值为 -1 或 1
我们使用一个简单模型:
f_w(X) = \text{sign}(Xw)
该模型根据输出是否大于等于 0 来决定预测类别。为了优化模型,我们需要找到最优权重  。
。
一个最直接的损失函数是:
- 正确预测时为 0
- 错误预测时为 1
这被称为0-1损失函数,但它非常“生硬”——没有中间状态,无法提供梯度信息。这在优化时是个大问题:我们无法知道模型是“差一点就对了”还是“完全错了”。
3. 为什么要引入代理损失函数?
从上一节可以看出,0-1损失函数虽然直观,但缺乏梯度信息,无法指导模型更新。于是我们引入代理损失函数,作为更“友好”的替代方案。
常见的代理损失函数包括:
| 损失函数 | 表达式 | 特点 |
|---|---|---|
| Hinge Loss(SVM) | max(1 - f_w(x), 0) |
带有间隔(margin)的设计,适合最大间隔分类 |
| Logistic Loss | log(1 / (1 + e^{-f_w(x)})) |
平滑且连续,适合梯度下降 |
| Huber Loss | 分段函数 | 对异常值鲁棒,结合了MSE和MAE的优点 |
下图对比了这些代理损失函数与0-1损失(step function)的曲线差异:
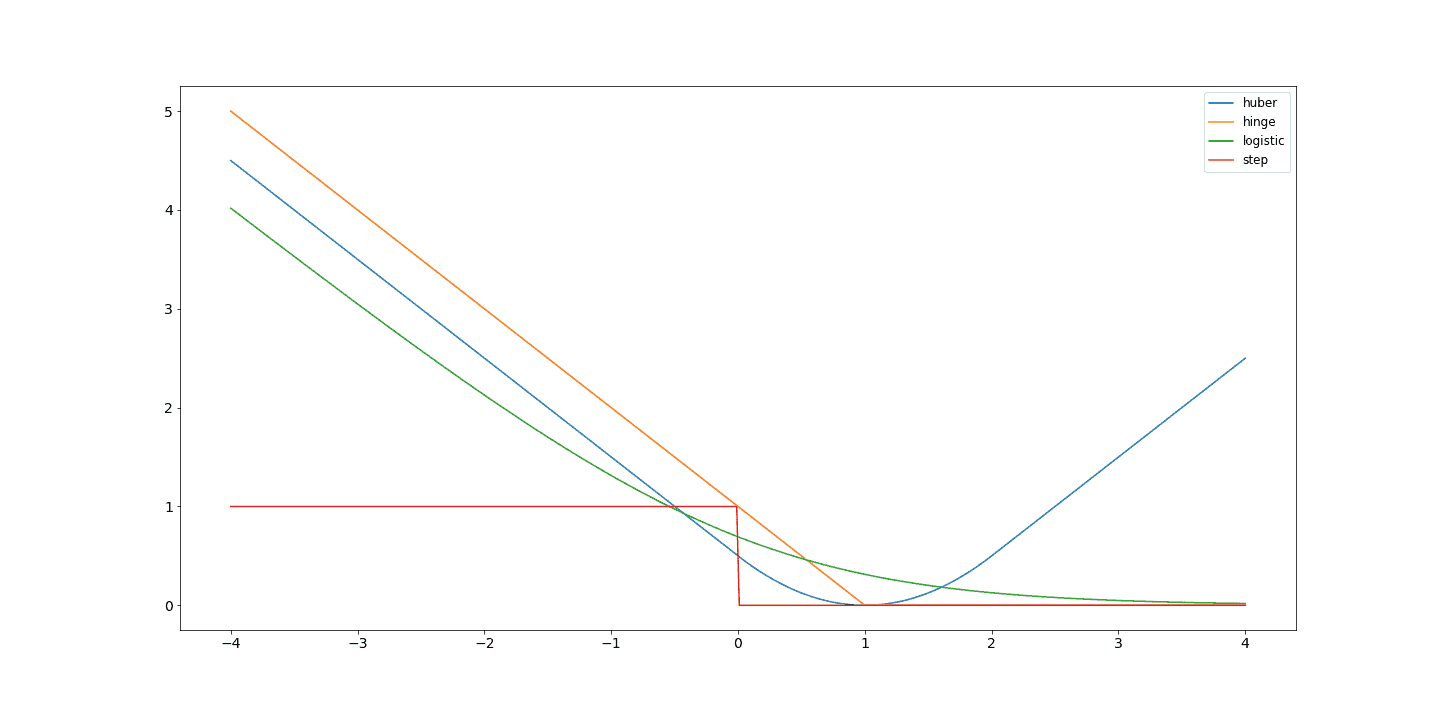
✅ 优点:代理损失函数通常是连续且可导的,能提供更丰富的学习信号
❌ 缺点:它们可能不是我们真正想最小化的目标(比如分类错误率),因此需要权衡
⚠️ 注意:某些代理损失函数(如Logistic Loss)在接近0的地方梯度变化剧烈,容易引起数值不稳定性
4. 代理损失函数的现代应用
在一些现代学习任务中,比如决策导向学习(Decision-Focused Learning),我们不仅要预测结果,还要将预测值输入到一个决策模型中进行后续处理。
在这种情况下,直接使用任务相关的损失函数往往会导致梯度信号非常微弱甚至不可导。这时,代理损失函数就派上用场了——它们被设计成既能逼近真实目标,又能提供良好的梯度引导。
不过,这类代理损失函数通常是非凸的,容易陷入局部最优。近年来的研究(例如 Learning to Optimize Combinatorial Functions)尝试通过端到端学习代理损失函数,以克服这一问题。
5. 总结
代理损失函数之所以重要,是因为它解决了真实损失函数在优化过程中不可导或信号不强的问题。
✅ 核心观点:
- 0-1损失函数虽然直观,但无法用于梯度下降
- 代理损失函数提供了更“友好”的优化路径
- 不同任务适合不同的代理损失函数,选择时需结合模型特性
- 在现代决策导向任务中,代理损失函数仍是一个活跃的研究方向
📌 踩坑提醒:不要盲目套用某个损失函数,比如用Logistic Loss去做SVM任务,会导致模型性能下降。要结合具体任务、数据分布和模型结构来选择或设计代理损失函数。