1. 简介
本文将介绍如何使用支持向量机(Support Vector Machines, SVM)进行多类别分类任务。我们会先介绍分类、多类别分类和支持向量机的基本概念,然后讲解 SVM 是如何应用于多类别分类的。最后,我们将通过 Python 示例代码演示如何使用 Scikit-learn 中的 SVM 实现多类别分类。
2. 分类概述
分类是机器学习中的一个核心任务,指的是模型根据输入数据将其分配到预定义的类别中。例如:
- 在计算机视觉中,判断一张图片是猫还是狗
- 在自然语言处理中,判断一段文本的情感是正面、负面还是中性
要完成分类任务,模型需要从带有标签的训练数据中学习特征和类别之间的映射关系。
分类任务主要分为两类:
2.1 二分类(Binary Classification)
模型将输入样本分为两个类别之一,例如:
- 图片是否包含人脸(是/否)
- 文本情感是否为正面(是/否)
- 某股票价格是否会上涨(是/否)
2.2 多类别分类(Multiclass Classification)
模型需要将输入样本分为三个或更多类别之一,例如:
- 将文本分为正面、负面或中性情感
- 判断图片中狗的品种
- 对新闻文章进行分类:体育、政治、经济或社会类
3. 支持向量机(Support Vector Machines, SVM)
SVM 是一种监督学习算法,主要用于分类和回归任务。其核心思想是通过寻找一个最优超平面,将不同类别的数据点尽可能分开。
3.1 工作原理
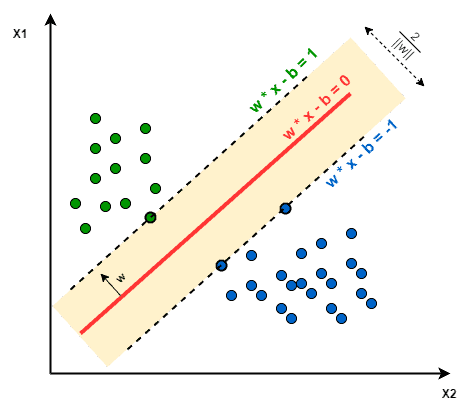
在二维空间中,SVM 试图找到一条直线,使得两类数据点之间的边界(margin)最大化。在更高维空间中,这个最优分隔面被称为“超平面”。
- 支持向量(Support Vectors):离超平面最近的数据点,它们决定了超平面的位置
- 核函数(Kernel Function):用于处理非线性可分问题,将数据映射到高维空间。常见核函数包括:
- Linear(线性)
- Polynomial(多项式)
- RBF(径向基函数)
- Sigmoid
下图展示了 SVM 的支持向量与超平面:
4. 使用 SVM 进行多类别分类
SVM 本质上是为二分类设计的。要实现多类别分类,通常采用以下两种策略:
4.1 一对多(One-vs-Rest / One-vs-All)
为每一个类别训练一个二分类器,将其与其余所有类别区分开。总共有 m 个类别时,需要训练 m 个 SVM 模型。
✅ 优点:实现简单
❌ 缺点:类别不平衡可能导致性能下降
4.2 一对一(One-vs-One)
为每一对类别训练一个二分类器,最终通过投票决定类别。总共有 m 个类别时,需要训练 m*(m-1)/2 个 SVM 模型。
✅ 优点:每个分类器只处理两个类别,训练更快
❌ 缺点:模型数量随类别数增长迅速
举个例子:假设我们要对三种颜色(绿色、红色、蓝色)进行分类。
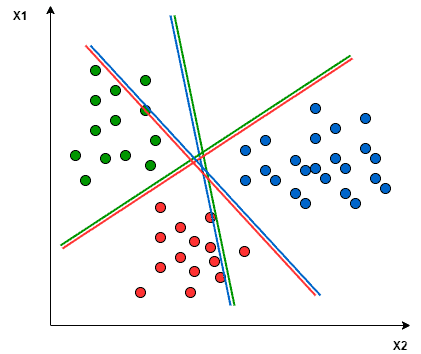
- 一对一:每个分类器只关注两个颜色之间的分界线,忽略第三个颜色的数据
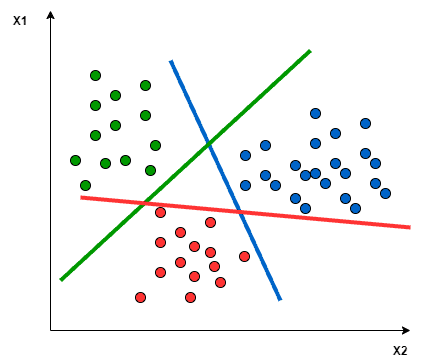
- 一对多:每个分类器试图将一个颜色与其他两个颜色区分开
如下图所示:
一对一:
一对多:
5. Python 示例:SVM 多类别分类
我们将使用 Scikit-learn 实现 SVM 多类别分类,使用经典的 Iris 数据集。
5.1 导入依赖库
from sklearn import svm, datasets
import sklearn.model_selection as model_selection
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
5.2 加载数据并划分训练集/测试集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征方便演示
y = iris.target
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, train_size=0.80, test_size=0.20, random_state=101
)
5.3 构建 SVM 分类器
我们分别使用 RBF 和 Polynomial 核函数构建两个模型:
rbf = svm.SVC(kernel='rbf', gamma=0.5, C=0.1).fit(X_train, y_train)
poly = svm.SVC(kernel='poly', degree=3, C=1).fit(X_train, y_train)
5.4 预测与评估
poly_pred = poly.predict(X_test)
rbf_pred = rbf.predict(X_test)
# 计算准确率和 F1 分数
poly_accuracy = accuracy_score(y_test, poly_pred)
poly_f1 = f1_score(y_test, poly_pred, average='weighted')
print('Accuracy (Polynomial Kernel): ', "%.2f" % (poly_accuracy*100))
print('F1 (Polynomial Kernel): ', "%.2f" % (poly_f1*100))
rbf_accuracy = accuracy_score(y_test, rbf_pred)
rbf_f1 = f1_score(y_test, rbf_pred, average='weighted')
print('Accuracy (RBF Kernel): ', "%.2f" % (rbf_accuracy*100))
print('F1 (RBF Kernel): ', "%.2f" % (rbf_f1*100))
5.5 输出结果
Accuracy (Polynomial Kernel): 70.00
F1 (Polynomial Kernel): 69.67
Accuracy (RBF Kernel): 76.67
F1 (RBF Kernel): 76.36
可以看到,RBF 核函数在本例中表现优于 Polynomial 核函数。
⚠️ 调整超参数(如 C、gamma、degree)会影响模型性能,建议使用交叉验证进行调参。
6. 总结
本文介绍了:
- 分类的基本概念:二分类 vs 多类别分类
- SVM 的工作原理及其核心要素(支持向量、核函数、超平面)
- SVM 多类别分类的两种策略:One-vs-One 和 One-vs-Rest
- 使用 Scikit-learn 实现 SVM 多类别分类的完整代码示例
通过本文,你应能掌握 SVM 在多类别分类任务中的基本应用方法,并能根据实际需求选择合适的核函数和分类策略。