1. 简介
在本教程中,我们将简要介绍支持向量机(SVM)和感知机(Perceptron)两种机器学习算法,并深入探讨它们之间的核心差异以及适用场景。
我们的目标是帮助读者理清这两个算法在实际应用中可能遇到的常见疑惑,尤其是在它们的相似性与差异性方面。
2. 支持向量机(Support Vector Machine)
支持向量机(SVM) 是一种广泛应用且有效的机器学习方法,适用于分类和回归任务,但更常用于分类问题。其核心思想是:尽可能准确地将不同类别样本分隔开。
以红蓝点分类为例,下图左侧显示三条可以正确划分两类样本的直线(超平面)。但哪一个是“最优”划分呢?SVM通过最大化两个类别之间的边界(margin)来选择最佳超平面。
下图右侧展示了 SVM 的划分方式,两个灰色边界之间的区域是 margin,中间的线是最终的分类超平面。边界上的点称为支持向量(Support Vectors):
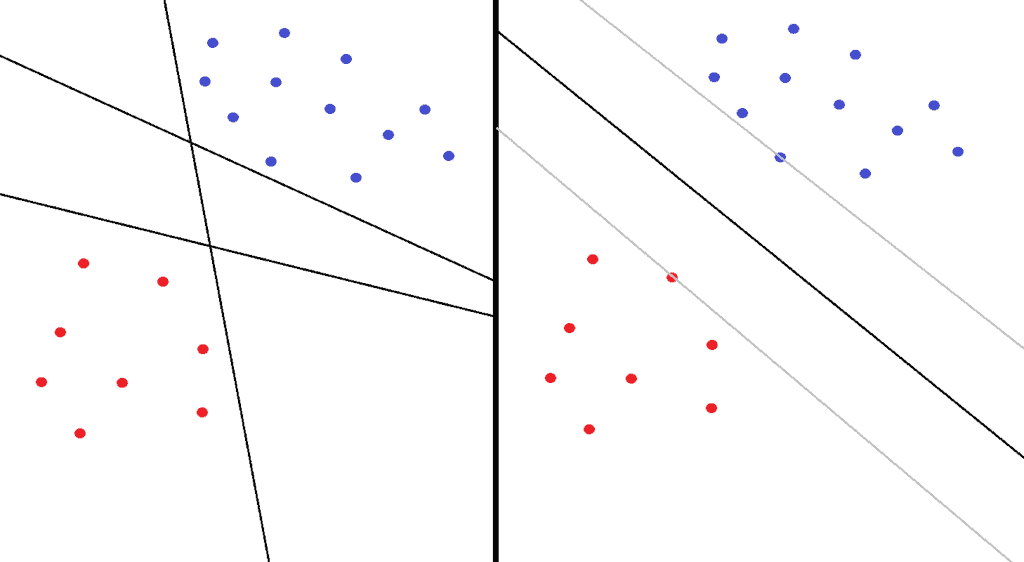
SVM 分为两种类型:
✅ 硬间隔分类(Hard-margin):要求所有样本都必须位于 margin 之外。缺点是容易受异常值影响,泛化能力差。
✅ 软间隔分类(Soft-margin):允许部分样本进入 margin 或者误分类,更适用于实际数据,泛化能力更强。
3. 感知机(Perceptron)
感知机(Perceptron) 是最早的人工神经网络之一,是一种用于二分类的监督学习算法。其核心思想是通过线性组合输入特征并使用阶跃函数进行分类。
输入为向量 x = (x₁, x₂, ..., xₙ),模型计算:
(1)
$$ z = x \cdot w + b $$
其中 w 是权重向量,b 是偏置项。然后通过阶跃函数判断类别:
(2)
$$
h(z) =
\begin{cases}
1, & \text{if } z \geq 0 \
0, & \text{if } z < 0
\end{cases}
$$
训练过程中,使用误差反向传播(backpropagation)更新权重:
(3)
$$ w(t+1) = w(t) + \alpha (y_j - \hat{y}_j)x_j $$
其中:
w:权重向量y_j:真实类别\hat{y}_j:预测类别\alpha:学习率
4. 核心差异分析
虽然 SVM 和 Perceptron 都是用于分类的线性模型,但它们在原理和实现上有显著区别。
4.1. 灵感来源
- ✅ Perceptron:灵感来自生物神经网络,属于神经网络模型。
- ✅ SVM:基于统计学习理论设计,属于结构风险最小化(SRM)框架下的模型。
4.2. 训练与优化方法
- ✅ Perceptron:使用梯度下降和误差反向传播进行参数更新。
- ✅ SVM:通过求解二次规划(Quadratic Programming)问题来最大化分类间隔。在 Scikit-Learn 中,使用 SMO(Sequential Minimal Optimization)算法高效求解。
4.3. 核技巧(Kernel Trick)
- ✅ SVM:支持核技巧,可以在不显式提升数据维度的前提下,将数据映射到高维空间以实现线性可分。
常用的核函数包括:
(4)
$$
\begin{aligned}
\text{线性核: } & K(u, v) = u \cdot v \
\text{多项式核: } & K(u, v) = (\gamma u \cdot v + c)^d \
\text{高斯 RBF 核: } & K(u, v) = \exp(-\gamma |u - v|^2) \
\text{Sigmoid 核: } & K(u, v) = \tanh(\gamma u \cdot v + c)
\end{aligned}
$$
举个例子,使用多项式核将二维向量 u 和 v 映射到三维空间:
(5)
$$
K(u, v) = (u \cdot v)^2 = \phi(u) \cdot \phi(v)
$$
而 SVM 的优化目标函数如下:
(6)
$$
\begin{aligned}
\max_{\alpha} & \quad F(\alpha) = \sum_{i=1}^{m}\alpha_i - \frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_j y^{(i)} y^{(j)} K(x^{(i)}, x^{(j)}) \
\text{s.t. } & \quad \alpha_i \geq 0,\ i=1,2,...,m \
& \quad \sum_{i=1}^{m}\alpha_i y^{(i)} = 0
\end{aligned}
$$
- ❌ Perceptron:不支持核技巧,无法自动将数据映射到高维空间,需要手动调整网络结构(如增加神经元或层数)来提升分类能力。
4.4. 多分类能力
- ✅ SVM:原生不支持多分类,需借助间接方法实现,常见方法包括:
- One-vs-One (OvO)
- One-vs-Rest (OvR)
例如,三类问题(X、Y、Z)使用 OvO 可拆分为:
- X vs Y
- X vs Z
- Y vs Z
使用 OvR 可拆分为:
- X vs [Y, Z]
- Y vs [X, Z]
- Z vs [X, Y]
- ✅ Perceptron:传统单层感知机也需要类似 OvO/OvR 方法,但现代实现(如多层感知机)通常直接使用 softmax 输出每个类别的概率。
4.5. 预测概率输出
- ✅ SVM:不直接输出概率,需借助校准方法(如 Platt Scaling)间接获得。
- ✅ Perceptron:使用 softmax 或 sigmoid 激活函数可直接输出概率值,适用于需要置信度的场景。
5. 总结
本文简要介绍了 SVM 和 Perceptron 两种分类算法,并从多个维度对比了它们的核心差异:
| 特性 | SVM | Perceptron |
|---|---|---|
| 灵感来源 | 统计学习理论 | 生物神经网络 |
| 优化方法 | 二次规划 | 梯度下降 |
| 支持核技巧 | ✅ | ❌ |
| 多分类支持 | 间接(OvO/OvR) | 可直接输出 |
| 输出概率 | 否(需校准) | ✅ |
在实际应用中,如果数据线性可分且特征维度高,SVM 更具优势;如果数据非线性且需要概率输出,Perceptron(尤其是深度神经网络)会是更合适的选择。
希望本文能帮助你更好地理解 SVM 与 Perceptron 的区别,并在项目中做出更合理的算法选择。