1. 引言
在本文中,我们将探讨自然语言处理(NLP)领域中一个极具挑战性的方向:主题建模(Topic Modeling)。主题建模可用于从文本中识别和提取不同的主题,帮助我们更轻松地理解大量文本数据。
在介绍完基本概念后,我们将深入讲解与之相关的技术,如 LDA(Latent Dirichlet Allocation)和 Coherence Score(一致性得分)。重点将放在理解这些指标的含义及其解读方式上。
2. 主题建模简介
主题建模是一种机器学习与自然语言处理技术,用于识别文档中所包含的主题。 它能通过分析词频,判断某个词或短语属于某个主题的概率,并基于相似性对文档进行聚类。
常见主题建模方法包括:
- Latent Dirichlet Allocation (LDA)
- Latent Semantic Analysis (LSA)
- Probabilistic Latent Semantic Analysis (PLSA)
- Non-Negative Matrix Factorization (NMF)
在本文中,我们将重点关注 LDA 中的 Coherence Score。
3. LDA(Latent Dirichlet Allocation)
LDA 是一种无监督学习技术,广泛用于文本分析。 它将词表示为“主题”,将文档表示为这些主题的组合。
LDA 的核心流程如下:
- 主题采样:在主题空间中初始化 Dirichlet 分布,并从文档的主题多项式分布中采样 N 个主题。
- 词采样:在词空间中初始化 Dirichlet 分布,并为每个采样出的主题,从词的多项式分布中采样 N 个词。
- 最大化生成文档的概率。
LDA 的数学定义如下:
$$ P(\boldsymbol{W}, \boldsymbol{Z}, \boldsymbol{\theta}, \boldsymbol{\phi}; \alpha, \beta) = \prod_{i = 1}^{M}P(\theta_{j}; \alpha)\prod_{i = 1}^{K}P(\phi; \beta)\prod_{t = 1}^{N}P(Z_{j, t} | \theta_{j})P(W_{j, t} | \phi z_{j, t}) $$
其中:
- $\alpha$ 和 $\beta$ 表示 Dirichlet 分布参数
- $\theta$ 和 $\phi$ 表示多项式分布
- $\boldsymbol{Z}$ 是所有文档中词的主题向量
- $\boldsymbol{W}$ 是所有文档中词的向量
- $M$ 表示文档数量,$K$ 表示主题数量,$N$ 表示词的数量
训练 LDA 模型通常使用 Gibbs 采样,其核心思想是让每篇文档和每个词尽可能“单一化”,即文档尽可能只包含一个主题,词尽可能只属于一个主题。
4. Coherence Score(一致性得分)
Coherence Score 用于衡量主题模型中提取出的主题对人类来说是否具有可解释性。 主题通常由概率最高的前 N 个词表示,Coherence Score 就是衡量这些词之间是否“语义连贯”。
4.1. CV Coherence Score
CV(C_v)一致性得分是一种流行的一致性评分方法,它结合词共现、NPMI(归一化点互信息)和余弦相似度进行计算。虽然它是 Gensim 的默认评分方式,但其作者 并不推荐使用,因为其评估效果并不稳定。
✅ 不推荐使用 CV 评分。
4.2. UMass Coherence Score
UMass 一致性得分通过计算两个词 $w_i$ 和 $w_j$ 在语料库中共同出现的频率来评估一致性。 公式如下:
$$ C_{UMass}(w_{i}, w_{j}) = \log \frac{D(w_{i}, w_{j}) + 1}{D(w_{i})} $$
其中:
- $D(w_i, w_j)$ 表示词 $w_i$ 和 $w_j$ 一起出现的次数
- $D(w_i)$ 表示词 $w_i$ 单独出现的次数
得分越高,表示词之间越相关。注意:UMass 不是对称的,即 $C_{UMass}(w_i, w_j) \ne C_{UMass}(w_j, w_i)$。
4.3. UCI Coherence Score
UCI 一致性得分基于滑动窗口和词对的点互信息(PMI)进行计算。 它关注的是词在局部上下文中的共现情况。公式如下:
$$ C_{UCI}(w_{i}, w_{j}) = \log \frac{P(w_{i}, w_{j}) + 1}{P(w_{i}) \cdot P(w_{j})} $$
其中:
- $P(w)$ 是词在滑动窗口中出现的概率
- $P(w_i, w_j)$ 是词 $w_i$ 和 $w_j$ 在同一滑动窗口中同时出现的概率
滑动窗口大小通常为 10,意味着我们只考虑某个词前后 10 个词之间的共现关系。
4.4. Word2vec Coherence Score
Word2vec 一致性得分通过词向量的语义相似度来衡量主题一致性。 它从两个维度评估:
- Intra-topic similarity(主题内相似度):同一主题中词之间的相似度
- Inter-topic similarity(主题间相似度):不同主题之间词的相似度
最终的 Word2vec 一致性得分定义为:
$$ C_{word2vec}(t_{i}, t_{j}) = \frac{\frac{intra_topic_similarity(t_{i}) + intra_topic_similarity(t_{j})}{2}}{inter_topic_similarity(t_{i}, t_{j})} $$
得分越高,说明主题内词越相似,主题间词越不相似,模型越理想。
4.5. 如何选择最佳一致性得分?
没有统一标准来判断 Coherence Score 是好是坏。 得分的高低依赖于数据本身。例如,在某些场景下,0.5 可能已经很好,而在其他场景下则可能太低。
通常,一致性得分会随着主题数量增加而提高,但提升幅度会逐渐变小。我们可以通过 Elbow Method(肘部方法) 来选择最佳主题数量:
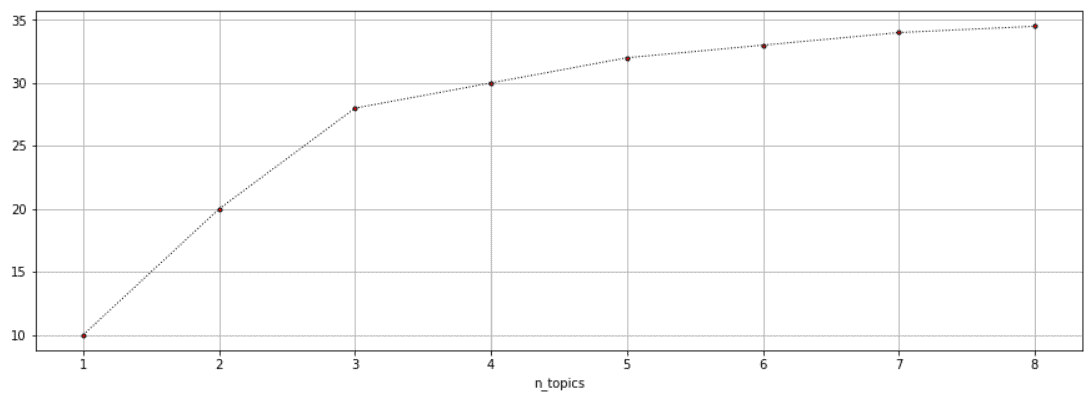
在图中,我们可以看到在 $n_topics = 3$ 处出现“肘部”,即继续增加主题数量带来的收益开始下降。
此外,Coherence Score 也受 LDA 超参数(如 $\alpha$、$\beta$、$K$)影响。可以使用 超参数调优技术 来优化这些参数。
⚠️ 注意: 最终仍需人工验证模型结果。因为无监督学习的评估本身就具有挑战性。
5. 总结
本文介绍了主题建模的基本概念,详细讲解了 LDA 的工作原理,并深入分析了几种常见的 Coherence Score 指标,包括:
- CV(不推荐)
- UMass
- UCI
- Word2vec
我们还讨论了如何判断一致性得分的好坏,并推荐使用 Elbow Method 和人工验证相结合的方式选择最佳主题数量。
主题建模是 NLP 中极具挑战性的任务之一,随着互联网文本数据的不断增长,这一领域的研究将持续深入。