1. 简介
在本篇文章中,我们将深入探讨 Hibernate 提供的查询计划缓存(Query Plan Cache)及其对性能的影响。
2. 查询计划缓存机制
在执行 JPQL 或 Criteria 查询之前,Hibernate 会将这些查询语句解析为抽象语法树(Abstract Syntax Tree, AST),然后基于 AST 生成对应的 SQL 语句。这个解析过程是耗时的,为了提升性能,Hibernate 引入了 QueryPlanCache。
对于原生 SQL 查询(Native Query),Hibernate 也会提取参数信息和返回类型,并将其封装为 ParameterMetadata 存入缓存中。
每次执行查询时,Hibernate 会先检查缓存中是否存在对应的查询计划:
- ✅ 如果命中缓存,则直接使用;
- ❌ 如果未命中,则重新编译查询计划并将其缓存起来供后续使用。
3. 缓存配置项
查询计划缓存的行为可以通过以下两个配置项进行控制:
- hibernate.query.plan_cache_max_size:控制查询计划缓存的最大条目数,默认值为
2048。 - hibernate.query.plan_parameter_metadata_max_size:控制 ParameterMetadata 缓存的最大条目数,默认值为
128。
⚠️ 如果应用执行的查询数量超过了缓存大小,Hibernate 就需要频繁地重新编译查询计划,导致整体查询性能下降。
4. 测试环境搭建
俗话说得好:“性能优化不能靠嘴,得看数据。”所以我们来实测一下不同缓存配置对查询编译时间的影响。
4.1. 实体类定义
我们使用两个实体类进行测试:DeptEmployee 和 Department。
@Entity
public class DeptEmployee {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
private String employeeNumber;
private String title;
private String name;
@ManyToOne
private Department department;
// standard getters and setters
}
@Entity
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private long id;
private String name;
@OneToMany(mappedBy="department")
private List<DeptEmployee> employees;
// standard getters and setters
}
4.2. 待测查询语句
我们选取了以下三个典型的 HQL 查询用于测试:
- findEmployeesByDepartmentName
session.createQuery("SELECT e FROM DeptEmployee e " +
"JOIN e.department WHERE e.department.name = :deptName")
.setMaxResults(30)
.setHint(QueryHints.HINT_FETCH_SIZE, 30);
- findEmployeesByDesignation
session.createQuery("SELECT e FROM DeptEmployee e " +
"WHERE e.title = :designation")
.setHint(QueryHints.SPEC_HINT_TIMEOUT, 1000);
- findDepartmentOfAnEmployee
session.createQuery("SELECT e.department FROM DeptEmployee e " +
"JOIN e.department WHERE e.employeeNumber = :empId");
5. 性能测试分析
5.1. JMH 测试状态类
我们使用 JMH 进行基准测试,测试中通过改变缓存大小来观察编译时间的变化。
@State(Scope.Thread)
public static class QueryPlanCacheBenchMarkState {
@Param({"1", "2", "3"})
public int planCacheSize;
public Session session;
@Setup
public void stateSetup() throws IOException {
session = initSession(planCacheSize);
}
private Session initSession(int planCacheSize) throws IOException {
Properties properties = HibernateUtil.getProperties();
properties.put("hibernate.query.plan_cache_max_size", planCacheSize);
properties.put("hibernate.query.plan_parameter_metadata_max_size", planCacheSize);
SessionFactory sessionFactory = HibernateUtil.getSessionFactoryByProperties(properties);
return sessionFactory.openSession();
}
//teardown...
}
5.2. 基准测试方法
测试方法如下,主要测量 Hibernate 编译查询语句的平均耗时:
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(1)
@Warmup(iterations = 2)
@Measurement(iterations = 5)
public void givenQueryPlanCacheSize_thenCompileQueries(
QueryPlanCacheBenchMarkState state, Blackhole blackhole) {
Query query1 = findEmployeesByDepartmentNameQuery(state.session);
Query query2 = findEmployeesByDesignationQuery(state.session);
Query query3 = findDepartmentOfAnEmployeeQuery(state.session);
blackhole.consume(query1);
blackhole.consume(query2);
blackhole.consume(query3);
}
5.3. 测试结果
运行上述基准测试后,我们得到如下结果图表:
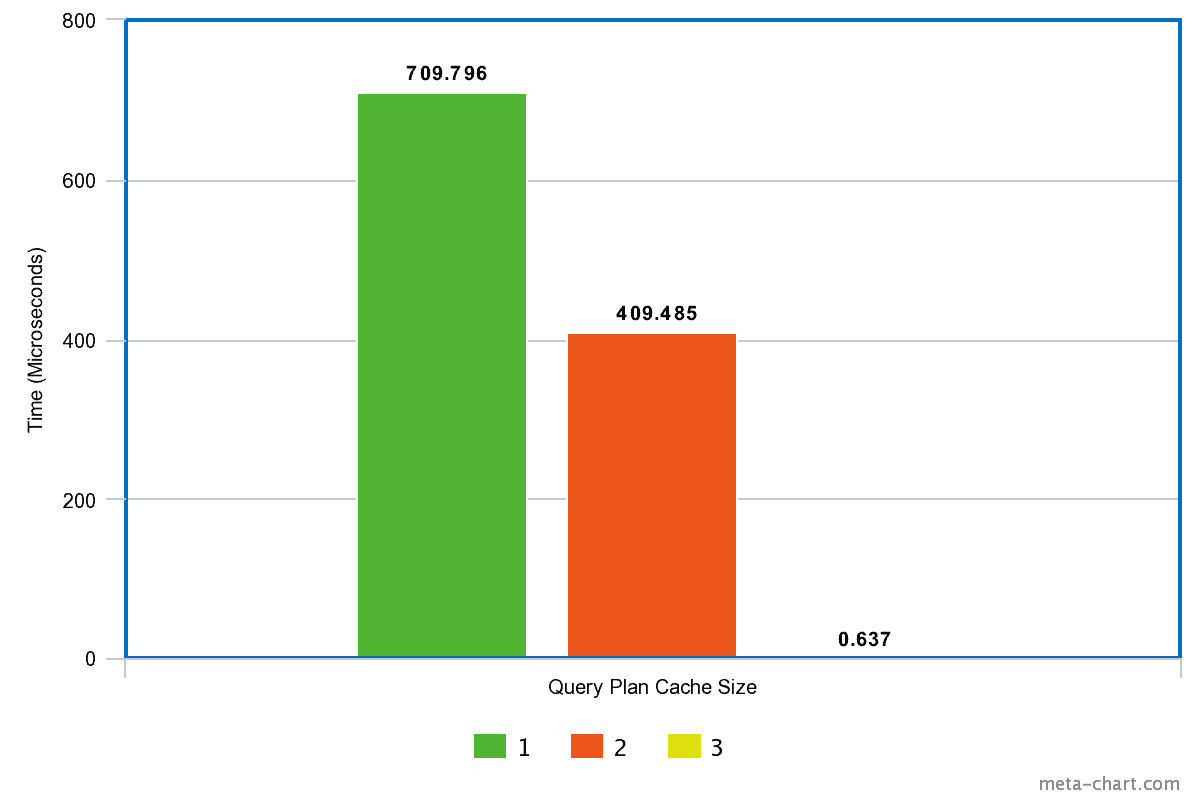
从图中可以看出:
- 当缓存大小为 1 时,平均编译时间为 709 微秒;
- 当缓存大小增加到 2 时,时间下降至 409 微秒;
- 当缓存大小为 3 时,编译时间骤降至 0.637 微秒。
✅ 显然,适当增大查询计划缓存可以显著减少查询编译开销。
6. 使用 Hibernate 统计信息监控缓存
Hibernate 提供了 Statistics 接口来监控缓存效果,其中两个关键指标是:
getQueryPlanCacheHitCount:缓存命中次数getQueryPlanCacheMissCount:缓存未命中次数
📌 如果命中率高而未命中率低,说明大多数查询都复用了缓存中的计划,性能表现良好。
7. 结论
本文讲解了 Hibernate 查询计划缓存的机制与优化策略。合理配置缓存大小,能有效提升查询性能,避免不必要的重复编译开销。
如需获取本文完整源码,请访问:GitHub 项目地址。