1. 引言
寻路算法是用于在地图或图结构中导航的技术,核心目标是从起点到终点找出一条可行路径。不同算法在效率和路径质量之间各有取舍——有的计算快但路径绕远,有的精准但耗资源。
本文将带你用 Java 实现 A*(A-Star)算法,并以伦敦地铁线路为例,直观展示其工作原理。这不仅适用于游戏开发中的角色移动,也能用于物流路径规划、网络路由等场景。
2. 什么是寻路算法?
寻路算法的本质,是将由“节点”和“边”构成的图结构,转化为一条从起点到终点的行走路径。这个“图”可以是任何需要遍历的系统:城市道路、游戏地图、地铁网络,甚至是代码调用栈。
本文以伦敦地铁部分线路为例:
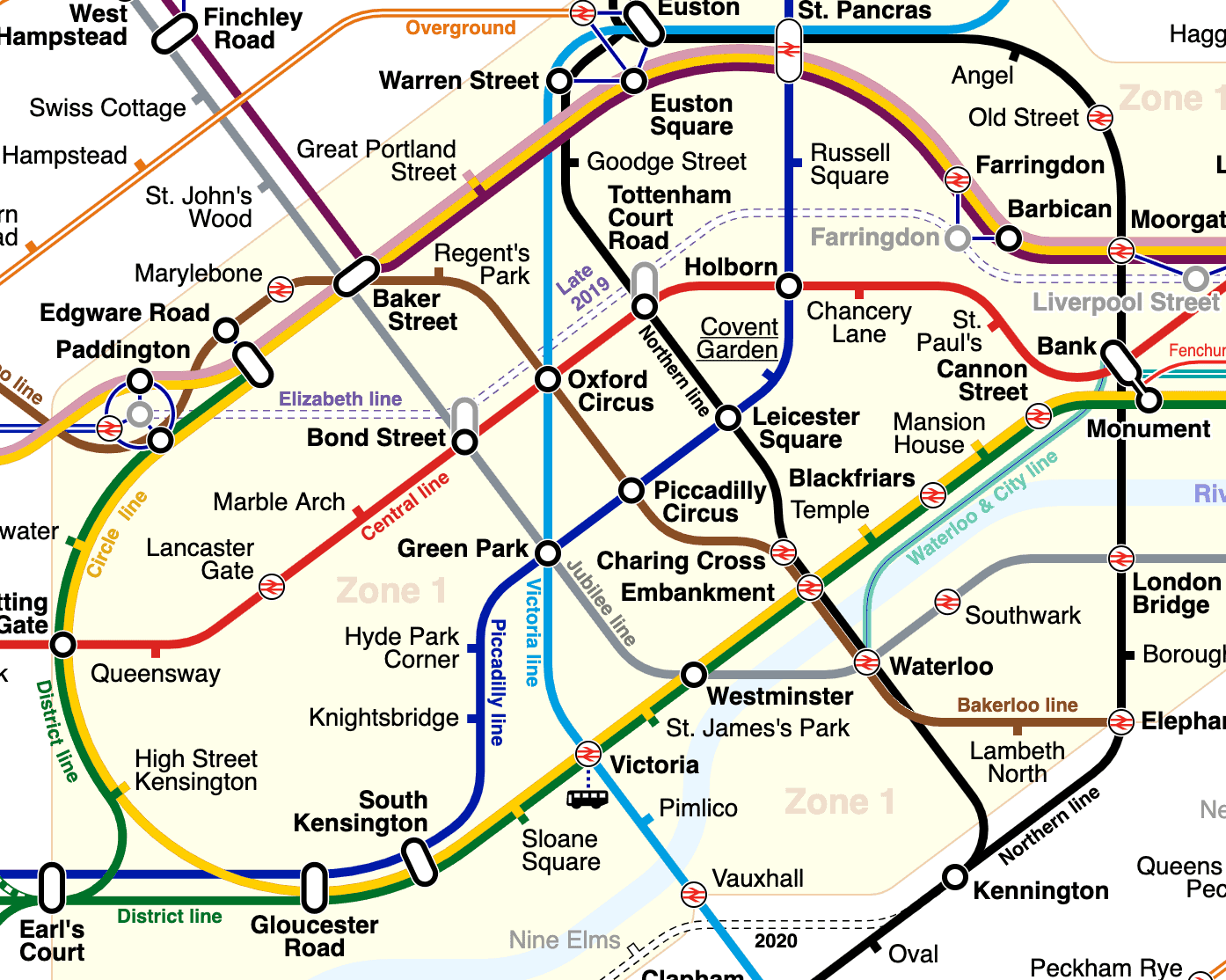
(来源:“London Underground Overground DLR Crossrail map” by sameboat,CC BY-SA 4.0 许可)
{kind=link}
这个图有几个关键特征:
- ✅ 并非所有站点都有直达线路。比如 “Earl’s Court” 可直达 “Monument”,但不能直达 “Angel”。
- ✅ 每一步都有成本。本文中成本是站点间的地理距离(公里)。
- ✅ 每个站点只连接少数几个邻居。例如 “Regent’s Park” 只连接 “Baker Street” 和 “Oxford Circus”。
寻路算法的输入通常包括:
- 所有节点(站点)
- 节点间的连接关系
- 起点和终点
输出则是从起点到终点的节点序列,即实际行走路线。
3. 什么是 A* 算法?
A* 是一种特定的寻路算法,由 Peter Hart, Nils Nilsson 和 Bertram Raphael 于 1968 年提出。它被广泛认为是在无法预计算路径、且内存充足时的最优选择。
⚠️ 但它的时空复杂度最坏情况下可达 *O(b^d)*(b 是分支因子,d 是深度),意味着虽然总能找到最优路径,但可能非常慢。
A* 实际上是 Dijkstra 算法的改进版,核心区别在于引入了启发式函数(heuristic),用于指导搜索方向。这个启发值不需要完美,但越准确,算法效率越高。
简单粗暴地说:
- Dijkstra:盲目探索,向所有方向均匀扩展。
- A*:聪明地探索,优先朝着“看起来更接近终点”的方向走。
4. A* 算法的工作原理
A* 的核心思想是:每一步都选择当前“综合代价”最低的节点进行扩展,逐步逼近终点。
你需要维护几个关键数据结构:
- ✅ 开放集合(open set):待探索的节点集合。不是全图所有节点,而是当前可能成为下一步的候选节点。
- ✅ 每个节点的三个关键值:
routeScore:从起点到当前节点的实际代价。estimatedScore:从起点经当前节点到终点的预估总代价(=routeScore+ 启发值)。previous:记录到达当前节点的最佳前驱节点,用于回溯路径。
算法流程如下:
- 初始化:将起点加入 open set,
routeScore=0,estimatedScore=启发值。 - 循环直到 open set 为空或找到终点:
- 从 open set 中取出
estimatedScore最小的节点(记为current)。 - 如果
current是终点,回溯previous链,构建路径并返回。 - 否则,遍历
current的所有邻居:- 计算从起点经
current到该邻居的新routeScore。 - 如果这个新分数比已知的更优,则更新该邻居的
routeScore、estimatedScore和previous,并将其加入 open set。
- 计算从起点经
- 从 open set 中取出
这个过程会不断“修正”对路径的认知,直到找到最优解。
4.1 手动推演示例
我们从 “Marylebone” 出发,寻找去 “Bond Street” 的路径。
初始状态:open set 只有 “Marylebone”,其
estimatedScore就是到 “Bond Street” 的直线距离(启发值)。第一次迭代:
- “Marylebone” 的邻居是 “Edgware Road”(距离 0.4403 km)和 “Baker Street”(0.4153 km)。
- 启发值(到终点的预估距离):
- “Edgware Road” → “Bond Street”:1.4284 km →
estimatedScore = 0.4403 + 1.4284 = 1.8687 km - “Baker Street” → “Bond Street”:1.0753 km →
estimatedScore = 0.4153 + 1.0753 = 1.4906 km
- “Edgware Road” → “Bond Street”:1.4284 km →
- ✅ “Baker Street” 综合代价更低,成为下一轮探索的首选。
第二次迭代:从 “Baker Street” 开始。
- 它的一个邻居是 “Marylebone”(回来的路)。
- 新
routeScore= 0.4153 (到 Baker) + 0.4153 (回来) = 0.8306 km。 - 启发值还是 ~1.323 km →
estimatedScore ≈ 2.1536 km。 - ❌ 这个值比 “Marylebone” 原本的
estimatedScore(约 1.323 km)差得多! - 结论:走回头路是劣解,不更新 “Marylebone” 的信息,也不将其重新加入 open set。
这个例子展示了 A* 如何避免无效探索,体现了启发式函数的价值。
5. Java 实现
我们先构建一个通用的 A* 框架,再填充伦敦地铁的具体逻辑。
5.1 图结构的表示
首先定义图的两个核心组件:节点和图本身。
**节点接口 GraphNode**:
public interface GraphNode {
String getId();
}
所有节点必须提供一个唯一 ID。其他属性(如名称、坐标)是业务相关的,不放在这里。
**图结构 Graph**:
public class Graph<T extends GraphNode> {
private final Set<T> nodes;
private final Map<String, Set<String>> connections;
public T getNode(String id) {
return nodes.stream()
.filter(node -> node.getId().equals(id))
.findFirst()
.orElseThrow(() -> new IllegalArgumentException("No node found with ID"));
}
public Set<T> getConnections(T node) {
return connections.get(node.getId()).stream()
.map(this::getNode)
.collect(Collectors.toSet());
}
}
nodes存储所有节点。connections用邻接表存储连接关系(Map<节点ID, 相邻节点ID集合>)。- 提供
getNode()和getConnections()方法进行查询。
这套设计足够灵活,能表示任意图结构。
5.2 路径计算中的辅助类
1. 评分器 Scorer
用于计算两种代价:
public interface Scorer<T extends GraphNode> {
double computeCost(T from, T to);
}
- 实现类负责计算
from到to的实际距离或预估距离。 - 一个用于计算真实步进代价(如站点间距离)。
- 另一个用于计算到终点的启发式代价(如直线距离)。
2. 路径节点 RouteNode
这是在寻路过程中使用的包装类,包含动态信息:
class RouteNode<T extends GraphNode> implements Comparable<RouteNode> {
private final T current;
private T previous;
private double routeScore;
private double estimatedScore;
RouteNode(T current) {
this(current, null, Double.POSITIVE_INFINITY, Double.POSITIVE_INFINITY);
}
RouteNode(T current, T previous, double routeScore, double estimatedScore) {
this.current = current;
this.previous = previous;
this.routeScore = routeScore;
this.estimatedScore = estimatedScore;
}
// getter and setter methods...
}
关键字段:
current:对应的原始图节点。previous:路径中的前一个节点。routeScore:从起点到current的实际总代价。estimatedScore:从起点经current到终点的预估总代价。
⚠️ 必须实现 Comparable,以便在优先队列中按 estimatedScore 排序:
@Override
public int compareTo(RouteNode other) {
if (this.estimatedScore > other.estimatedScore) {
return 1;
} else if (this.estimatedScore < other.estimatedScore) {
return -1;
} else {
return 0;
}
}
5.3 核心寻路逻辑 RouteFinder
这是 A* 算法的主体:
public class RouteFinder<T extends GraphNode> {
private final Graph<T> graph;
private final Scorer<T> nextNodeScorer; // 计算步进代价
private final Scorer<T> targetScorer; // 计算启发代价
public RouteFinder(Graph<T> graph, Scorer<T> nextNodeScorer, Scorer<T> targetScorer) {
this.graph = graph;
this.nextNodeScorer = nextNodeScorer;
this.targetScorer = targetScorer;
}
public List<T> findRoute(T from, T to) {
Queue<RouteNode> openSet = new PriorityQueue<>();
Map<T, RouteNode<T>> allNodes = new HashMap<>();
RouteNode<T> start = new RouteNode<>(from, null, 0d, targetScorer.computeCost(from, to));
openSet.add(start);
allNodes.put(from, start);
while (!openSet.isEmpty()) {
RouteNode<T> next = openSet.poll();
if (next.getCurrent().equals(to)) {
// 找到终点,回溯路径
List<T> route = new ArrayList<>();
RouteNode<T> current = next;
do {
route.add(0, current.getCurrent());
current = allNodes.get(current.getPrevious());
} while (current != null);
return route;
}
// 遍历邻居
graph.getConnections(next.getCurrent()).forEach(connection -> {
RouteNode<T> nextNode = allNodes.getOrDefault(connection, new RouteNode<>(connection));
allNodes.put(connection, nextNode);
double newScore = next.getRouteScore() + nextNodeScorer.computeCost(next.getCurrent(), connection);
if (newScore < nextNode.getRouteScore()) {
// 发现更优路径,更新信息
nextNode.setPrevious(next.getCurrent());
nextNode.setRouteScore(newScore);
nextNode.setEstimatedScore(newScore + targetScorer.computeCost(connection, to));
openSet.add(nextNode);
}
});
}
throw new IllegalStateException("No route found");
}
}
✅ 核心逻辑就在这几十行代码里:
- 用
PriorityQueue管理 open set,自动弹出最优节点。 allNodesMap 记录所有已访问节点的最新状态。- 每次扩展邻居时,判断是否找到了更短的路径,是则更新并加入 open set。
5.4 伦敦地铁的具体实现
现在填充业务细节。
1. 地铁站 Station
public class Station implements GraphNode {
private final String id;
private final String name;
private final double latitude;
private final double longitude;
// constructor, getters...
}
latitude 和 longitude 用于计算距离。
2. 启发式评分器 HaversineScorer
使用 Haversine 公式计算地球表面两点间的直线距离:
public class HaversineScorer implements Scorer<Station> {
@Override
public double computeCost(Station from, Station to) {
double R = 6372.8; // Earth's Radius, in kilometers
double dLat = Math.toRadians(to.getLatitude() - from.getLatitude());
double dLon = Math.toRadians(to.getLongitude() - from.getLongitude());
double lat1 = Math.toRadians(from.getLatitude());
double lat2 = Math.toRadians(to.getLatitude());
double a = Math.pow(Math.sin(dLat / 2),2)
+ Math.pow(Math.sin(dLon / 2),2) * Math.cos(lat1) * Math.cos(lat2);
double c = 2 * Math.asin(Math.sqrt(a));
return R * c;
}
}
这个实现同时用于 nextNodeScorer 和 targetScorer(因为都是算距离)。
3. 测试运行
public void findRoute() {
// 假设 underground 是已构建好的 Graph<Station>
RouteFinder<Station> routeFinder = new RouteFinder<>(underground, new HaversineScorer(), new HaversineScorer());
List<Station> route = routeFinder.findRoute(underground.getNode("74"), underground.getNode("7")); // Earl's Court -> Angel
System.out.println(route.stream().map(Station::getName).collect(Collectors.toList()));
}
输出结果:
[Earl's Court, South Kensington, Green Park, Euston, Angel]
⚠️ 踩坑点:你可能会疑惑,为什么不走 “Earl’s Court -> Monument -> Angel”(换乘少)?因为 A* 只考虑总距离,而这条路线实际更远。算法选择了更直接的路径,即使换乘更多。这说明了目标函数(cost function)决定行为。
6. 总结
本文实现了 A* 寻路算法的通用 Java 框架,并以伦敦地铁为例进行了验证。
关键收获:
- ✅ A* 通过
f(n) = g(n) + h(n)平衡已走代价和预估代价,高效找到最优路径。 - ✅ 启发函数
h(n)至关重要,越准确,搜索越快。 - ✅ 通用设计(泛型 + 接口)让代码可复用,只需替换
GraphNode和Scorer实现即可用于新场景。
下一步可以尝试:
- 在代价函数中加入“换乘惩罚”,让算法倾向于少换乘。
- 为不同线路设置不同权重(如高峰期的线路拥堵系数)。
- 将图数据从文件或数据库中加载。
完整代码已托管在 GitHub:https://github.com/eugenp/tutorials/tree/master/algorithms-modules/algorithms-miscellaneous-2