1. 引言
在数据结构与算法(DSA)问题中,统计序列中的特定模式总是充满挑战。我们之前讨论过在整数列表中寻找峰值元素的多种方法,其中不同解法的时间复杂度从 O(log n) 到 O(n) 不等。
本文将解决一个经典问题:识别并统计整数数组中的山丘与谷底。这个问题能很好地锻炼我们的数组遍历和条件判断能力。我们将逐步拆解问题,提供解决方案、代码示例和详细解释。
2. 问题定义
给定一个整数数组,我们需要识别并统计所有的山丘和谷底。
核心定义:
- 山丘(Hill):相邻元素序列,以较低值开始,中间达到峰值,然后以较低值结束。
- 谷底(Valley):相反模式,以较高值开始,中间达到谷值,然后回升。
简单说:山丘是两侧都有更低元素的峰值,谷底是两侧都有更高元素的谷值。
⚠️ 注意:相邻的相同值元素属于同一个山丘或谷底。要判断某个索引是否属于山丘或谷底,其左右两侧必须存在不相等的邻居。这意味着我们每次需要同时检查三个连续索引。
2.1 示例分析
通过以下示例理解山丘和谷底的概念:
输入数组: [4, 5, 6, 5, 4, 5, 4]
逐步分析数组中的山丘和谷底:
边界索引 0 和 6:首尾元素缺少左/右邻居,无法构成山丘或谷底,直接忽略。
**索引 1 (值 5)**:最近的不等邻居是左 4 和右 6。5 不大于邻居(非山丘),也不小于邻居(非谷底)。
**索引 2 (值 6)**:邻居是左 5 和右 5。6 大于两侧邻居,形成山丘 [5, 6, 5]。
**索引 3 (值 5)**:邻居是左 6 和右 4。5 小于 6 但大于 4,既非山丘也非谷底。
**索引 4 (值 4)**:邻居是左 5 和右 5。4 小于两侧邻居,形成谷底 [5, 4, 5]。
**索引 5 (值 5)**:邻居是左 4 和右 4。5 大于两侧邻居,形成山丘 [4, 5, 4]。
最终,数组 [4, 5, 6, 5, 4, 5, 4] 的山丘和谷底总数为 3。
2.2 图形化表示
将数组 numbers = [4, 5, 6, 5, 4, 5, 4] 绘制成图表(x轴为索引,y轴为值),用虚线连接点以直观展示山丘和谷底:
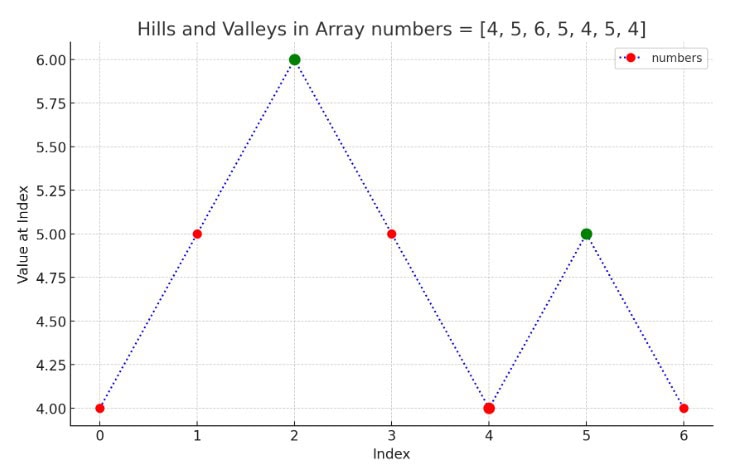
✅ 绿色标记表示山丘(值高于两侧邻居)
❌ 红色标记表示谷底(值低于两侧邻居)
图表清晰显示:2个山丘 + 1个谷底 = 总数3
3. 算法设计
以下是解决该问题的算法步骤:
1. 接收整数数组 numbers
2. 遍历数组(从第二个元素到倒数第二个元素)
3. 对每个索引 i:
prev = numbers[i-1], current = numbers[i], next = numbers[i+1]
4. 遇到连续相等元素时跳过,保留最后出现的值
5. 识别山丘:
若 current > prev 且 current > next,则为山丘
山丘计数器 +1
6. 识别谷底:
若 current < prev 且 current < next,则为谷底
谷底计数器 +1
7. 重复步骤3-6直到遍历结束
8. 返回山丘和谷底的总数
💡 关键点:只需单次遍历数组即可完成统计,时间效率很高。
4. Java实现
将算法转化为Java代码:
int countHillsAndValleys(int[] numbers) {
int hills = 0;
int valleys = 0;
for (int i = 1; i < numbers.length - 1; i++) {
int prev = numbers[i - 1];
int current = numbers[i];
int next = numbers[i + 1];
// 跳过连续重复元素
while (i < numbers.length - 1 && numbers[i] == numbers[i + 1]) {
i++;
}
// 更新next为第一个不相等的邻居(如果存在)
if (i != numbers.length - 1) {
next = numbers[i + 1];
}
// 判断山丘或谷底
if (current > prev && current > next) {
hills++;
} else if (current < prev && current < next) {
valleys++;
}
}
return hills + valleys;
}
代码解析:
- 遍历范围从索引1到
length-2,确保每个元素都有左右邻居 - 通过
while循环跳过连续重复值,避免重复计算 - 更新
next为第一个不相等的邻居值 - 比较当前元素与邻居:
- ✅ 大于两侧 → 山丘
- ❌ 小于两侧 → 谷底
- 返回总数
🚀 优势:无需额外数据结构,空间复杂度O(1),实现简单粗暴。
5. 测试验证
通过多种测试用例验证解决方案:
// 测试用例1:示例数组
int[] array1 = { 4, 5, 6, 5, 4, 5, 4};
assertEquals(3, countHillsAndValleys(array1));
// 测试用例2:严格递增数组
int[] array2 = { 1, 2, 3, 4, 5, 6 };
assertEquals(0, countHillsAndValleys(array2)); // 无山丘/谷底
// 测试用例3:常量数组
int[] array3 = { 5, 5, 5, 5, 5 };
assertEquals(0, countHillsAndValleys(array3)); // 全相等
// 测试用例4:无山丘/谷底数组
int[] array4 = { 6, 6, 5, 5, 4, 1 };
assertEquals(0, countHillsAndValleys(array4));
// 测试用例5:平坦谷底
int[] array5 = { 6, 5, 4, 4, 4, 5, 6 };
assertEquals(1, countHillsAndValleys(array5)); // 1个谷底
// 测试用例6:平坦山丘
int[] array6 = { 1, 2, 4, 4, 4, 2, 1 };
assertEquals(1, countHillsAndValleys(array6)); // 1个山丘
关键用例说明:
array2严格递增 → 无山丘/谷底array3全等 → 无山丘/谷底array5中间平坦 → 算法正确识别为1个谷底
6. 复杂度分析
时间复杂度:O(n)
仅需单次遍历数组,每个元素最多被检查一次。
空间复杂度:O(1)
仅使用固定数量的计数器变量,无额外数据结构。
7. 总结
本文系统性地解决了数组中山丘与谷底的计数问题:
- ✅ 明确定义了山丘和谷底
- ✅ 提供了高效的单次遍历算法
- ✅ 通过图形化示例增强理解
- ✅ 覆盖边界情况(平坦区域、严格单调等)
- ✅ 验证了多种测试用例
这种问题在信号处理、金融数据分析等领域有实际应用,掌握其解法能提升数组操作和条件判断的实战能力。