1. 概述
在数组中查找第一个重复元素的索引是常见的编程问题,有多种解决方法。虽然暴力法简单直接,但对于大数据集效率低下。
本教程将探讨不同解决方案,从基础的暴力法到使用 HashSet 和数组索引等优化技术。
2. 问题定义
给定一个整数数组,找出第一个重复元素的索引。
输入: arr = [2, 1, 3, 5, 3, 2]
输出: 4
解释: 第一个重复的元素是 3,其第二次出现在索引 4 处。
输入: arr = [1, 2, 3, 4, 5]
输出: -1
解释: 没有重复元素,返回 -1。
3. 暴力法
这种方法通过双重循环检查每个元素与后续元素是否重复。
先看实现代码,再逐步解析:
int firstDuplicateBruteForce(int[] arr) {
int minIndex = arr.length;
for (int i = 0; i < arr.length - 1; i++) {
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] == arr[j]) {
minIndex = Math.min(minIndex, j);
break;
}
}
}
return minIndex == arr.length ? -1 : minIndex;
}
代码解析:
- 外层循环遍历每个元素
i,内层循环查找后续重复元素j - 发现重复时,用
minIndex记录最早出现的重复索引 break确保只记录每个元素的第一次重复- 最终若
minIndex未更新则返回-1
时间复杂度:O(n²)(双重循环)
空间复杂度:O(1)(仅用常数空间)
4. 使用 HashSet
利用 HashSet 存储已遍历元素,遇到重复时立即返回索引。
实现代码:
int firstDuplicateHashSet(int[] arr) {
HashSet<Integer> firstDuplicateSet = new HashSet<>();
for (int i = 0; i < arr.length; i++) {
if (firstDuplicateSet.contains(arr[i])) {
return i;
}
firstDuplicateSet.add(arr[i]);
}
return -1;
}
代码解析:
- 创建空
HashSet - 遍历数组时检查元素是否已存在
- 存在则返回当前索引(第一个重复)
- 不存在则添加到集合
- 遍历结束无重复则返回
-1
示例执行过程:
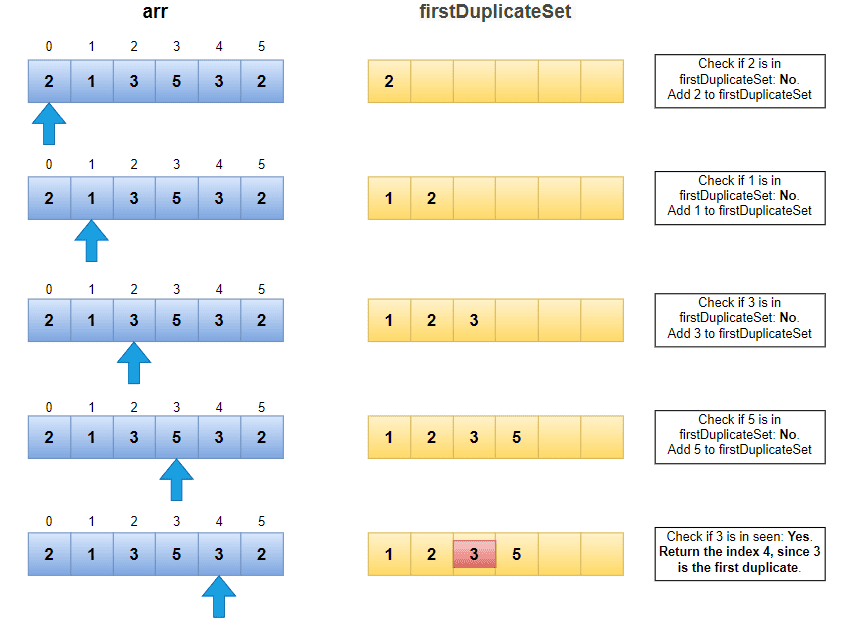
时间复杂度:O(n)(单次遍历,哈希操作平均 O(1))
空间复杂度:O(n)(最坏需存储所有元素)
5. 数组索引法
当元素为正数且范围在 [1, n] 时(n 为数组长度),可通过修改数组自身实现空间优化。
实现代码:
int firstDuplicateArrayIndexing(int[] arr) {
for (int i = 0; i < arr.length; i++) {
int val = Math.abs(arr[i]) - 1;
if (arr[val] < 0) {
return i;
}
arr[val] = -arr[val];
}
return -1;
}
代码解析:
- 遍历时将元素值转为索引(
val = |arr[i]| - 1) - 检查目标位置是否已被标记(负值)
- 若为负,说明重复,返回当前索引
- 否则标记为负值
- 无重复则返回
-1
示例执行过程:
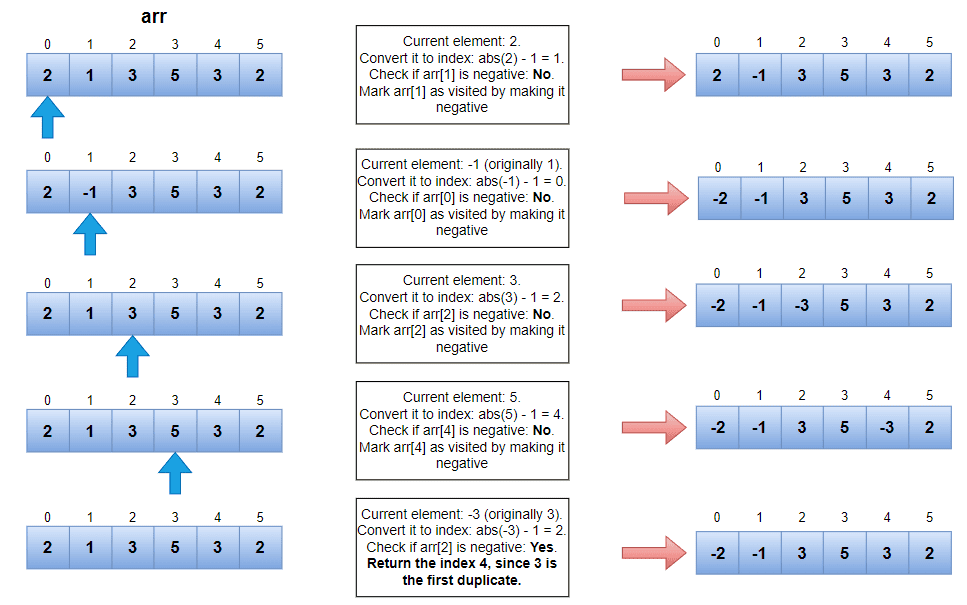
时间复杂度:O(n)(单次遍历)
空间复杂度:O(1)(原地修改数组)
6. 总结
本文探讨了三种查找数组第一个重复元素的方法,各有优劣:
| 方法 | 时间复杂度 | 空间复杂度 | 适用场景 |
|---|---|---|---|
| 暴力法 | O(n²) | O(1) | 小数据集,无需额外空间 |
| HashSet | O(n) | O(n) | 通用方案,允许额外空间 |
| 数组索引法 | O(n) | O(1) | 元素为正且范围在 [1, n] 内 |
✅ 关键选择点:
- 允许修改数组且元素范围受限 → 数组索引法
- 需要通用解法 → HashSet
- 空间敏感但数据量小 → 暴力法
掌握这些方法后,可根据实际约束灵活选择最优解。