1. 概述
本文将深入对比 BitSet 和 boolean[] 在不同场景下的性能表现。
我们常说的“性能”其实是个宽泛概念,可能指吞吐、延迟、内存占用等。因此,本文会先厘清性能的定义,再从两个关键维度进行对比:
✅ 内存占用(Memory Footprint)
✅ 吞吐量(Throughput)
我们将围绕位向量(bit-vector)的三个常见操作展开基准测试:
- 获取某一位的值
- 设置或清除某一位
- 统计已设置位的数量
目标是帮你做出更合理的选型决策,避免踩坑。
2. 性能的定义
“性能”这个词在不同语境下含义不同,常见的理解包括:
- 启动速度:应用从启动到可响应第一个请求的时间
- 内存占用:运行时消耗的堆内存大小
- 延迟(Latency):单次操作的响应时间
- 吞吐量(Throughput):单位时间内可完成的操作数
- 达到峰值性能的时间:JVM 热身后达到最佳性能所需时间
本文聚焦于两个最实用的指标:内存占用 和 吞吐量。其他指标虽重要,但不在本次讨论范围内。
3. 内存占用对比
先看一个关键事实:
❌ boolean 在 JVM 中并不是 1 bit,而是占用 1 字节(8 bits)。
这意味着一个长度为 10,000 的 boolean[] 实际占用约 10 KB 内存,而不是预期的 1.25 KB。
我们用 Java Object Layout (JOL) 验证这一点:
boolean[] ba = new boolean[10_000];
System.out.println(ClassLayout.parseInstance(ba).toPrintable());
输出结果:
[Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (1)
4 4 (object header) 00 00 00 00 (0)
8 4 (object header) 05 00 00 f8 (-134217723)
12 4 (object header) 10 27 00 00 (10000)
16 10000 boolean [Z. N/A
Instance size: 10016 bytes
实例总大小为 10,016 字节 ≈ 10 KB。
而 BitSet 使用 long 数组 + 位运算实现,真正做到了 1 bit per flag。
同样 10,000 位的 BitSet:
BitSet bitSet = new BitSet(10_000);
System.out.println(GraphLayout.parseInstance(bitSet).toPrintable());
输出:
java.util.BitSet@5679c6c6d object externals:
ADDRESS SIZE TYPE PATH
76beb8190 24 java.util.BitSet
76beb81a8 1272 [J .words
总大小约 1,296 字节 ≈ 1.3 KB,仅为 boolean[] 的 1/8。
我们进一步测试不同位数下的内存占用:
Path path = Paths.get("footprint.csv");
try (BufferedWriter stream = Files.newBufferedWriter(path, StandardOpenOption.CREATE)) {
stream.write("bits,bool,bitset\n");
for (int i = 0; i <= 10_000_000; i += 500) {
System.out.println("Number of bits => " + i);
boolean[] ba = new boolean[i];
BitSet bitSet = new BitSet(i);
long baSize = ClassLayout.parseInstance(ba).instanceSize();
long bitSetSize = GraphLayout.parseInstance(bitSet).totalSize();
stream.write((i + "," + baSize + "," + bitSetSize + "\n"));
if (i % 10_000 == 0) {
stream.flush();
}
}
}
绘制成图后可见:
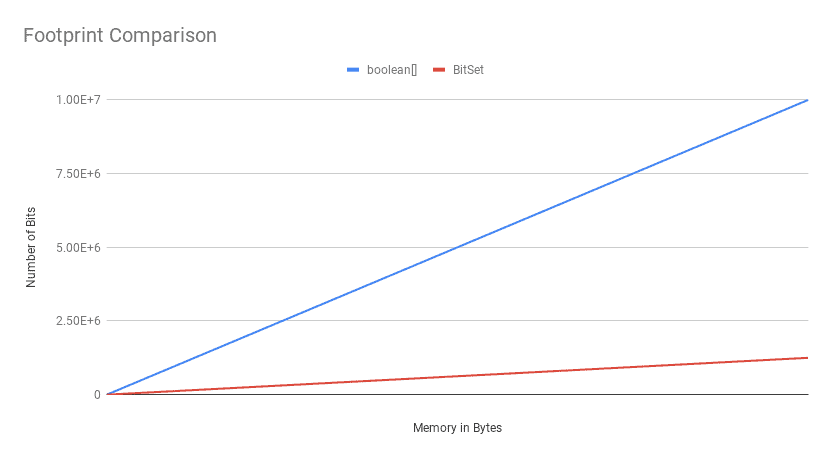
结论很清晰:
✅ 除极小规模外,BitSet 的内存优势极其明显,且随着位数增加差距越来越大。
4. 吞吐量对比
使用 JMH 进行基准测试,对比三种常见操作的吞吐量。
测试环境:Digital Ocean 4核 Intel Xeon 2.20GHz
基准类结构如下:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
public class VectorOfBitsBenchmark {
private boolean[] array;
private BitSet bitSet;
@Param({"100", "1000", "5000", "50000", "100000", "1000000", "2000000", "3000000",
"5000000", "7000000", "10000000", "20000000", "30000000", "50000000", "70000000", "1000000000"})
public int size;
@Setup(Level.Trial)
public void setUp() {
array = new boolean[size];
for (int i = 0; i < array.length; i++) {
array[i] = ThreadLocalRandom.current().nextBoolean();
}
bitSet = new BitSet(size);
for (int i = 0; i < size; i++) {
bitSet.set(i, ThreadLocalRandom.current().nextBoolean());
}
}
// benchmarks go here
}
4.1. 获取某一位的值
直觉上,boolean[] 的数组访问应该更快,毕竟 BitSet.get() 需要两次位运算(左移 + 与操作)。
但 BitSet 更紧凑的内存布局可能带来更好的缓存命中率。
测试代码:
@Benchmark
public boolean getBoolArray() {
return array[ThreadLocalRandom.current().nextInt(size)];
}
@Benchmark
public boolean getBitSet() {
return bitSet.get(ThreadLocalRandom.current().nextInt(size));
}
执行命令:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff get.csv getBitSet getBoolArray
4.2. 获取操作:吞吐量
结果如下:
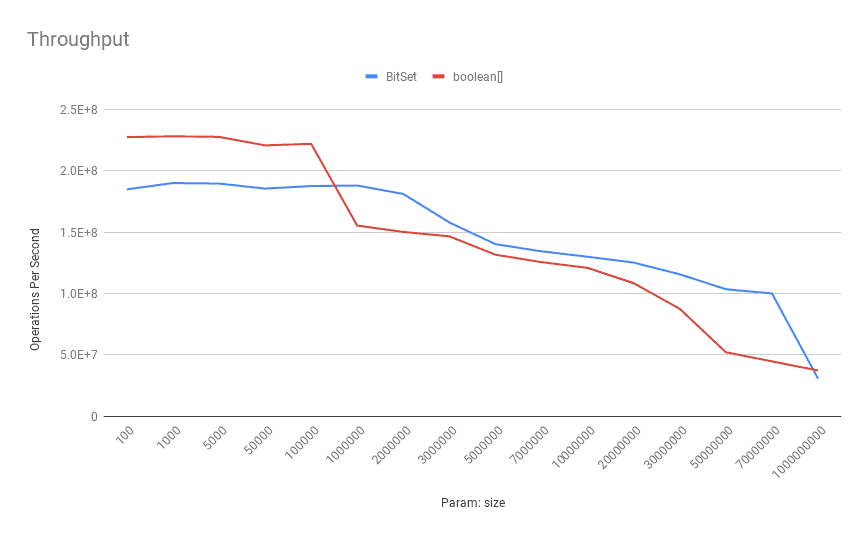
- ✅ 小规模(< 100,000)时,
boolean[]吞吐更高 - ✅ 规模增大后,
BitSet反超,优势明显
关键转折点在 10万位左右。
4.3. 获取操作:每操作指令数
boolean[] 每次 get 操作的 CPU 指令更少:
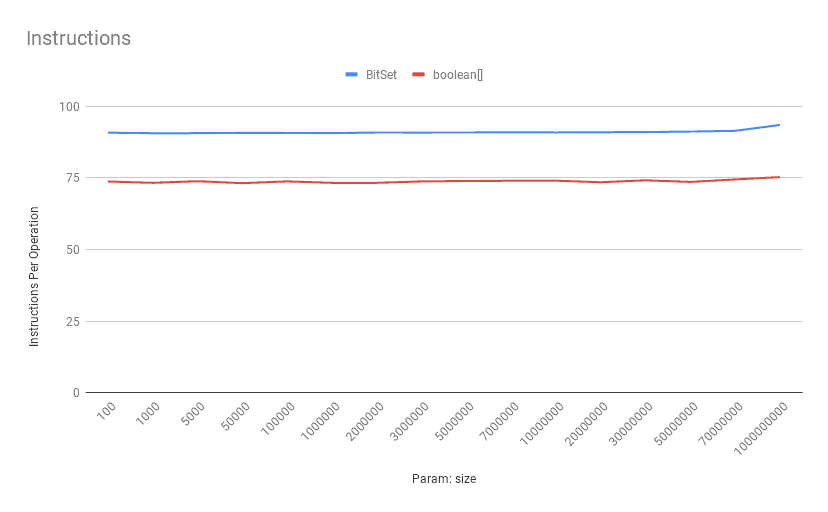
这说明 BitSet 的位运算确实引入了额外开销。
4.4. 获取操作:数据缓存未命中
但代价是缓存未命中率随规模上升而飙升:
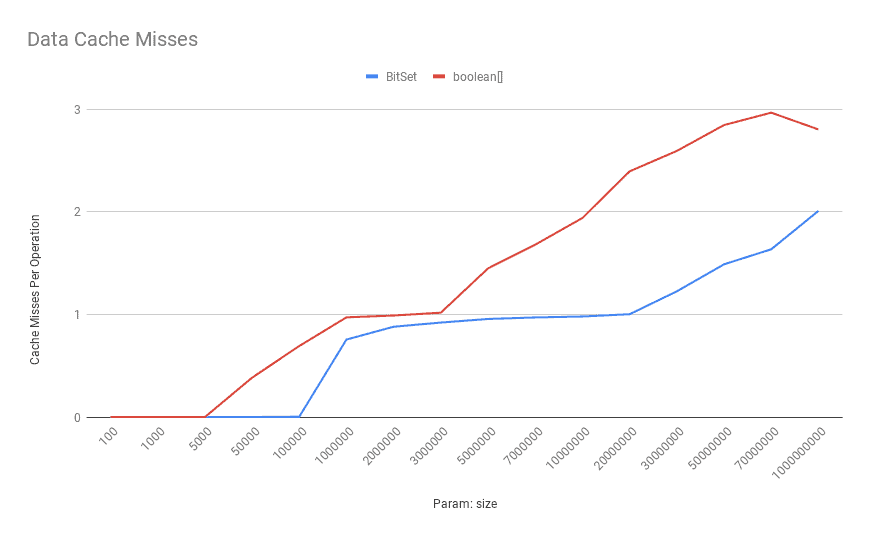
⚠️ 缓存未命中比多几条指令昂贵得多 —— 这正是 BitSet 在大规模下反超的根本原因。
4.5. 设置某一位的值
测试代码:
@Benchmark
public void setBoolArray() {
int index = ThreadLocalRandom.current().nextInt(size);
array[index] = true;
}
@Benchmark
public void setBitSet() {
int index = ThreadLocalRandom.current().nextInt(size);
bitSet.set(index);
}
执行命令:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff set.csv setBitSet setBoolArray
吞吐量表现:
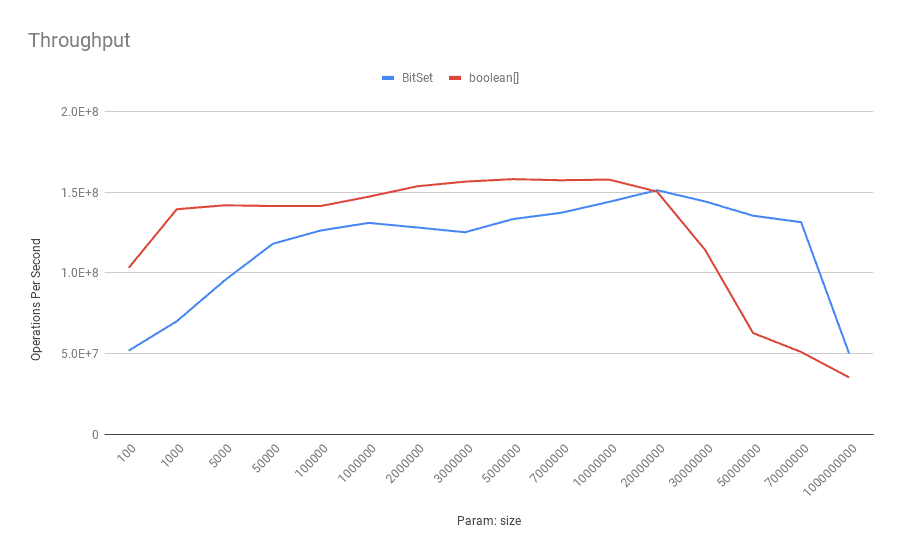
- ✅ 多数情况下
boolean[]写性能更优 - ✅ 仅在超大规模时
BitSet略胜一筹
数据缓存未命中:
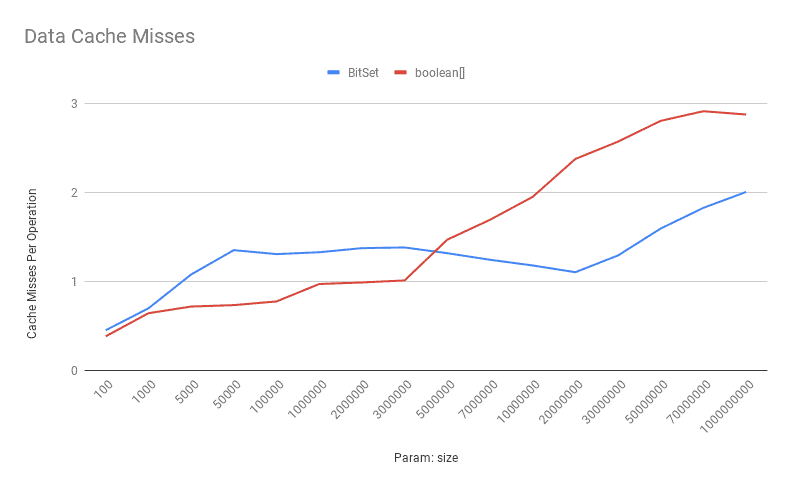
boolean[] 在中小规模下缓存表现优异,但随规模增长缓存压力上升。
每操作指令数:
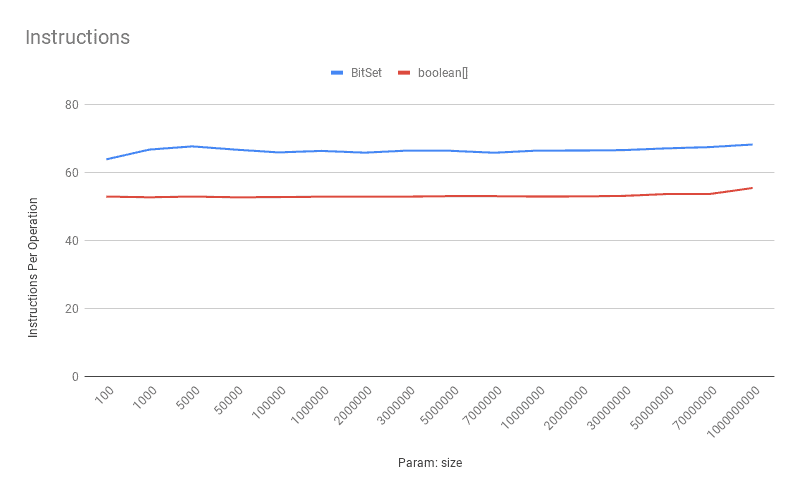
boolean[] 指令数更少,操作更直接。
📌 小结:
写操作中,BitSet 因需原子性更新 long 元素,存在 false sharing 风险,缓存竞争更激烈。
4.6. 统计置位数量(Cardinality)
这是 BitSet 的绝对优势场景。
测试代码:
@Benchmark
public int cardinalityBoolArray() {
int sum = 0;
for (boolean b : array) {
if (b) sum++;
}
return sum;
}
@Benchmark
public int cardinalityBitSet() {
return bitSet.cardinality();
}
执行命令:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff cardinal.csv cardinalityBitSet cardinalityBoolArray
吞吐量对比:
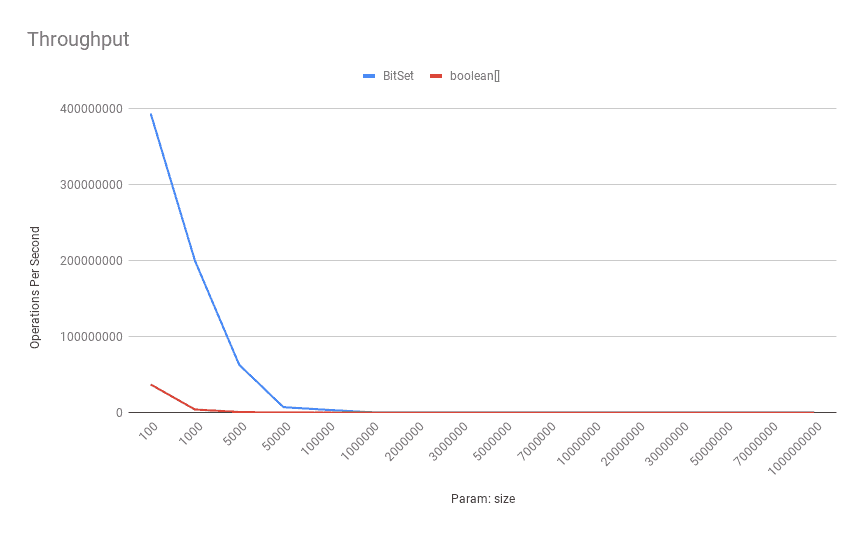
✅ BitSet.cardinality() 几乎在所有规模下都碾压 boolean[] 的手动遍历。
原因:
BitSet只需遍历内部long[],元素数量少得多- 使用了 并行位计数算法(如
Long.bitCount()),效率极高
分支预测失败次数:
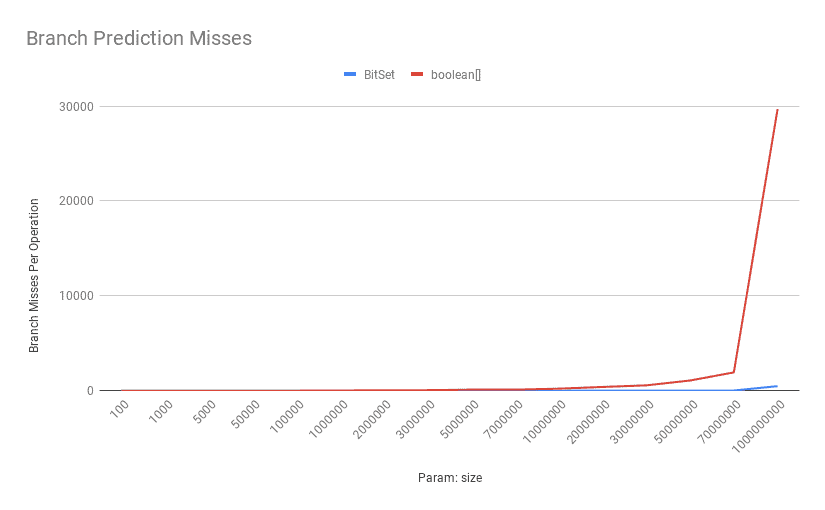
boolean[] 的 if (b) 判断在随机分布下分支预测失败率高,进一步拖慢性能。
5. 结论
综合来看,BitSet 和 boolean[] 各有适用场景:
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| ✅ 小规模读操作(< 10万位) | boolean[] |
直接内存访问,延迟低 |
| ✅ 大规模读操作 | BitSet |
缓存友好,吞吐高 |
| ✅ 高频写操作(中小规模) | boolean[] |
指令少,缓存命中高 |
| ✅ 大规模写操作 | BitSet |
内存紧凑,缓存压力小 |
| ✅ 统计置位数量 | BitSet |
内置高效算法,完胜遍历 |
核心建议:
- **优先考虑
BitSet**:除非你确定数据量小且以写为主 - 避免手动遍历
boolean[]做统计:这是典型性能陷阱 - 关注缓存行为:内存布局对性能的影响远超指令数
本文所有代码和测试数据均已开源:
- GitHub 示例:https://github.com/eugenp/tutorials/tree/master/jmh
- CSV 测试结果:https://github.com/eugenp/tutorials/tree/master/jmh/src/main/resources/bitset
如需深入分析底层性能指标(如 PMC),推荐使用 perf 工具,参考 Brendan Gregg 的性能分析博客。