1. 概述
本文将深入讲解广度优先搜索(Breadth-First Search, BFS)算法,这是一种在树或图结构中按“层”遍历节点的经典搜索策略——与深度优先(DFS)不同,BFS 优先探索当前节点的所有邻居,再进入下一层。
我们将从理论出发,理解 BFS 在树和图中的工作原理,接着用 Java 实现,并分析其时间复杂度。对于有经验的开发者来说,这是图遍历的基石,也是面试和实际开发中高频出现的考点。
2. 广度优先搜索算法原理
BFS 的核心思想是:使用队列(Queue)保证“先进先出”的访问顺序,从而实现逐层扩散式的搜索。
算法流程非常简单粗暴:
- 将起始节点入队
- 循环处理队列,直到为空:
- 出队一个节点
- 判断是否为目标节点,是则结束
- 否则将其所有未访问的子节点或邻居加入队列
关键在于数据结构的选择——队列是 BFS 的灵魂,它天然保证了访问顺序的“广度优先”。
2.1 树中的 BFS
树结构天然无环,因此 BFS 实现非常直接:
✅ 核心机制:维护一个节点队列,确保按层级顺序访问。
流程如下:
- 将根节点加入队列
- 当队列非空时循环:
- 出队一个节点
- 若该节点为目标值,搜索成功,返回
- 否则将其所有子节点加入队列末尾
- 队列为空仍未找到,返回失败
⚠️ 终止保障:由于树无环,每个节点最多被访问一次,算法必然终止。
2.2 图中的 BFS
图与树的最大区别在于可能存在环(cycle),如果不加控制,BFS 会陷入无限循环。
✅ 解决方案:引入一个 visited 集合,记录已访问的节点,避免重复处理。
流程调整为:
- 将起始节点入队,并加入
visited集合 - 当队列非空时循环:
- 出队一个节点
- 若为目标值,返回
- 否则遍历其所有邻居:
- 若邻居未在
visited中,则加入队列和visited
- 若邻居未在
- 队列为空仍未找到,返回失败
⚠️ 关键点:必须在将邻居加入队列之前或同时标记为已访问,否则可能因多个路径指向同一节点而导致重复入队。
3. Java 实现
理论清晰后,我们动手实现。代码将分为树和图两部分。
3.1 树的 BFS 实现
首先定义一个泛型 Tree 类,表示树节点:
public class Tree<T> {
private T value;
private List<Tree<T>> children;
private Tree(T value) {
this.value = value;
this.children = new ArrayList<>();
}
public static <T> Tree<T> of(T value) {
return new Tree<>(value);
}
public Tree<T> addChild(T value) {
Tree<T> newChild = new Tree<>(value);
children.add(newChild);
return newChild;
}
// getter 方法
public T getValue() {
return value;
}
public List<Tree<T>> getChildren() {
return children;
}
}
接下来实现 search 方法:
public static <T> Optional<Tree<T>> search(T value, Tree<T> root) {
if (root == null) return Optional.empty();
Queue<Tree<T>> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
Tree<T> currentNode = queue.remove();
LOGGER.debug("Visited node with value: {}", currentNode.getValue());
// 找到目标节点
if (currentNode.getValue().equals(value)) {
return Optional.of(currentNode);
}
// 将所有子节点加入队列
queue.addAll(currentNode.getChildren());
}
return Optional.empty();
}
示例与验证
构建如下树结构:
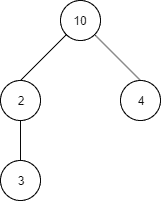
对应 Java 代码:
Tree<Integer> root = Tree.of(10);
Tree<Integer> child1 = root.addChild(2);
child1.addChild(3);
Tree<Integer> child2 = root.addChild(4);
搜索值为 4 的节点:
Optional<Tree<Integer>> result = BreadthFirstSearchAlgorithm.search(4, root);
日志输出符合预期,按层级顺序访问:
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 10
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 2
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 4
3.2 图的 BFS 实现
图结构需要处理环,因此节点设计如下:
public class Node<T> {
private T value;
private Set<Node<T>> neighbors;
public Node(T value) {
this.value = value;
this.neighbors = new HashSet<>();
}
// 建立双向连接
public void connect(Node<T> node) {
if (this == node) throw new IllegalArgumentException("Can't connect node to itself");
this.neighbors.add(node);
node.neighbors.add(this);
}
// getter 方法
public T getValue() {
return value;
}
public Set<Node<T>> getNeighbors() {
return neighbors;
}
}
BFS 搜索实现(带访问标记):
public static <T> Optional<Node<T>> search(T value, Node<T> start) {
if (start == null) return Optional.empty();
Queue<Node<T>> queue = new ArrayDeque<>();
Set<Node<T>> visited = new HashSet<>(); // 记录已访问节点
queue.add(start);
visited.add(start);
while (!queue.isEmpty()) {
Node<T> currentNode = queue.remove();
LOGGER.debug("Visited node with value: {}", currentNode.getValue());
if (currentNode.getValue().equals(value)) {
return Optional.of(currentNode);
}
// 遍历所有邻居
for (Node<T> neighbor : currentNode.getNeighbors()) {
if (!visited.contains(neighbor)) {
visited.add(neighbor);
queue.add(neighbor);
}
}
}
return Optional.empty();
}
示例与验证
构建一个含环的图:
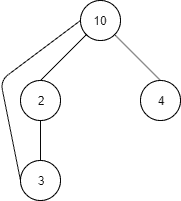
Java 代码:
Node<Integer> node10 = new Node<>(10);
Node<Integer> node2 = new Node<>(2);
Node<Integer> node3 = new Node<>(3);
Node<Integer> node4 = new Node<>(4);
node10.connect(node2);
node2.connect(node3);
node3.connect(node10); // 形成环
node10.connect(node4);
从 node3(值为 3)开始搜索值为 4 的节点:
Optional<Node<Integer>> result = BreadthFirstSearchAlgorithm.search(4, node3);
日志输出表明算法正确避开了环,仅访问每个节点一次:
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 3
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 2
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 10
[main] DEBUG c.b.a.b.BreadthFirstSearchAlgorithm - Visited node with value: 4
3.3 复杂度分析
我们使用大 O 记号(Big-O)来评估性能。
| 结构 | 时间复杂度 | 说明 |
|---|---|---|
| ✅ 树 (Tree) | O(n) | n 为节点数。每个节点最多入队、出队一次,addAll 操作总次数为 n-1(树的边数),因此整体为线性。 |
| ✅ 图 (Graph) | O(n + c) | n 为节点数,c 为边数。每个节点最多访问一次,每条边最多检查一次(在遍历邻居时)。O(n + c) 是标准表示法,实际取决于两者中较大者。 |
⚠️ 踩坑提醒:在图的实现中,若使用 queue.removeAll(visited) 这种集合操作,其时间复杂度为 O(queue_size × visited_size),在最坏情况下可能导致整体复杂度退化为 O(n²)。推荐使用 visited 集合进行显式检查(如上文实现),以保证 O(n + c) 的最优复杂度。
4. 总结
本文系统地介绍了广度优先搜索(BFS)算法:
- 核心:利用队列实现层级遍历
- 树 vs 图:图需额外维护
visited集合防环 - 实现:代码简洁,关键在数据结构选择
- 复杂度:树为 O(n),图为 O(n + c)
BFS 是解决最短路径(无权图)、连通分量、层级遍历等问题的利器。掌握其原理和实现,是每个 Java 开发者的必备技能。
完整代码示例已托管至 GitHub:https://github.com/baeldung/java-algorithms/tree/master/searching