1. 概述
Buffer 类是 Java NIO 的基石,其中 ByteBuffer 最为常用。因为 byte 类型具有极强的通用性:既能组合成 JVM 中的其他非布尔基本类型,也能在 JVM 与外部 I/O 设备间传输数据。
本文将深入剖析 ByteBuffer 的核心机制与实践技巧。
2. 创建 ByteBuffer
ByteBuffer 是抽象类,无法直接实例化。它提供了静态工厂方法,主要通过两种方式创建:
2.1. 分配方式(Allocation)
分配方式会创建新实例并分配指定容量的私有空间。ByteBuffer 提供两种分配方法:
非直接缓冲区(底层是字节数组):
ByteBuffer buffer = ByteBuffer.allocate(10);直接缓冲区(直接在操作系统内存分配):
ByteBuffer buffer = ByteBuffer.allocateDirect(10);
踩坑提示:直接缓冲区创建/销毁成本高,性能优化时再考虑(后文详述)。
2.2. 包装方式(Wrapping)
包装方式复用现有字节数组:
byte[] bytes = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(bytes);
等价于:
ByteBuffer buffer = ByteBuffer.wrap(bytes, 0, bytes.length);
注意:原数组与缓冲区共享数据,任一方修改都会同步反映。
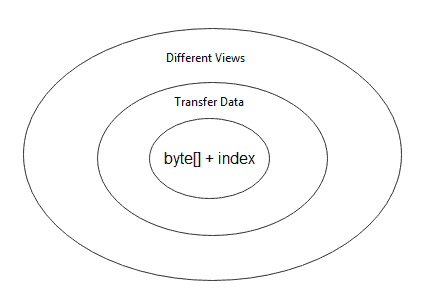
2.3. 洋葱模型
理解 ByteBuffer 可视为三层洋葱模型(由内到外):
- 数据与索引层:字节数组 + 位置标记
- 数据传输层:与其他数据类型交互
- 视图层:多角度解析底层数据
3. ByteBuffer 索引机制
ByteBuffer 本质是带索引的字节数组容器:
ByteBuffer = byte array + index
核心索引分为四类:
3.1. 四大基础索引
| 索引 | 说明 | 约束关系 |
|---|---|---|
| Capacity | 缓冲区最大容量(不可变) | mark <= position <= limit <= capacity |
| Limit | 读/写操作的边界 | |
| Position | 当前读/写位置 | |
| Mark | 记忆的位置(未定义时为 -1) |
初始状态示例:
ByteBuffer buffer = ByteBuffer.allocate(10); // position=0, limit=10, capacity=10
动态修改:
buffer.position(2); // 设置 position=2
buffer.limit(5); // 设置 limit=5
3.2. 标记与重置(Mark/Reset)
ByteBuffer buffer = ByteBuffer.allocate(10); // mark=-1, position=0
buffer.position(2); // mark=-1, position=2
buffer.mark(); // mark=2, position=2
buffer.position(5); // mark=2, position=5
buffer.reset(); // mark=2, position=2
警告:未定义 mark 时调用
reset()会抛InvalidMarkException。
3.3. 四个关键方法对比
| 方法 | 操作效果 | 典型场景 |
|---|---|---|
clear() |
limit=capacity, position=0, mark=-1 |
重用缓冲区(写模式) |
flip() |
limit=position, position=0, mark=-1 |
切换读模式(避免重复调用!) |
rewind() |
position=0, mark=-1(limit不变) |
重新读取数据 |
compact() |
复制未读数据到头部,position=剩余量, limit=capacity |
部分复用缓冲区 |
代码示例:
ByteBuffer buffer = ByteBuffer.allocate(10); // 初始状态
buffer.position(2).mark().position(5).limit(8); // 预处理状态
buffer.clear(); // 重置为初始状态
buffer.flip(); // 切换读模式(limit=5)
buffer.rewind(); // 回到起始位置(limit=8)
buffer.compact(); // 压缩未读数据(position=3)
3.4. 剩余操作(Remain)
boolean hasMore = buffer.hasRemaining(); // 是否还有剩余元素
int remaining = buffer.remaining(); // 剩余元素数量
示例:
ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.position(2).limit(8);
boolean flag = buffer.hasRemaining(); // true
int remaining = buffer.remaining(); // 6 (8-2)
4. 数据传输
ByteBuffer 支持与其他基本类型(除 boolean)交互:
4.1. 字节传输
单字节操作:
byte b = buffer.get(); // 从 position 读取并 position++
buffer.put((byte) 1); // 写入到 position 并 position++
byte b = buffer.get(5); // 读取索引 5(不改变 position)
buffer.put(5, (byte) 1); // 写入索引 5(不改变 position)
批量操作:
byte[] dst = new byte[10];
buffer.get(dst); // 批量读取到 dst
buffer.put(new byte[]{1,2,3}); // 批量写入
buffer.put(ByteBuffer.allocate(5)); // 从另一个缓冲区传输
4.2. 整型传输(以 int 为例)
int value = buffer.getInt(); // 读取 int(4字节)
buffer.putInt(123456); // 写入 int
int value = buffer.getInt(2); // 从索引 2 读取 int
buffer.putInt(2, 123456); // 写入到索引 2
原理:所有非字节类型都通过字节组合实现,需注意字节序(后文详述)。
5. 多视图解析
同一底层数据可通过不同视图解析:
5.1. ByteBuffer 视图
| 方法 | 新视图特性 | 共享数据 |
|---|---|---|
duplicate() |
独立索引,完整数据 | 是 |
slice() |
从当前位置开始的子区域(position=0) | 是 |
asReadOnlyBuffer() |
独立索引,只读 | 是 |
示例:
ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.position(2).mark().position(5).limit(8);
ByteBuffer dup = buffer.duplicate(); // 复制完整状态
ByteBuffer slice = buffer.slice(); // 子区域(capacity=3)
ByteBuffer ro = buffer.asReadOnlyBuffer(); // 只读副本
5.2. 类型化视图
将字节解释为其他类型:
IntBuffer intBuffer = buffer.asIntBuffer(); // 视图容量 = 剩余字节数 / 4
LongBuffer longBuffer = buffer.asLongBuffer(); // 视图容量 = 剩余字节数 / 8
关键点:
- 从当前 position 开始解析
- 视图容量 =
floor(剩余字节数 / 类型字节数) - 末尾不足的字节被忽略
示例:
byte[] bytes = {
(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE, // 第一个 int
(byte) 0xF0, (byte) 0x07, (byte) 0xBA, (byte) 0x11, // 第二个 int
(byte) 0x0F, (byte) 0xF1, (byte) 0xCE // 剩余 3 字节被忽略
};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
IntBuffer intBuffer = buffer.asIntBuffer();
int capacity = intBuffer.capacity(); // 2 (11字节 / 4 = 2)
6. 直接缓冲区(Direct Buffer)
6.1. 核心概念
- 非直接缓冲区:数据在 JVM 堆内存(字节数组)
- 直接缓冲区:数据在操作系统本地内存(JVM 可直接访问)
创建方式:
ByteBuffer directBuffer = ByteBuffer.allocateDirect(1024);
6.2. 性能权衡
优势:
- 避免 JVM 堆内存 → 本地内存的拷贝
- 提升 I/O 操作效率(特别是大文件/网络传输)
劣势:
- 分配/回收成本高
- 不受 GC 管理(需手动释放)
实践建议:先实现功能,通过性能分析确定瓶颈后再考虑直接缓冲区。
7. 辅助方法
7.1. 类型判断方法
boolean isDirect = buffer.isDirect(); // 是否直接缓冲区
boolean isReadOnly = buffer.isReadOnly(); // 是否只读
注意:包装缓冲区(
wrap()创建)总是非直接缓冲区。
7.2. 数组访问方法
boolean hasArray = buffer.hasArray(); // 是否有可访问的底层数组
byte[] array = buffer.array(); // 获取底层数组(需 hasArray=true)
int offset = buffer.arrayOffset(); // 数组偏移量
限制:直接缓冲区或只读缓冲区无法访问数组。
7.3. 字节序(Byte Order)
buffer.order(ByteOrder.BIG_ENDIAN); // 设置大端序(默认)
buffer.order(ByteOrder.LITTLE_ENDIAN); // 设置小端序
ByteOrder currentOrder = buffer.order(); // 获取当前字节序
影响示例:
byte[] bytes = {(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
buffer.order(ByteOrder.BIG_ENDIAN);
int bigEndianVal = buffer.getInt(); // -889275714 (0xCAFEBABE)
buffer.order(ByteOrder.LITTLE_ENDIAN);
int littleEndianVal = buffer.getInt(); // -1095041334 (0xBEBAFECA)
7.4. 缓冲区比较
比较规则:仅比较 [position, limit) 区间的剩余元素。
byte[] bytes1 = "World".getBytes();
byte[] bytes2 = "HelloWorld".getBytes();
ByteBuffer buf1 = ByteBuffer.wrap(bytes1);
ByteBuffer buf2 = ByteBuffer.wrap(bytes2).position(5); // 跳过 "Hello"
boolean equal = buf1.equals(buf2); // true (剩余数据都是 "World")
int cmpResult = buf1.compareTo(buf2); // 0 (内容相同)
8. 总结
本文通过洋葱模型分层解析了 ByteBuffer:
- 核心层:掌握四大索引(capacity/limit/position/mark)及关键方法(flip/clear/compact)
- 传输层:理解字节与其他类型的转换机制
- 视图层:利用多视角解析同一数据
实践要点:
- 优先使用非直接缓冲区,性能瓶颈时再考虑直接缓冲区
- 注意字节序对多字节类型解析的影响
- 善用视图操作简化数据处理逻辑
开发哲学:先保证正确性,再优化性能——这是经久不衰的黄金法则。