1. 概述
像归并排序这类通用排序算法不对输入数据做任何假设,因此在最坏情况下它们的时间复杂度无法突破 *O(n log n)*。而计数排序则不同,它对输入数据有特定前提假设,这使得它能在 O(n) 线性时间内完成排序。
本文将深入剖析计数排序的核心机制,并用 Java 实现该算法,帮助你在合适场景下“简单粗暴”地提升性能。
2. 计数排序原理
与大多数基于比较的排序算法不同,计数排序 不通过元素间比较来排序。它的核心前提是:输入数组中的元素是范围在 [0, k] 内的 n 个整数。当 k = O(n) 时,计数排序的时间复杂度就是 *O(n)*。
⚠️ 注意:这意味着计数排序无法作为通用排序工具。但一旦输入满足条件,它的性能非常惊艳。
2.1 频率数组与前缀和
假设我们要排序的数组如下,元素范围是 [0, 5]:

第一步是统计每个数字的出现次数。我们用数组 C 表示,其中 C[i] 就是数字 i 在原数组中的频次:
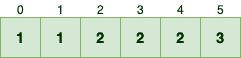
例如,数字 5 出现了 3 次,所以 C[5] = 3。
接下来关键一步:计算每个数字有多少个元素小于或等于它。这可以通过对 C 数组做前缀和实现:
<= 0的元素有C[0]个<= 1的元素有C[0] + C[1]个<= 2的元素有C[0] + C[1] + C[2]个
因此,只需遍历累加,就能得到最终的 C 数组:
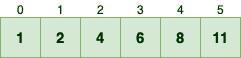
此时 C[i] 的含义变为:值小于等于 i 的元素个数。
2.2 排序过程
有了 C 数组,就可以开始排序了。算法步骤如下:
- ✅ 从原数组末尾开始逆序遍历
- ✅ 对于当前元素
i,C[i] - 1就是它在结果数组中的正确位置(因为数组下标从 0 开始) - ✅ 将元素放入结果数组后,
C[i]减 1,为下一个相同值的元素腾位置
以原数组最后一个元素 5 为例:
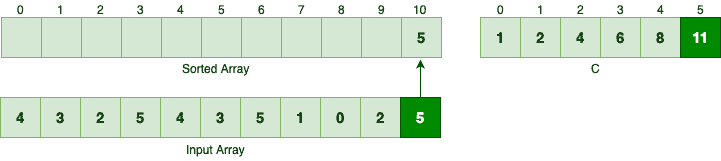
C[5] = 11,说明有 11 个数 ≤ 5,所以 5 应放在索引 10 处。放置后 C[5] 减为 10。
接着处理 2:
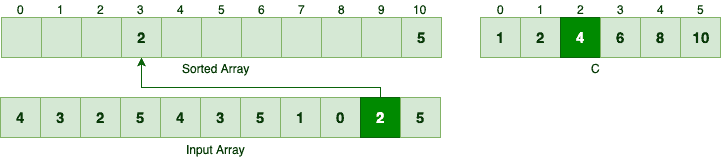
C[2] = 4,所以 2 放在索引 3 处,然后 C[2] 减为 3。
再处理 0:
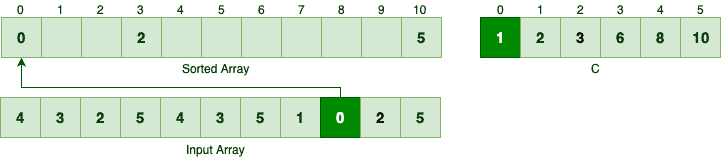
C[0] = 1,放在索引 0,然后 C[0] 减为 0。
继续逆序处理所有元素,最终得到有序数组:

3. Java 实现
3.1 构建频率数组
int[] countElements(int[] input, int k) {
int[] c = new int[k + 1];
Arrays.fill(c, 0);
for (int i : input) {
c[i] += 1;
}
for (int i = 1; i < c.length; i++) {
c[i] += c[i - 1];
}
return c;
}
说明:
input:待排序数组k:数组中最大值(范围 [0, k])- 返回
C数组,即前缀和后的频次数组
测试验证:
@Test
void countElements_GivenAnArray_ShouldCalculateTheFrequencyArrayAsExpected() {
int k = 5;
int[] input = { 4, 3, 2, 5, 4, 3, 5, 1, 0, 2, 5 };
int[] c = CountingSort.countElements(input, k);
int[] expected = { 1, 2, 4, 6, 8, 11 };
assertArrayEquals(expected, c);
}
3.2 执行排序
int[] sort(int[] input, int k) {
int[] c = countElements(input, k);
int[] sorted = new int[input.length];
for (int i = input.length - 1; i >= 0; i--) {
int current = input[i];
sorted[c[current] - 1] = current;
c[current] -= 1;
}
return sorted;
}
关键点:
- 逆序遍历确保稳定性
c[current] - 1是目标索引c[current]--保证相同元素的正确位置分配
测试验证:
@Test
void sort_GivenAnArray_ShouldSortTheInputAsExpected() {
int k = 5;
int[] input = { 4, 3, 2, 5, 4, 3, 5, 1, 0, 2, 5 };
int[] sorted = CountingSort.sort(input, k);
// 与 Java 自带排序对比
Arrays.sort(input);
assertArrayEquals(input, sorted);
}
4. 算法再分析
4.1 时间复杂度
计数排序不是比较排序,因此不受 O(n log n) 下限约束。
总时间复杂度分析:
- 构建频次数组:O(n)
- 计算前缀和:O(k)
- 填充结果数组:O(n)
✅ 总时间复杂度:O(n + k)
当 k = O(n) 时,复杂度退化为 **O(n)**,实现线性排序。
4.2 稳定性与关键细节
我们之前强调要 逆序遍历 和 **使用后递减 C[i]**,原因如下:
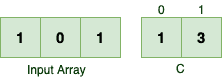
❌ 正序遍历的问题
如果从数组开头正序处理:
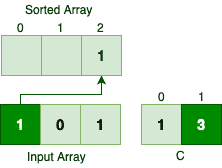
第一个 1 会被放到 C[1]-1 = 1 位置:
第二个 1 也会被放到 C[1]-1 = 1 位置(因为没递减),导致覆盖或错位。
相同元素的相对顺序被破坏,算法不再稳定。
❌ 不递减 C[i] 的问题
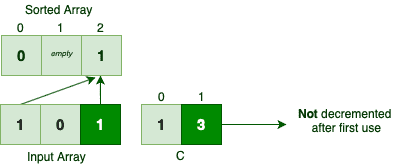
所有相同值都会尝试放入同一个位置,造成数据丢失或覆盖。
✅ 所以:逆序 + 递减 = 稳定排序
5. 总结
本文详细解析了计数排序的实现原理与 Java 代码实现。关键点回顾:
- ✅ 适用于小范围整数排序([0, k] 且 k ≈ n)
- ✅ 时间复杂度 O(n + k),k 较小时接近线性
- ✅ 是稳定的排序算法
- ✅ 核心是频次统计 + 前缀和 + 逆序填充
项目代码已上传至 GitHub:https://github.com/baeldung/tutorials/tree/master/algorithms-modules/algorithms-sorting
实际开发中若遇到整数范围有限的排序需求,不妨试试这个“冷门但高效”的算法,说不定能帮你轻松踩过性能瓶颈。