2. 什么是容错机制?
无论我们如何精心构建应用,总会有出错的可能。很多时候,这些错误超出了我们的控制范围 —— 比如调用的远程服务突然不可用。因此,我们必须构建能够容忍这些故障的应用程序,为用户提供最佳体验。
我们可以通过多种方式应对这些故障,具体取决于执行的操作和故障类型。例如,当我们调用一个已知存在间歇性故障的远程服务时,可以重试调用,期望能成功。或者,我们可以尝试调用另一个提供相同功能的服务。
还有一些代码结构设计可以避免这些情况。例如,限制对同一远程服务的并发调用数量,可以减轻其负载压力。
3. 依赖配置
在使用Failsafe之前,我们需要在构建文件中添加最新版本,本文写作时为3.3.2。
如果使用Maven,在pom.xml中添加:
<dependency>
<groupId>dev.failsafe</groupId>
<artifactId>failsafe</artifactId>
<version>3.3.2</version>
</dependency>
如果使用Gradle,在build.gradle中添加:
implementation("dev.failsafe:failsafe:3.3.2")
现在我们就可以在应用中使用Failsafe了。
4. 使用Failsafe执行操作
Failsafe基于策略(policy)概念工作。每个策略会判断操作是否失败,并定义如何响应失败。
4.1. 失败判定
默认情况下,策略将抛出任何Exception的操作视为失败。但我们可以配置策略只处理特定类型的异常,通过异常类型或lambda表达式检查:
policy
.handle(IOException.class)
.handleIf(e -> e instanceof IOException)
还可以配置策略将特定返回结果视为失败,通过具体值或lambda表达式检查:
policy
.handleResult(null)
.handleResultIf(result -> result < 0)
默认策略会将所有异常视为失败。如果添加了异常处理,会替换默认行为;而添加结果处理会作为异常处理的补充。所有检查条件是叠加的 —— 只要任一条件满足,策略就判定操作失败。
4.2. 组合策略
定义好策略后,可以构建执行器(executor)。这是执行功能并获取结果的手段 —— 可能是操作的实际结果,也可能是策略修改后的结果。 可以通过*Failsafe.with()传入所有策略,或使用compose()*方法扩展:
Failsafe.with(defaultFallback, npeFallback, ioFallback)
.compose(timeout)
.compose(retry);
可按需添加任意数量的策略,策略按添加顺序执行,每个策略包裹下一个策略。上述代码的执行顺序如下:
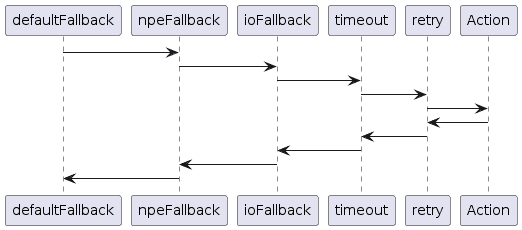
每个策略会根据被包裹策略或操作的异常/返回值做出适当响应。例如,上述代码将超时策略应用于所有重试尝试。我们也可以调整顺序,使超时策略单独应用于每次重试。
4.3. 执行操作
组合策略后,Failsafe返回一个FailsafeExecutor实例。该实例提供多种方法执行操作,具体取决于要执行的内容和期望的返回方式。
最直接的执行方法是T get
区别在于:get()返回操作结果,而run()返回void —— 且操作本身也必须返回void:
Failsafe.with(policy).run(this::runSomething);
var result = Failsafe.with(policy).get(this::doSomething);
此外,还有多种异步执行方法,返回CompletableFuture。但本文不涉及异步内容。
5. Failsafe策略详解
现在我们了解了如何构建FailsafeExecutor执行操作,接下来需要构建具体策略。Failsafe提供了多种标准策略,均采用建造者模式简化构建过程。
5.1. 降级策略
最简单的策略是Fallback(降级)。当链式操作失败时,该策略允许提供替代结果。
最简单的用法是返回静态值:
Fallback<Integer> policy = Fallback.builder(0).build();
此策略在操作因任何原因失败时返回固定值"0"。
也可以使用CheckedRunnable或CheckedSupplier生成替代值。根据需求,可能只是记录日志后返回固定值,也可能执行完全不同的逻辑:
Fallback<Result> backupService = Fallback.of(this::callBackupService)
.build();
Result result = Failsafe.with(backupService)
.get(this::callPrimaryService);
这里会先执行*callPrimaryService()。失败时自动执行callBackupService()*尝试获取结果。
最后,可以使用*Fallback.ofException()*在失败时抛出特定异常。这能将所有配置的失败原因统一为单个预期异常:
Fallback<Result> throwOnFailure = Fallback.ofException(e -> new OperationFailedException(e));
5.2. 重试策略
与Fallback提供替代结果不同,Retry策略允许简单重试原始操作。
无配置时,该策略最多调用操作3次,成功则返回结果,否则抛出FailsafeException:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder().build();
这已很有用 —— 对偶发性故障的操作,可以在放弃前重试几次。
但我们可以进一步配置行为。首先使用*withMaxAttempts()*调整重试次数:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(5)
.build();
现在最多执行5次操作(默认3次)。
还可以配置每次重试间的固定延迟。这对短暂性故障(如网络抖动)很有用:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withDelay(Duration.ofMillis(250))
.build();
更复杂的变体是*withBackoff()*,配置递增延迟:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(20)
.withBackoff(Duration.ofMillis(100), Duration.ofMillis(2000))
.build();
首次失败后延迟100毫秒,第20次失败后延迟2000毫秒,中间失败延迟逐渐增加。
5.3. 超时策略
与Fallback和Retry帮助获取成功结果不同,Timeout策略相反 —— 当操作耗时过长时强制失败。 当需要因操作过慢而失败时,这非常有用。
构建Timeout时需指定目标持续时间,超过该时间操作将失败:
Timeout<Object> timeout = Timeout.builder(Duration.ofMillis(100)).build();
默认情况下,操作会执行完成,然后检查是否超时。
也可配置在超时时中断操作,而非等待完成:
Timeout<Object> timeout = Timeout.builder(Duration.ofMillis(100))
.withInterrupt()
.build();
Timeout策略可与Retry策略组合使用。如果超时策略包裹重试策略,超时时间将覆盖所有重试:
Timeout<Object> timeoutPolicy = Timeout.builder(Duration.ofSeconds(10))
.withInterrupt()
.build();
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(20)
.withBackoff(Duration.ofMillis(100), Duration.ofMillis(2000))
.build();
Failsafe.with(timeoutPolicy, retryPolicy).get(this::perform);
这会最多尝试20次操作,每次尝试间延迟递增,但总执行时间超过10秒则放弃。
反之,如果重试策略包裹超时策略,每次单独尝试都有超时限制:
Timeout<Object> timeoutPolicy = Timeout.builder(Duration.ofMillis(500))
.withInterrupt()
.build();
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(5)
.build();
Failsafe.with(retryPolicy, timeoutPolicy).get(this::perform);
这会尝试5次操作,每次超过500毫秒则取消。
5.4. 隔离策略
目前看到的策略都是控制应用如何响应故障。但有些策略可以从源头减少故障发生概率。
隔离策略(Bulkhead)用于限制操作的并发执行次数。这能减轻外部服务负载,从而降低其故障概率。
构建Bulkhead时需配置最大并发执行数:
Bulkhead<Object> bulkhead = Bulkhead.builder(10).build();
默认情况下,当隔离舱已满时,新操作会立即失败。
也可配置隔离舱让新操作等待,有空闲容量时执行等待的任务:
Bulkhead<Object> bulkhead = Bulkhead.builder(10)
.withMaxWaitTime(Duration.ofMillis(1000))
.build();
任务按执行顺序通过隔离舱,一旦有空闲容量立即执行。等待时间超过配置值的任务会失败,但后续任务可能成功执行。
5.5. 限流策略
与隔离策略类似,限流策略(Rate Limiter)也限制操作执行次数。但隔离策略只跟踪当前执行的操作数,而限流策略限制单位时间内的操作数。
Failsafe提供两种限流器:突发型(bursty)和平滑型(smooth)。
突发型限流器使用固定时间窗口,允许窗口内最多执行次数:
RateLimiter<Object> rateLimiter = RateLimiter.burstyBuilder(100, Duration.ofSeconds(1))
.withMaxWaitTime(Duration.ofMillis(200))
.build();
此配置允许每秒执行100次操作。配置了等待时间,操作会阻塞直到执行或失败。称为"突发型"是因为计数在窗口结束时重置,允许操作突然重新开始执行。
特别是配置等待时间后,所有阻塞的操作在限流窗口结束时都会突然执行。
平滑型限流器则将执行分散到整个时间窗口:
RateLimiter<Object> rateLimiter = RateLimiter.smoothBuilder(100, Duration.ofSeconds(1))
.withMaxWaitTime(Duration.ofMillis(200))
.build();
配置类似,但执行会被平滑分布。即不是1秒内允许100次执行,而是每1/100秒允许1次执行。超过此速率的操作会触发等待或失败。
5.6. 熔断策略
与其他策略不同,熔断器(Circuit Breaker)让应用在操作被认为已失败时快速失败。 例如,调用远程服务时若已知其无响应,则无需尝试 —— 可立即失败,避免浪费时间和资源。
熔断器采用三态系统。默认状态为关闭(Closed),所有操作正常执行。但当足够多的操作失败时,熔断器转为开启(Open)状态。
开启状态不执行任何操作,所有调用立即失败。熔断器保持此状态一段时间后转为半开(Half-Open)状态。
半开状态会尝试执行操作,但使用不同的失败阈值决定转为关闭还是开启状态。
例如:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureThreshold(7, 10)
.withDelay(Duration.ofMillis(500))
.withSuccessThreshold(4, 5)
.build();
此配置在最近10次请求中7次失败时转为开启状态;500毫秒后转为半开状态;最近5次请求中4次成功时转为关闭状态,2次失败则转回开启状态。
也可配置基于时间的失败阈值。例如,30秒内5次失败则开启熔断:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureThreshold(5, Duration.ofSeconds(30))
.build();
还可配置为请求百分比而非固定次数。例如,5分钟内至少100次请求中失败率达20%则开启熔断:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureRateThreshold(20, 100, Duration.ofMinutes(5))
.build();
这能更快适应负载变化。低负载时可能无需检查故障,高负载时故障概率增加,只在超过阈值时才触发熔断。
6. 总结
本文全面介绍了Failsafe库。该库功能远不止于此,不妨亲自尝试探索更多可能性!