1. 概述
本文将深入讲解梯度下降(Gradient Descent)算法的基本原理,并通过 Java 实现一个简单但实用的版本。我们会逐步图解算法执行过程,帮助你理解其核心思想——如何“下山”找到局部最优解。
✅ 适合有一定算法和数学基础的开发者
✅ 重点在于理解迭代逻辑与工程实现
❌ 不涉及复杂的微积分推导(但你会看到它的影子)
代码已开源,可在 GitHub 获取完整示例:https://github.com/baeldung/algorithms-java-gradient-descent
2. 什么是梯度下降?
梯度下降是一种用于寻找函数局部最小值的优化算法,在机器学习中被广泛用于最小化损失函数(loss function)。
你可以把它想象成一个人蒙着眼睛从山顶往下走,每一步都沿着最陡的坡往下迈,目标是尽快到达谷底。
- ✅ “梯度” 就是斜率(slope),表示函数变化最快的方向
- ✅ “下降” 意味着我们朝着减少函数值的方向前进
- ⚠️ 它找到的是局部最小值,不一定是全局最优解,起始点不同结果可能完全不同
举个例子:如果你从山的左边出发,可能走到一个小坑就停了;但从右边出发,却能一路走到真正的谷底。
3. 梯度下降的关键特性
以下是该算法的核心特点,理解这些有助于避免踩坑:
✅ 寻找局部最小值
起始点(initial point)直接影响最终结果。不同起点可能导致收敛到不同的极小值。✅ 迭代式推进
算法不会一步到位,而是通过多次小步调整,逐步逼近最小值。✅ 采用回溯策略(backtracking)
当前步导致函数值上升时,说明“迈过头了”,需要调转方向并缩小步长。这种自适应调整让算法更鲁棒。
🔍 提示:本文实现的是无需导数的梯度下降变体,因此适用于不可导函数,工程上更灵活。
4. 算法执行步骤图解
我们以如下函数为例:
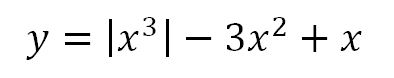
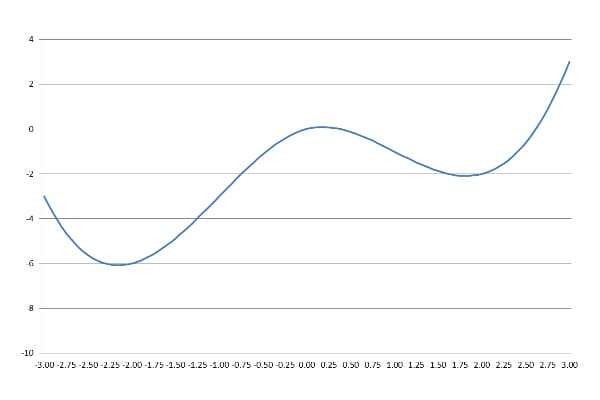
对应图像如下:
步骤分解
假设我们从 x = 1 开始:
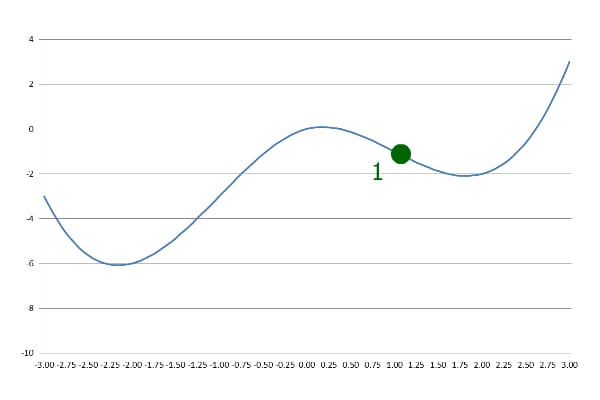
第一步:沿斜坡下行
使用预设步长向前移动一步: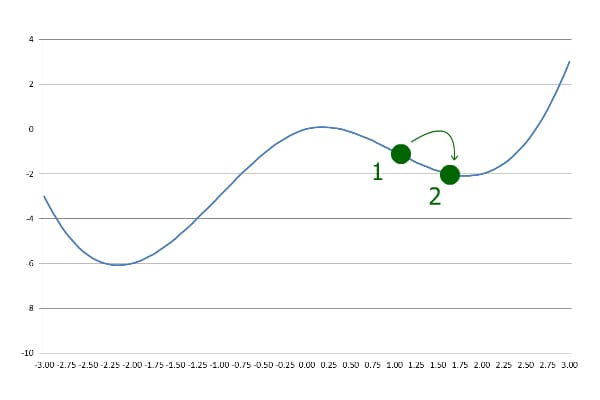
第二步:继续前进
继续用相同步长前进,但这次y值变大了: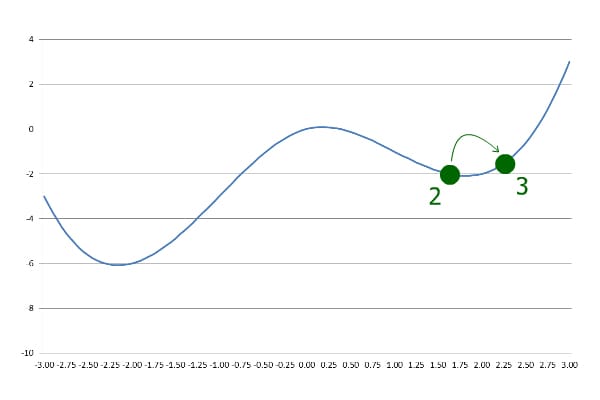
❌ 这说明我们“跨过了”最低点!
第三步:回退并调整步长
发现y上升后,立即反向并减半步长: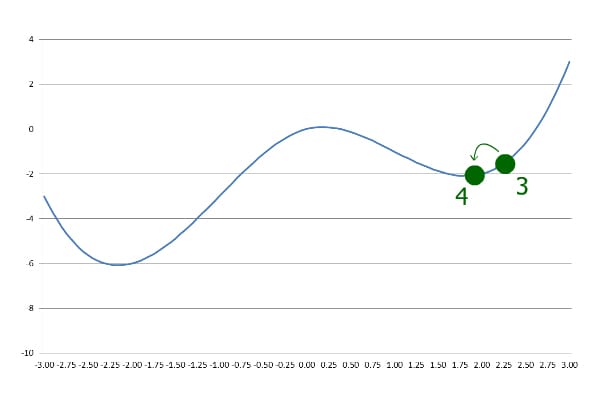
后续迭代:持续逼近
每当currentY > previousY,就反向 + 缩小步长,直到步长小于设定精度为止。
关键观察
- 最终找到的是局部最小值,而非全局最小值
- 若从
x = -1起始,反而能找到全局最小值 - ✅ 起始点敏感 → 实际训练中常需多次尝试或随机初始化
5. Java 实现详解
下面是一个简洁、可运行的 Java 实现。我们不依赖函数导数,而是通过函数值变化来判断方向,因此更具通用性。
5.1 核心参数定义
double precision = 0.000001; // 收敛精度
double stepCoefficient = 0.1; // 初始步长系数
int maxIterations = 100; // 最大迭代次数,防死循环
⚠️
precision控制算法何时停止;maxIterations是安全阀,防止无限循环。
5.2 初始步处理
首次迭代没有历史数据对比,需试探方向:
double previousX = initialX;
double previousY = f.apply(previousX);
double currentX = previousX + stepCoefficient * previousY;
说明:
f是Function<Double, Double>类型,代表目标函数initialX是用户指定的起始点- 正的
stepCoefficient表示先尝试向右走
5.3 主循环逻辑
while (Math.abs(currentX - previousX) > precision && maxIterations > 0) {
maxIterations--;
double currentY = f.apply(currentX);
if (currentY > previousY) {
// 走过头了,反向并减半步长
stepCoefficient = -stepCoefficient / 2;
}
previousX = currentX;
previousY = currentY;
currentX += stepCoefficient * previousY;
}
✅ 关键逻辑解析
| 条件 | 动作 | 目的 |
|---|---|---|
currentY > previousY |
stepCoefficient = -stepCoefficient / 2 |
回退 + 减速,避免震荡 |
| 否则 | 继续同方向前进 | 加速收敛 |
- 使用
previousY作为“梯度”近似(相当于用函数值代替导数) - 步长自动衰减,无需手动调度学习率
5.4 完整方法签名示例
public static double gradientDescent(Function<Double, Double> f, double initialX) {
double precision = 0.000001;
double stepCoefficient = 0.1;
int maxIterations = 100;
double previousX = initialX;
double previousY = f.apply(previousX);
double currentX = previousX + stepCoefficient * previousY;
double previousStep = Math.abs(currentX - previousX);
while (previousStep > precision && maxIterations > 0) {
maxIterations--;
double currentY = f.apply(currentX);
if (currentY > previousY) {
stepCoefficient = -stepCoefficient / 2;
}
previousX = currentX;
currentY = f.apply(currentX); // 重新计算确保一致性
currentX += stepCoefficient * previousY;
previousY = currentY;
previousStep = Math.abs(currentX - previousX);
}
return currentX;
}
5.4 使用示例
// 示例函数:f(x) = (x - 3)^2,最小值在 x=3
Function<Double, Double> f = x -> Math.pow(x - 3, 2);
double min = gradientDescent(f, 1.0);
System.out.println("Found minimum at x = " + min); // 输出接近 3.0
6. 总结
本文通过图解 + Java 实现的方式,带你完整走了一遍梯度下降的执行流程。
核心要点回顾
- ✅ 梯度下降本质是“下山找谷底”
- ✅ 找到的是局部最小值,受初始点影响大
- ✅ 回溯机制让算法更稳定,适合非光滑函数
- ✅ 我们的实现不依赖导数,工程上更易落地
实际应用建议
- 在机器学习中,通常结合真实梯度(导数)进行更新
- 对于复杂模型,可考虑使用 Adam、SGD 等高级优化器
- 本文实现适合教学和简单场景,生产环境建议使用成熟库(如 DL4J、Weka)
💡 小技巧:调试时打印每一步的
x和y,能快速发现是否震荡或发散。
完整代码已托管至 GitHub:https://github.com/baeldung/algorithms-java-gradient-descent
欢迎 fork 学习或扩展更多功能。