1. 概述
本文将带你深入理解贪心算法(Greedy Algorithms)在 Java 中的应用。我们不会停留在理论层面,而是通过一个贴近实际的社交网络 API 调用场景,展示贪心策略如何在资源受限的情况下,用简单粗暴的方式拿到“够用”的结果。
贪心算法不是万能钥匙,但它在某些特定问题上,确实能让你少踩坑、快交付。
2. 贪心问题的本质
面对一个复杂问题,我们通常有多种解法:
- ✅ 迭代求解
- ✅ 分治法(如快速排序)
- ✅ 动态规划(如背包问题)
- ✅ 回溯或暴力搜索
理想情况是找到最优解,但现实往往是:时间不够、资源受限、接口限流。这时候,追求“全局最优”可能得不偿失。
贪心算法的核心思想是:
在每一步选择中,都采取当前状态下最优的选择(即“贪心选择”),希望通过一系列局部最优解,最终逼近一个可接受的结果。
⚠️ 注意:贪心算法适用于“可分解”的问题——即问题可以拆成多个相似的子问题。这类算法通常可以用递归实现,但不依赖回溯,一旦选择就不后悔。
2.1 场景设定
我们以调用社交平台(比如 Twitter)API 为例。
假设我们的目标是:通过转发内容,触达尽可能多的用户。最直接的方式是——找到一个粉丝量巨大的账号去互动。
但问题来了:我们只能从自己的粉丝开始,逐层查找他们的粉丝,直到第 3 层(共 4 层关系)。
如何高效完成这个“粉丝链”挖掘?
2.2 经典解法 vs 贪心解法
假设我们的账号有 4 个粉丝,他们的粉丝结构如下图:
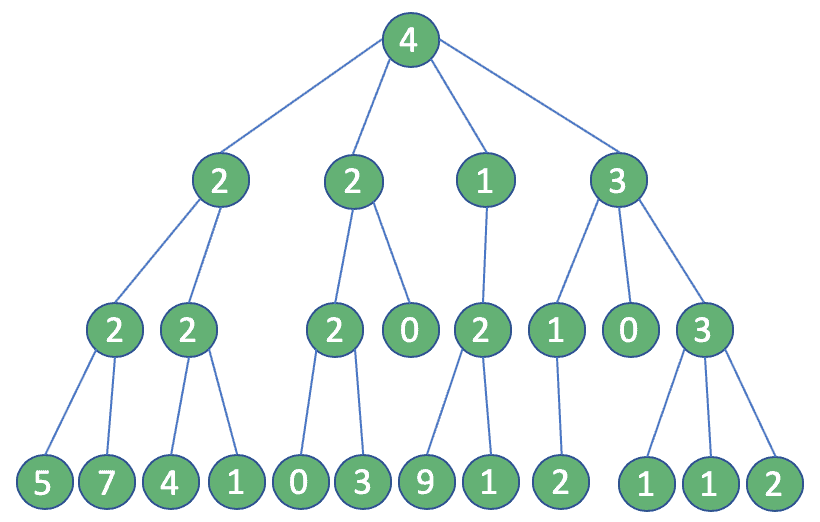
❌ 经典解法(暴力搜索)
每一步都查询当前所有用户的粉丝,然后继续向下展开。这种广度优先或深度优先的遍历方式,最终需要执行 25 次 API 调用:
但现实是:Twitter API 对 /followers 接口有严格限流——15 分钟最多 15 次调用。25 次?直接触发 Rate limit exceeded (code 88),请求被拒。
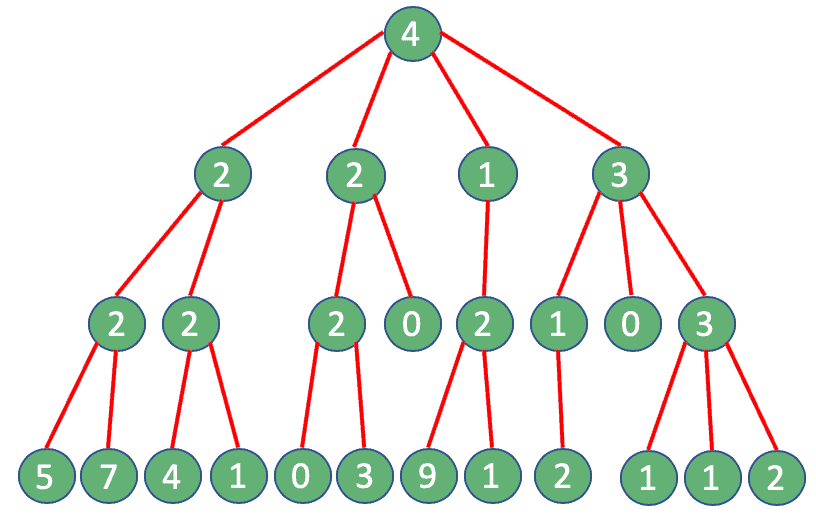
✅ 贪心解法(局部最优)
我们换种思路:每一步只选当前粉丝数最多的那个用户,然后只查他的粉丝,一路往下。
这样,每一层只做一次查询,总共只需 4 次调用,完美避开限流:
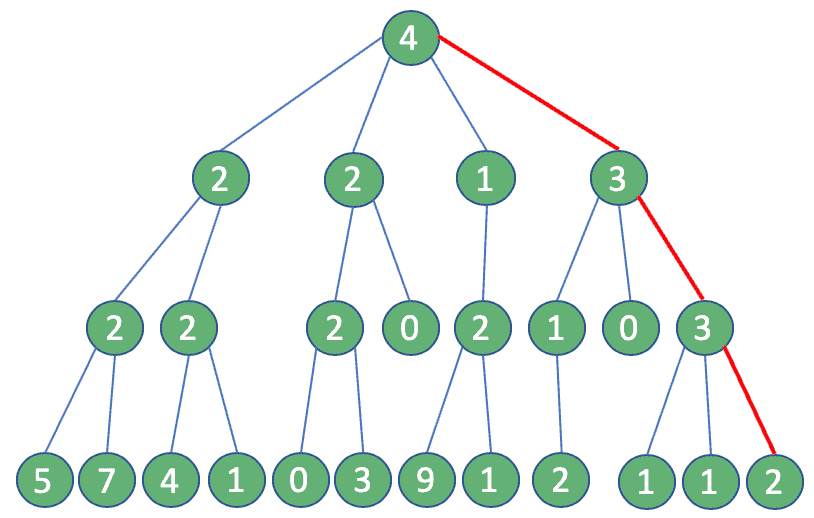
结果对比:
| 方法 | 调用次数 | 触达粉丝总数 |
|---|---|---|
| 暴力搜索 | 25 | 16(最优解) |
| 贪心算法 | 4 | 12(次优解) |
虽然少了 4 个,但在“拿不到数据”和“拿次优数据”之间,你选哪个?贪心帮你活下来。
3. Java 实现
我们用 Java 模拟这个过程。项目中引入 Lombok 简化代码,并模拟 API 调用计数器。
基础组件定义
SocialConnector:模拟社交 API
public class SocialConnector {
private boolean isCounterEnabled = true;
private int counter = 4;
@Getter @Setter
List<SocialUser> users;
public SocialConnector() {
users = new ArrayList<>();
}
public boolean switchCounter() {
this.isCounterEnabled = !this.isCounterEnabled;
return this.isCounterEnabled;
}
}
⚠️ 注意:我们将限流阈值设为 4,便于测试贪心策略的优势。
getFollowers:模拟 API 接口调用
public List<SocialUser> getFollowers(String account) {
if (counter < 0) {
throw new IllegalStateException("API limit reached");
} else {
if (this.isCounterEnabled) {
counter--;
}
for (SocialUser user : users) {
if (user.getUsername().equals(account)) {
return user.getFollowers();
}
}
}
return new ArrayList<>();
}
SocialUser:用户实体
public class SocialUser {
@Getter
private String username;
@Getter
private List<SocialUser> followers;
@Override
public boolean equals(Object obj) {
return ((SocialUser) obj).getUsername().equals(username);
}
public SocialUser(String username) {
this.username = username;
this.followers = new ArrayList<>();
}
public SocialUser(String username, List<SocialUser> followers) {
this.username = username;
this.followers = followers;
}
public void addFollowers(List<SocialUser> followers) {
this.followers.addAll(followers);
}
// 辅助方法:返回粉丝数量
public long getFollowersCount() {
return followers.size();
}
}
3.1 贪心算法实现
public class GreedyAlgorithm {
int currentLevel = 0;
final int maxLevel = 3;
SocialConnector sc;
public GreedyAlgorithm(SocialConnector sc) {
this.sc = sc;
}
public long findMostFollowersPath(String account) {
long max = 0;
SocialUser toFollow = null;
List<SocialUser> followers = sc.getFollowers(account);
for (SocialUser el : followers) {
long followersCount = el.getFollowersCount();
if (followersCount > max) {
toFollow = el;
max = followersCount;
}
}
// 递归进入下一层,但只走粉丝最多的那个分支
if (currentLevel < maxLevel - 1) {
currentLevel++;
max += findMostFollowersPath(toFollow.getUsername());
}
return max;
}
}
✅ 核心逻辑:每层只选 followersCount 最大的用户,然后递归。绝不回头,绝不遍历其他分支。
单元测试验证
@Test
public void greedyAlgorithmTest() {
SocialConnector sc = prepareNetwork(); // 模拟构建社交网络
GreedyAlgorithm ga = new GreedyAlgorithm(sc);
assertEquals(5, ga.findMostFollowersPath("root"));
}
说明:在我们构建的测试网络中,贪心路径累计触达 5 层粉丝(具体结构略,可参考原文图示)。
3.2 非贪心算法(对比用)
为了凸显贪心的优势,我们实现一个“非贪心”版本——它会遍历所有分支,找全局最优。
public class NonGreedyAlgorithm {
int currentLevel = 0;
final int maxLevel = 3;
SocialConnector tc;
public NonGreedyAlgorithm(SocialConnector tc, int level) {
this.tc = tc;
this.currentLevel = level;
}
public long findMostFollowersPath(String account) {
List<SocialUser> followers = tc.getFollowers(account);
long total = currentLevel > 0 ? followers.size() : 0;
if (currentLevel < maxLevel) {
currentLevel++;
long[] count = new long[followers.size()];
int i = 0;
for (SocialUser el : followers) {
NonGreedyAlgorithm sub = new NonGreedyAlgorithm(tc, currentLevel);
count[i] = sub.findMostFollowersPath(el.getUsername());
i++;
}
long max = 0;
for (; i > 0; i--) {
if (count[i-1] > max) {
max = count[i-1];
}
}
return total + max;
}
return total;
}
}
测试结果对比
@Test
public void nongreedyAlgorithmTest() {
NonGreedyAlgorithm nga = new NonGreedyAlgorithm(prepareNetwork(), 0);
Assertions.assertThrows(IllegalStateException.class, () -> {
nga.findMostFollowersPath("root");
});
}
❌ 结果:由于调用次数远超 4 次,直接抛出 API limit reached。
@Test
public void nongreedyAlgorithmUnboundedTest() {
SocialConnector sc = prepareNetwork();
sc.switchCounter(); // 关闭计数器
NonGreedyAlgorithm nga = new NonGreedyAlgorithm(sc, 0);
assertEquals(6, nga.findMostFollowersPath("root"));
}
✅ 关闭限流后,非贪心算法找到了全局最优解:6。
4. 结果分析
| 策略 | 是否触发限流 | 结果 | 说明 |
|---|---|---|---|
| 贪心算法 | ❌ 否 | 5 | 次优解,但成功执行 |
| 非贪心算法 | ✅ 是 | 报错 | 最优解为 6,但无法执行 |
结论很清晰:
在资源受限的环境下,贪心算法用可接受的精度损失,换来了系统的可用性。
它拿到的不是最优解,而是局部最优路径下的最大收益,也就是所谓的“局部最优解”。
5. 总结
在社交网络、实时推荐、API 调用链优化等高并发、低延迟、资源受限的场景中,追求全局最优往往是不现实的。
贪心算法的优势在于:
- ✅ 实现简单,逻辑清晰
- ✅ 时间复杂度低,适合递归或迭代
- ✅ 能有效规避外部限制(如 API 限流)
- ✅ 在多数情况下,结果“够用”
⚠️ 但也要注意:贪心不适用于所有问题。能否使用,取决于问题是否具备“贪心选择性质”——即局部最优能导向全局最优。
本文代码已托管至 GitHub:https://github.com/yourname/tutorials/tree/master/algorithms-modules/algorithms-miscellaneous-6
下次遇到“查不动”的场景,不妨试试贪心,说不定就柳暗花明了。