1. 概述
本文将介绍爬山算法(Hill-Climbing)的实现原理、代码示例及其优缺点。在深入算法前,我们先简要了解生成测试算法(Generate-And-Test)的核心思想。
2. 生成测试算法
这是最基础的搜索策略,核心步骤如下:
- 定义初始状态
- 对当前状态应用所有可能操作,生成新解
- 比较新解与目标状态
- 若达到目标或无法生成新状态则退出,否则返回步骤2
✅ 优点:实现简单,适合小规模问题
❌ 缺点:属于穷举搜索,空间复杂度高,不适用于大规模问题
该算法在生物识别领域被称为"大英博物馆算法"(比喻在博物馆中随机寻找文物),也是生成合成生物数据的理论基础。
3. 简单爬山算法详解
爬山算法的核心思想:从山脚出发,持续向上移动直至山顶。算法本质是生成测试算法的优化版,通过启发式函数(heuristic)评估状态质量,丢弃无希望的解。
核心公式:爬山算法 = 生成测试 + 启发式评估
算法流程:
- 初始化当前状态
- 循环直到达到目标或无法操作:
- 应用操作生成新状态
- 比较新状态与目标
- 达到目标则退出
- 用启发式函数评估新状态
- 若新状态更优,更新当前状态
⚠️ 关键点:通过迭代改进逐步逼近目标,"到达山顶"即找到最优解。
4. 算法示例
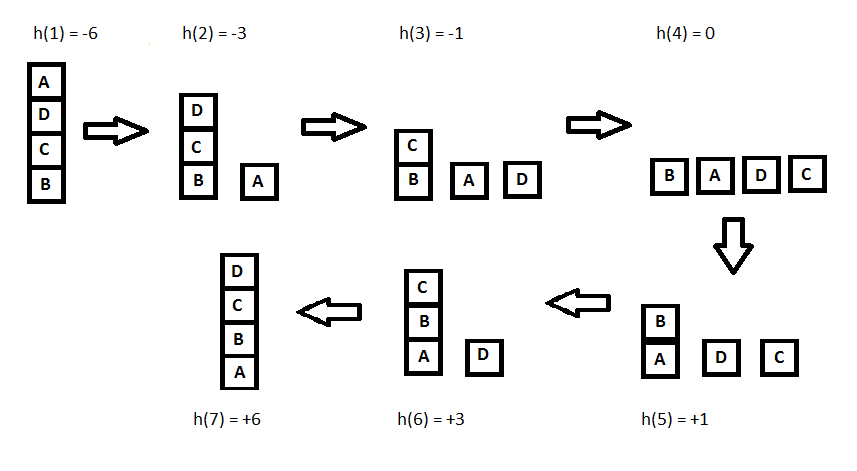
爬山算法属于启发式搜索,可解决N皇后等节点搜索问题。我们通过一个积木堆叠示例说明:
启发式函数定义:h(x) = 每个积木位置正确则+1,否则-1
(位置正确指支撑结构与目标状态一致)
状态迭代过程及启发值变化:
5. Java实现
首先定义状态类,存储积木堆栈和启发值:
public class State {
private List<Stack<String>> state;
private int heuristics;
// 拷贝构造器、setter/getter
}
启发值计算方法:
public int getHeuristicsValue(
List<Stack<String>> currentState, Stack<String> goalStateStack) {
return currentState.stream()
.mapToInt(stack ->
getHeuristicsValueForStack(stack, currentState, goalStateStack)
).sum();
}
public int getHeuristicsValueForStack(
Stack<String> stack,
List<Stack<String>> currentState,
Stack<String> goalStateStack) {
int stackHeuristics = 0;
boolean isPositionCorrect = true;
int goalStartIndex = 0;
for (String currentBlock : stack) {
if (isPositionCorrect
&& currentBlock.equals(goalStateStack.get(goalStartIndex))) {
stackHeuristics += goalStartIndex;
} else {
stackHeuristics -= goalStartIndex;
isPositionCorrect = false;
}
goalStartIndex++;
}
return stackHeuristics;
}
定义状态转移操作(两种方式):
- 创建新堆栈
- 移动到现有堆栈
private State pushElementToNewStack(
List<Stack<String>> currentStackList,
String block,
int currentStateHeuristics,
Stack<String> goalStateStack) {
State newState = null;
Stack<String> newStack = new Stack<>();
newStack.push(block);
currentStackList.add(newStack);
int newStateHeuristics
= getHeuristicsValue(currentStackList, goalStateStack);
if (newStateHeuristics > currentStateHeuristics) {
newState = new State(currentStackList, newStateHeuristics);
} else {
currentStackList.remove(newStack);
}
return newState;
}
private State pushElementToExistingStacks(
Stack currentStack,
List<Stack<String>> currentStackList,
String block,
int currentStateHeuristics,
Stack<String> goalStateStack) {
return currentStackList.stream()
.filter(stack -> stack != currentStack)
.map(stack ->
pushElementToStack(stack, block, currentStackList,
currentStateHeuristics, goalStateStack)
)
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
}
private State pushElementToStack(
Stack stack,
String block,
List<Stack<String>> currentStackList,
int currentStateHeuristics,
Stack<String> goalStateStack) {
stack.push(block);
int newStateHeuristics
= getHeuristicsValue(currentStackList, goalStateStack);
if (newStateHeuristics > currentStateHeuristics) {
return new State(currentStackList, newStateHeuristics);
}
stack.pop();
return null;
}
核心爬山算法实现:
public List<State> getRouteWithHillClimbing(
Stack<String> initStateStack, Stack<String> goalStateStack) throws Exception {
// 初始化状态...
List<State> resultPath = new ArrayList<>();
resultPath.add(new State(initState));
State currentState = initState;
boolean noStateFound = false;
while (
!currentState.getState().get(0).equals(goalStateStack)
|| noStateFound) {
noStateFound = true;
State nextState = findNextState(currentState, goalStateStack);
if (nextState != null) {
noStateFound = false;
currentState = nextState;
resultPath.add(new State(nextState));
}
}
return resultPath;
}
状态转移辅助方法:
public State findNextState(State currentState, Stack<String> goalStateStack) {
List<Stack<String>> listOfStacks = currentState.getState();
int currentStateHeuristics = currentState.getHeuristics();
return listOfStacks.stream()
.map(stack ->
applyOperationsOnState(listOfStacks, stack,
currentStateHeuristics, goalStateStack)
)
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
}
public State applyOperationsOnState(
List<Stack<String>> listOfStacks,
Stack<String> stack,
int currentStateHeuristics,
Stack<String> goalStateStack) {
State tempState;
List<Stack<String>> tempStackList
= new ArrayList<>(listOfStacks);
String block = stack.pop();
if (stack.size() == 0)
tempStackList.remove(stack);
tempState = pushElementToNewStack(
tempStackList, block, currentStateHeuristics, goalStateStack);
if (tempState == null) {
tempState = pushElementToExistingStacks(
stack, tempStackList, block,
currentStateHeuristics, goalStateStack);
stack.push(block);
}
return tempState;
}
6. 最陡爬山算法
这是爬山算法的变种(也称梯度搜索),核心区别:
- 简单爬山:选择第一个优于当前的状态
- 最陡爬山:评估所有可能状态,选择最优解
修改点:在状态转移时遍历所有操作结果,而非选择第一个可行解。
7. 算法缺陷与解决方案
爬山算法存在三大典型问题:
| 问题类型 | 特点描述 | 解决方案 |
|---|---|---|
| 局部最优 | 优于邻居但非全局最优 | 回溯、随机跳跃、多方向探索 |
| 平顶区域 | 邻居状态启发值相同 | 随机扰动、增加评估维度 |
| 山脊地带 | 需多步移动才能到达的高地 | 组合操作、路径规划 |
⚠️ 踩坑提示:在复杂问题中,单一启发式函数易陷入局部最优,建议结合其他算法使用。
8. 总结
爬山算法相比穷举搜索效率更高,但在大规模问题中仍非最优解。虽然可通过优化启发式函数提升决策质量,但会增加计算复杂度。实际应用中,建议将爬山算法与其他技术结合使用,取长补短。