1. 概述
聊天机器人系统通过提供快速智能的响应提升用户体验,让交互更高效。本教程将带你一步步使用Langchain4j和MongoDB Atlas构建聊天机器人。
LangChain4j是一个受LangChain启发的Java库,专为使用大语言模型(LLM)构建AI应用而设计。我们可以用它开发聊天机器人、摘要引擎或智能搜索系统等应用。
我们将使用MongoDB Atlas向量搜索为聊天机器人提供基于语义(而非仅关键词)的信息检索能力。传统关键词搜索依赖精确匹配,当用户用不同表述或同义词提问时,往往会导致不相关结果。
通过向量存储和向量搜索,应用将用户查询与存储内容映射到高维向量空间进行语义比较。这让聊天机器人能更准确地理解并响应复杂的自然语言问题,即使源内容中没有完全相同的词汇。最终我们实现了更上下文感知的结果。
2. AI聊天机器人应用架构
先看应用组件结构:
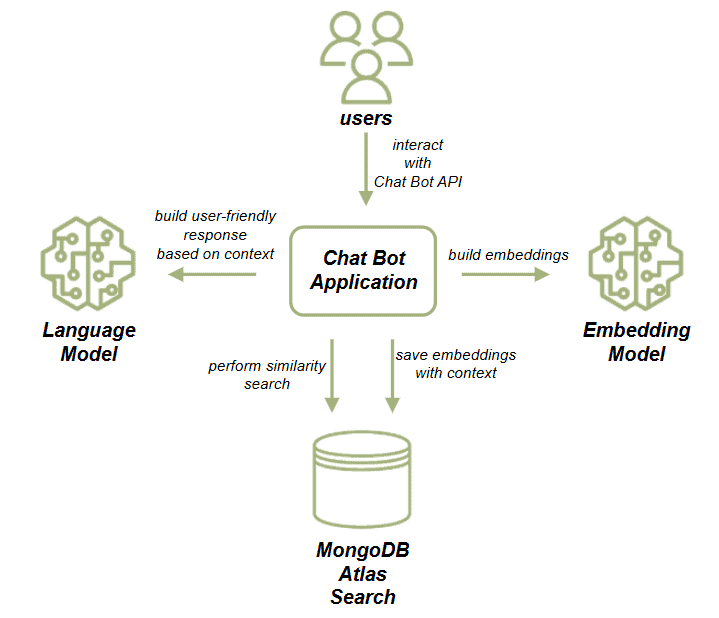
应用通过HTTP接口与聊天机器人交互,包含两个流程:文档加载流程和聊天机器人流程。
文档加载流程:
- 获取文章数据集
- 使用嵌入模型生成向量嵌入
- 将嵌入与数据一起存入MongoDB
这些嵌入代表文章的语义内容,支持高效的相似性搜索。
聊天机器人流程:
- 根据用户输入在MongoDB执行相似性搜索
- 用检索到的文章作为LLM提示的上下文
- 基于LLM输出生成机器人响应
3. 依赖与配置
首先添加spring-boot-starter-web依赖构建HTTP API:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.3.2</version>
</dependency>
接着添加langchain4j-mongodb-atlas依赖,用于与MongoDB向量存储和嵌入模型通信:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mongodb-atlas</artifactId>
<version>1.0.0-beta1</version>
</dependency>
最后添加langchain4j核心依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta1</version>
</dependency>
演示中我们使用本地MongoDB集群,并获取OpenAI API密钥。在application.properties中配置:
app.mongodb.url=mongodb://chatbot:password@localhost:27017/admin
app.mongodb.db-name=chatbot_db
app.openai.apiKey=${OPENAI_API_KEY}
创建ChatBotConfiguration配置类,定义MongoDB客户端和嵌入相关Bean:
@Configuration
public class ChatBotConfiguration {
@Value("${app.mongodb.url}")
private String mongodbUrl;
@Value("${app.mongodb.db-name}")
private String databaseName;
@Value("${app.openai.apiKey}")
private String apiKey;
@Bean
public MongoClient mongoClient() {
return MongoClients.create(mongodbUrl);
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore(MongoClient mongoClient) {
String collectionName = "embeddings";
String indexName = "embedding";
Long maxResultRatio = 10L;
CreateCollectionOptions createCollectionOptions = new CreateCollectionOptions();
Bson filter = null;
IndexMapping indexMapping = IndexMapping.builder()
.dimension(TEXT_EMBEDDING_3_SMALL.dimension())
.metadataFieldNames(new HashSet<>())
.build();
Boolean createIndex = true;
return new MongoDbEmbeddingStore(
mongoClient,
databaseName,
collectionName,
indexName,
maxResultRatio,
createCollectionOptions,
filter,
indexMapping,
createIndex
);
}
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.modelName(TEXT_EMBEDDING_3_SMALL)
.build();
}
}
我们使用OpenAI的text-embedding-3-small模型构建EmbeddingModel(可按需选择其他模型)。创建MongoDbEmbeddingStore时,需确保向量维度与所选模型匹配(这里使用默认值)。
4. 加载文档数据到向量存储
我们使用MongoDB文章作为聊天机器人数据源。演示中可从Hugging Face手动下载数据集,保存为resources文件夹下的articles.json文件。
应用启动时将这些文章转换为向量嵌入并存入MongoDB Atlas向量存储。在application.properties添加控制开关:
app.load-articles=true
4.1. ArticlesRepository
创建ArticlesRepository负责读取数据集、生成嵌入并存储:
@Component
public class ArticlesRepository {
private static final Logger log = LoggerFactory.getLogger(ArticlesRepository.class);
private final EmbeddingStore<TextSegment> embeddingStore;
private final EmbeddingModel embeddingModel;
private final ObjectMapper objectMapper = new ObjectMapper();
@Autowired
public ArticlesRepository(@Value("${app.load-articles}") Boolean shouldLoadArticles,
EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) throws IOException {
this.embeddingStore = embeddingStore;
this.embeddingModel = embeddingModel;
if (shouldLoadArticles) {
loadArticles();
}
}
}
配置了嵌入存储、嵌入模型和加载标志。当app.load-articles为true时启动加载。实现*loadArticles()*方法:
private void loadArticles() throws IOException {
String resourcePath = "articles.json";
int maxTokensPerChunk = 8000;
int overlapTokens = 800;
List<TextSegment> documents = loadJsonDocuments(resourcePath, maxTokensPerChunk, overlapTokens);
log.info("Documents to store: " + documents.size());
for (TextSegment document : documents) {
Embedding embedding = embeddingModel.embed(document.text()).content();
embeddingStore.add(embedding, document);
}
log.info("Documents are uploaded");
}
使用loadJsonDocuments()加载资源文件数据生成TextSegment列表。maxTokensPerChunk指定向量存储文档块的最大Token数(需小于模型维度),overlapTokens控制文本段间的Token重叠量(用于保持上下文连续性)。
4.2. loadJsonDocuments() 实现
实现*loadJsonDocuments()*读取JSON文章并解析为LangChain4j文档对象:
private List<TextSegment> loadJsonDocuments(String resourcePath, int maxTokensPerChunk, int overlapTokens) throws IOException {
InputStream inputStream = ArticlesRepository.class.getClassLoader().getResourceAsStream(resourcePath);
if (inputStream == null) {
throw new FileNotFoundException("Resource not found: " + resourcePath);
}
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
int batchSize = 500;
List<Document> batch = new ArrayList<>();
List<TextSegment> textSegments = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
JsonNode jsonNode = objectMapper.readTree(line);
String title = jsonNode.path("title").asText(null);
String body = jsonNode.path("body").asText(null);
JsonNode metadataNode = jsonNode.path("metadata");
if (body != null) {
addDocumentToBatch(title, body, metadataNode, batch);
if (batch.size() >= batchSize) {
textSegments.addAll(splitIntoChunks(batch, maxTokensPerChunk, overlapTokens));
batch.clear();
}
}
}
if (!batch.isEmpty()) {
textSegments.addAll(splitIntoChunks(batch, maxTokensPerChunk, overlapTokens));
}
return textSegments;
}
解析JSON文件,将文章标题、正文和元数据添加到批次。每500条记录处理一次,调用*splitIntoChunks()分割文本段。实现addDocumentToBatch()*:
private void addDocumentToBatch(String title, String body, JsonNode metadataNode, List<Document> batch) {
String text = (title != null ? title + "\n\n" : "") + body;
Metadata metadata = new Metadata();
if (metadataNode != null && metadataNode.isObject()) {
Iterator<String> fieldNames = metadataNode.fieldNames();
while (fieldNames.hasNext()) {
String fieldName = fieldNames.next();
metadata.put(fieldName, metadataNode.path(fieldName).asText());
}
}
Document document = Document.from(text, metadata);
batch.add(document);
}
将标题和正文合并为文本块,解析元数据字段,最终封装为Document对象加入批次。
4.3. splitIntoChunks() 实现与上传结果
将文档分割为符合嵌入模型限制的文本块:
private List<TextSegment> splitIntoChunks(List<Document> documents, int maxTokensPerChunk, int overlapTokens) {
OpenAiTokenizer tokenizer = new OpenAiTokenizer(OpenAiEmbeddingModelName.TEXT_EMBEDDING_3_SMALL);
DocumentSplitter splitter = DocumentSplitters.recursive(
maxTokensPerChunk,
overlapTokens,
tokenizer
);
List<TextSegment> allSegments = new ArrayList<>();
for (Document document : documents) {
List<TextSegment> segments = splitter.split(document);
allSegments.addAll(segments);
}
return allSegments;
}
初始化OpenAI兼容的分词器,使用DocumentSplitter递归分割文档(保留相邻块重叠)。应用启动时日志如下:
Documents to store: 328
Documents are uploaded
通过MongoDB Compass查看存储结果:
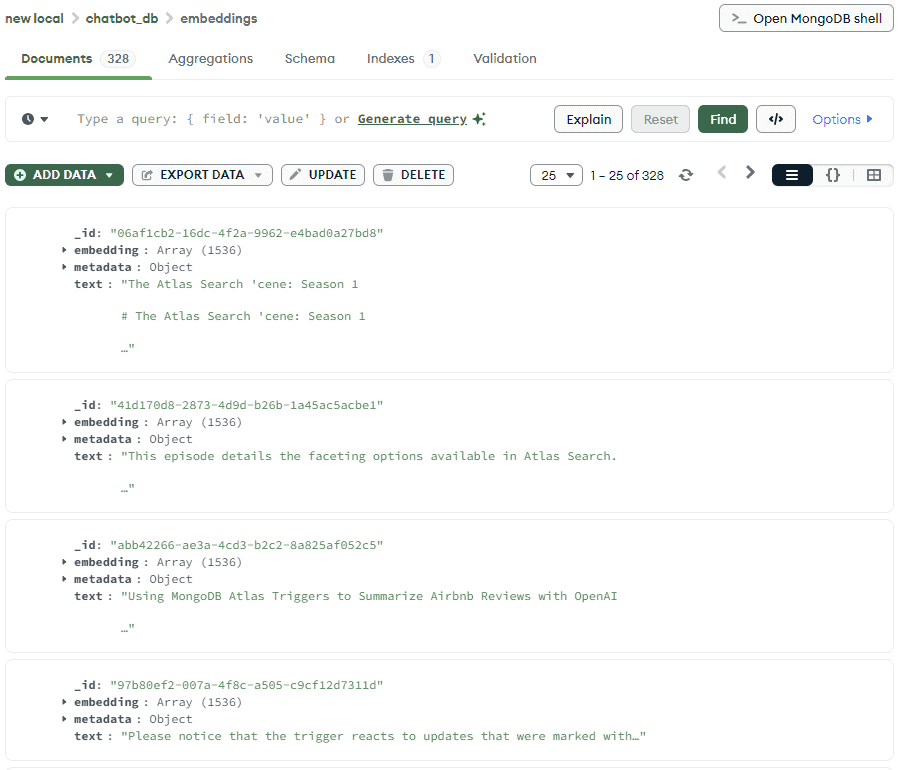
⚠️ 关键点:大多数嵌入模型有Token限制,分块确保数据量符合要求,重叠处理则保持段落内容的连续性。演示仅使用部分数据集,完整上传耗时且需更多API配额。
5. 聊天机器人API
实现聊天机器人流程:创建Bean从向量存储检索文档并与LLM交互生成上下文感知响应,最后构建API接口并测试。
5.1. ArticleBasedAssistant 实现
创建ContentRetriever Bean执行向量搜索:
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(10)
.minScore(0.8)
.build();
}
使用嵌入模型编码用户查询并匹配存储的嵌入。maxResults控制返回结果数,minScore设置匹配严格度。
创建ChatLanguageModel Bean生成响应:
@Bean
public ChatLanguageModel chatModel() {
return OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4o-mini")
.build();
}
使用gpt-4o-mini模型(可替换为其他模型)。定义ArticleBasedAssistant接口:
public interface ArticleBasedAssistant {
String answer(String question);
}
LangChain4j会动态实现此接口。创建对应的Bean:
@Bean
public ArticleBasedAssistant articleBasedAssistant(ChatLanguageModel chatModel, ContentRetriever contentRetriever) {
return AiServices.builder(ArticleBasedAssistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.build();
}
调用*assistant.answer("...")*时,自动完成查询嵌入→检索文档→生成自然语言响应的流程。
5.2. ChatBotController 实现与测试
创建ChatBotController映射GET请求:
@RestController
public class ChatBotController {
private final ArticleBasedAssistant assistant;
@Autowired
public ChatBotController(ArticleBasedAssistant assistant) {
this.assistant = assistant;
}
@GetMapping("/chat-bot")
public String answer(@RequestParam("question") String question) {
return assistant.answer(question);
}
}
集成聊天机器人接口,通过question参数接收查询并返回响应。测试用例:
@AutoConfigureMockMvc
@SpringBootTest(classes = {ChatBotConfiguration.class, ArticlesRepository.class, ChatBotController.class})
class ChatBotLiveTest {
Logger log = LoggerFactory.getLogger(ChatBotLiveTest.class);
@Autowired
private MockMvc mockMvc;
@Test
void givenChatBotApi_whenCallingGetEndpointWithQuestion_thenExpectedAnswersIsPresent() throws Exception {
String chatResponse = mockMvc
.perform(get("/chat-bot")
.param("question", "Steps to implement Spring boot app and MongoDB"))
.andReturn()
.getResponse()
.getContentAsString();
log.info(chatResponse);
Assertions.assertTrue(chatResponse.contains("Step 1"));
}
}
测试查询"实现Spring Boot应用和MongoDB的步骤",日志输出完整响应:
To implement a MongoDB Spring Boot Java Book Tracker application, follow these steps. This guide will help you set up a simple CRUD application to manage books, where you can add, edit, and delete book records stored in a MongoDB database.
### Step 1: Set Up Your Environment
1. **Install Java Development Kit (JDK)**:
Make sure you have JDK (Java Development Kit) installed on your machine. You can download it from the [Oracle website](https://www.oracle.com/java/technologies/javase-jdk11-downloads.html) or use OpenJDK.
2. **Install MongoDB**:
Download and install MongoDB from the [MongoDB official website](https://www.mongodb.com/try/download/community). Follow the installation instructions specific to your operating system.
//shortened
6. 总结
本文使用Langchain4j和MongoDB Atlas实现了聊天机器人Web应用。通过该应用,用户可基于已加载文章获取智能问答。后续改进方向包括:
- 添加查询预处理
- 处理歧义查询
- 扩展训练数据集
✅ 完整代码可在GitHub获取。