1. 概述
数据结构是任何编程语言的核心组成部分。Java 在 Collection<T> 接口下提供了大部分常用数据结构。虽然 Map 也被视为 Java 集合的一部分,但它并未实现该接口。
本教程将聚焦链表数据结构,重点讨论单链表中删除最后一个元素的操作。
2. 单链表 vs 双链表
先明确两种链表的核心差异。它们的名称已经揭示了关键区别:
✅ 双链表:每个节点同时保存前驱节点和后继节点的引用(头尾节点除外)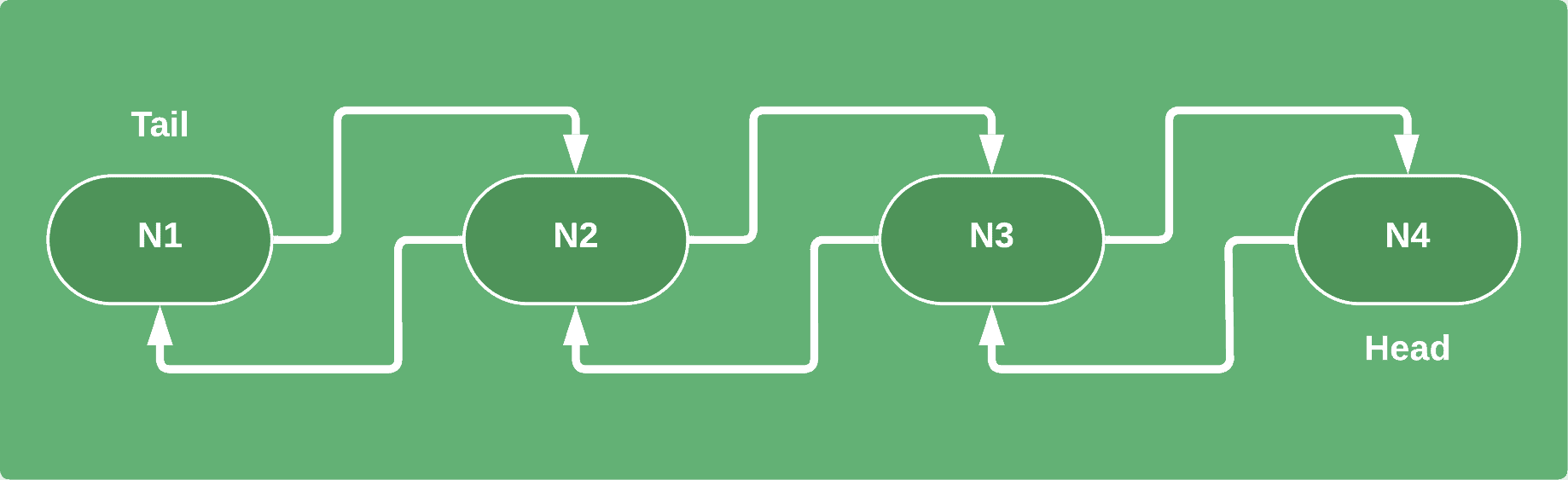
✅ 单链表:结构更简单,每个节点仅包含后继节点的引用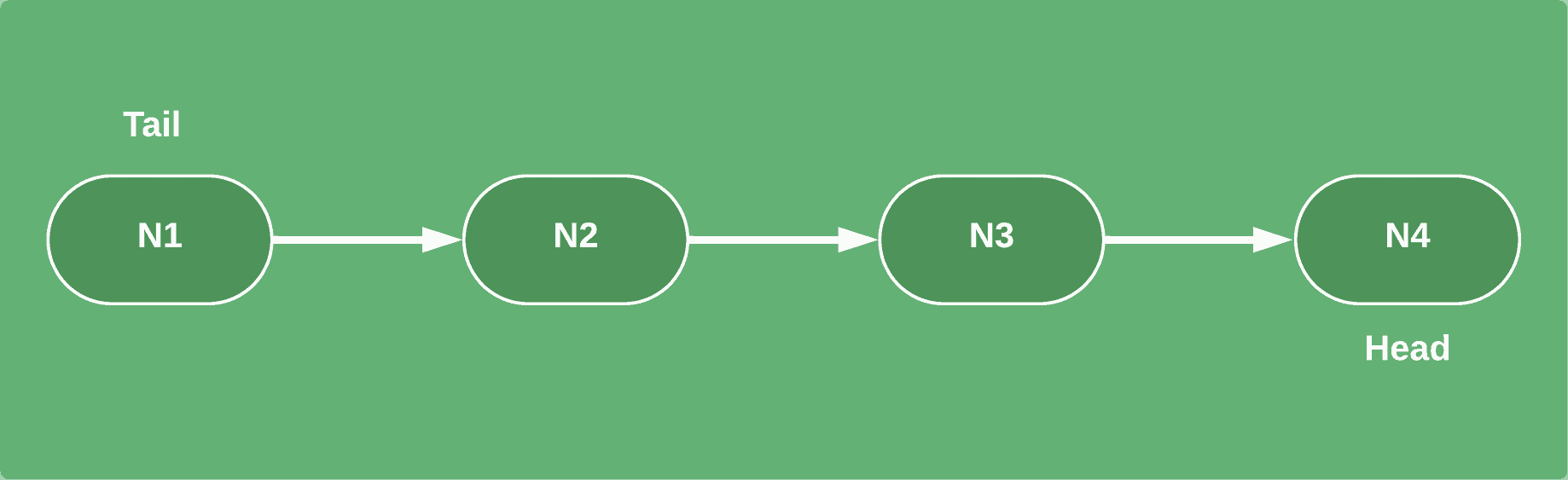
这种设计带来了典型的权衡:
- 内存占用:单链表每个节点只需维护一个引用,更省内存
- 操作灵活性:双链表支持反向遍历,在搜索、插入、删除等操作上更具优势
⚠️ 单链表在反向操作时会遇到明显瓶颈
3. 双链表删除最后一个元素
由于双链表节点包含前驱引用,删除操作非常简单。以 Java 标准库的 LinkedList<T> 为例,其节点结构如下:
class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
通过 prev 引用,删除操作只需几行代码即可完成(时间复杂度 O(1)):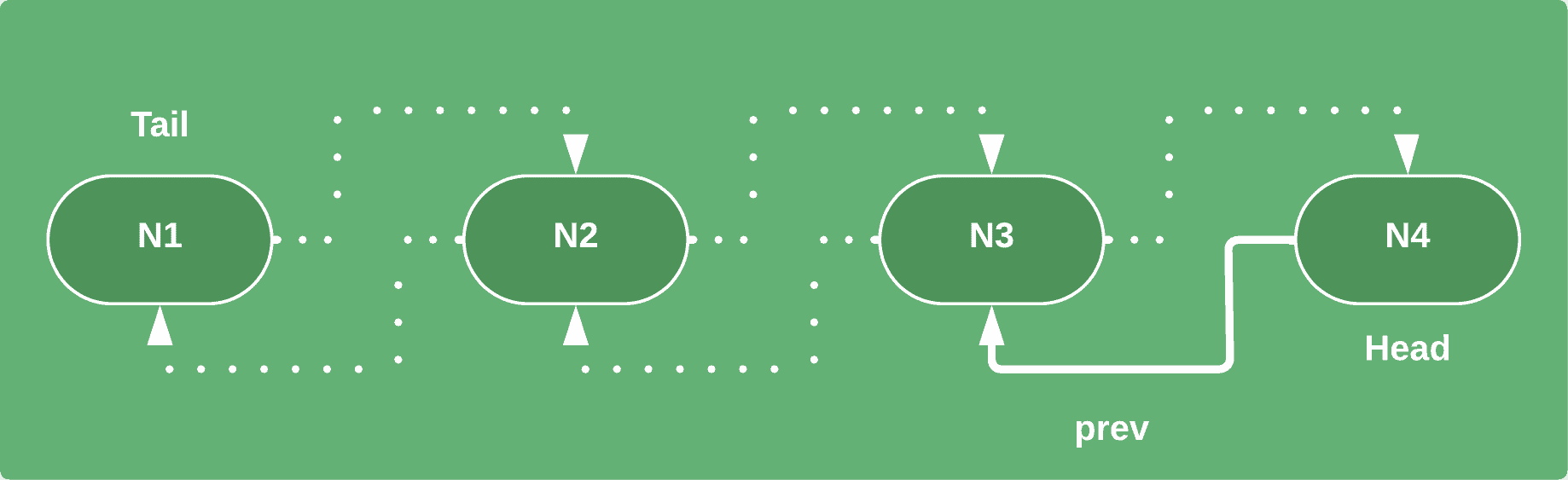
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
E element = l.item;
Node<E> prev = l.prev;
l.item = null;
l.prev = null; // 帮助GC回收
last = prev;
if (prev == null) {
first = null;
} else {
prev.next = null;
}
size--;
modCount++;
return element;
}
4. 单链表删除最后一个元素
单链表的主要难点在于:无法直接获取倒数第二个节点。其节点结构仅包含后继引用:
public static class Node<T> {
private T element;
private Node<T> next;
public Node(T element) {
this.element = element;
}
}
这导致我们必须从头遍历整个链表来定位倒数第二个节点:
public void removeLast() {
if (isEmpty()) {
return;
} else if (size() == 1) {
tail = null;
head = null;
} else {
Node<S> secondToLast = null;
Node<S> last = head;
while (last.next != null) {
secondToLast = last;
last = last.next;
}
secondToLast.next = null;
}
--size;
}
❌ 这种实现的时间复杂度为 O(n),在队列等高频操作场景下性能堪忧。
✅ 优化方案:在链表类中额外维护 secondToLast 引用:
public class SinglyLinkedList<S> {
private int size;
private Node<S> head = null;
private Node<S> tail = null;
private Node<S> secondToLast = null; // 新增引用
// 其他方法...
}
虽然无法解决遍历问题,但至少能让 removeLast() 操作达到 O(1) 时间复杂度。
5. 结论
数据结构没有绝对的好坏之分,只有适用场景的差异。关键点总结:
| 特性 | 单链表 | 双链表 |
|---|---|---|
| 内存占用 | ✅ 更低(每个节点1个引用) | ❌ 更高(每个节点2个引用) |
| 删除末节点 | ❌ O(n) 需遍历 | ✅ O(1) 直接操作 |
| 反向操作 | ❌ 不支持 | ✅ 天然支持 |
💡 核心建议:深入理解数据结构的底层实现,才能根据实际需求选择最合适的工具。单链表适合内存敏感场景,双链表则在需要频繁双向操作时更具优势。