1. 引言
逻辑回归(Logistic Regression)是机器学习(ML)开发者工具箱中的核心算法之一。
本文将深入剖析逻辑回归的核心思想,并通过一个经典案例——手写数字识别,带你从零实现一个基于 Java 的完整 ML 流程。
我们会跳过那些“什么是机器学习”的基础科普,直接切入重点。如果你已经熟悉数据预处理、模型训练这些概念,那这篇文章正适合你。
2. 机器学习流程概览
机器学习解决的是那些人类能轻松理解,但难以用规则精确描述的问题。比如:“这张图里是不是一只猫?”——我们一眼就能判断,但写不出明确的 if-else 判断逻辑。
因此,ML 的核心思路是:让模型从数据中自动学习规律。
这个过程依赖一个关键阶段:训练(Training)。我们把大量标注好的数据喂给算法,它会不断调整内部参数(也就是“权重”),使得预测结果越来越接近真实标签。
整个 ML 工作流通常是迭代的:

关键步骤包括:
✅ 数据获取:来源多样,需统一格式
✅ 数据清洗与划分:确保数据代表性,通常分为训练集和测试集
✅ 模型构建:选择合适的算法架构
✅ 训练与评估:迭代优化,直到效果达标
⚠️ 踩坑提示:如果训练数据中没有红苹果,模型几乎不可能识别出红苹果——数据决定模型的上限。
3. 机器学习范式
根据输入数据的类型和任务目标,ML 主要分为三类:
- 监督学习(Supervised Learning):输入数据带标签,目标是学习从输入到标签的映射。
✅ 典型任务:图像分类、情感分析、目标检测 - 无监督学习(Unsupervised Learning):数据无标签,目标是发现数据内在结构。
✅ 典型任务:聚类、异常检测 - 强化学习(Reinforcement Learning):通过试错和奖励机制学习策略。
✅ 典型任务:游戏 AI、机器人控制
本文聚焦于 监督学习 场景。
4. 常用机器学习算法
构建模型时,我们有多种“武器”可选:
- 线性回归(Linear Regression)
- ✅ 逻辑回归(Logistic Regression)
- 神经网络(Neural Networks)
- 支持向量机(SVM)
- k-近邻算法(k-Nearest Neighbours)
实际项目中,往往需要组合多种技术。本文将使用 逻辑回归思想 + 神经网络架构 来实现分类任务。
5. Java 机器学习库选型
虽然 Python 是 ML 主流语言,但 Java 在企业级应用中依然可靠。我们选择以下库:
- TensorFlow for Java:Google 官方支持,适合生产环境部署
- ✅ Deeplearning4j(DL4J):JVM 上最成熟的深度学习框架,原生 Java API,与 Spring 等生态无缝集成
本文使用 Deeplearning4j 作为核心实现。
6. 手写数字识别实战
目标:构建一个能识别 0-9 手写数字的模型。
核心思想:通过最小化损失函数(Loss Function) 来优化模型参数。损失函数衡量预测值与真实标签之间的差距,训练的目标就是让这个差距尽可能小。
我们基于经典的 MNIST 数据集和 LeNet-5 网络结构进行实现。
6.1 输入数据准备
使用 MNIST 数据库:包含 6 万张 28×28 灰度手写数字图像,每张图都有对应标签。

数据划分:
DataSetIterator train = new RecordReaderDataSetIterator(
new MnistRecordReader(0, 60000), // 训练集:60000 张
batchSize,
10 // 10 个类别 (0-9)
);
DataSetIterator test = new RecordReaderDataSetIterator(
new MnistRecordReader(60000, 10000), // 测试集:10000 张
batchSize,
10
);
⚠️ 注意:RecordReaderDataSetIterator 负责加载、归一化和批处理数据,是 DL4J 的标准做法。
6.2 模型构建
没有“万能模型”,但 LeNet-5 在手写识别上表现优异。它是一个卷积神经网络(CNN),将 28×28 图像映射为 10 维概率向量。

输出示例:
{0.1, 0.0, 0.3, 0.2, 0.1, 0.1, 0.0, 0.1, 0.1, 0.0}
表示预测为数字 2 的概率最高(0.3),因此最终分类结果为 2。
构建模型代码:
MultiLayerNetwork model = new MultiLayerNetwork(config);
关键在 MultiLayerConfiguration config 的定义。我们定义网络层结构:
// 第一层:卷积层
ConvolutionLayer layer1 = new ConvolutionLayer
.Builder(5, 5) // 卷积核 5x5
.nIn(1) // 输入通道数(灰度图=1)
.stride(1, 1) // 步长
.nOut(20) // 输出通道数(20 个卷积核)
.activation(Activation.IDENTITY)
.build();
// 第二层:池化层(最大池化)
SubsamplingLayer layer2 = new SubsamplingLayer
.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2) // 池化窗口 2x2
.stride(2, 2) // 步长 2
.build();
⚠️ 踩坑提示:nIn 必须显式指定输入通道数,否则会报错。
完整配置构建:
MultiLayerConfiguration config = new NeuralNetConfiguration.Builder()
.seed(123) // 随机种子,保证可复现
.updater(new Adam(1e-3)) // 优化器:Adam
.list()
.layer(0, layer1)
.layer(1, layer2)
// ... 添加后续层(全连接层、输出层等)
.layer(5, new OutputLayer
.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(500).nOut(10).build())
.setInputType(InputType.convolutionalFlat(28, 28, 1)) // 输入类型
.build();
6.3 模型训练
LeNet-5 约有 43 万个参数。训练过程极其简单:
model.fit(train);
首次训练后即可达到约 99% 的准确率。为追求更高精度,可进行多轮训练(epoch):
int epochs = 5;
for (int i = 0; i < epochs; i++) {
model.fit(train);
train.reset(); // 重置迭代器,准备下一轮
test.reset();
// 每轮后评估
Evaluation eval = model.evaluate(test);
System.out.println("Epoch " + i + " - Accuracy: " + eval.accuracy());
}
评估结果输出示例:
INFO o.d.e.Evaluation -
=========================Evaluation Metrics=========================
# of classes: 10
Accuracy: 0.9878
Precision: 0.9880
Recall: 0.9877
F1 Score: 0.9878
6.4 模型预测
训练完成后,即可对新图像进行预测。创建 MnistPrediction 类加载外部图像:
File file = new File("digit-2.png"); // 假设你画了一个数字 2
INDArray image = new NativeImageLoader(28, 28, 1).asMatrix(file);
// 归一化到 [0,1]
new ImagePreProcessingScaler(0, 1).transform(image);
执行预测:
INDArray output = model.output(image);
System.out.println(output); // 打印概率分布
预测结果可视化:
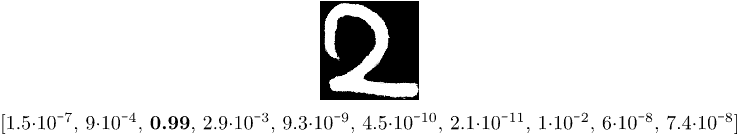
输出类似 [0.01, 0.00, 0.99, ...],最大值在索引 2,说明模型正确识别为数字 2 ✅。
7. 总结
本文通过手写数字识别案例,展示了 Java 中实现逻辑回归(基于神经网络)的完整流程:
- 使用 Deeplearning4j 构建 LeNet-5 模型
- 完成数据加载、训练、评估与预测
- 实现了接近 99% 的高准确率
代码已托管至 GitHub,可直接运行验证:
👉 https://github.com/baeldung/tutorials/tree/master/deeplearning4j
逻辑回归虽名为“回归”,实为分类利器。结合神经网络,它在图像识别等任务中依然表现强劲。Java 开发者也能轻松玩转 ML!