1. 概述
本文将深入探讨蒙特卡洛树搜索(MCTS)算法及其应用场景。我们将通过用Java实现井字棋游戏,详细解析算法的各个阶段。我们将设计一个通用解决方案,只需少量修改即可应用于其他实际场景。
2. 算法简介
简单来说,蒙特卡洛树搜索是一种概率型搜索算法。它在开放环境(可能性数量巨大)中表现高效,是一种独特的决策算法。
如果你熟悉Minimax这类博弈论算法,就知道它需要评估当前状态的函数,并且必须计算游戏树的多层才能找到最优解。但在围棋这类分支因子极高的游戏中(随着树高度增加会产生数百万种可能性),这种做法不可行,而且很难编写好的评估函数来判断当前状态的优劣。
蒙特卡洛树搜索将蒙特卡洛方法应用于游戏树搜索。由于它基于游戏状态的随机采样,无需暴力穷举所有可能性。同时,它也不强制要求我们编写评估或启发式函数。
顺便提一句——它彻底改变了计算机围棋领域。自2016年3月以来,随着谷歌的AlphaGo(基于MCTS和神经网络构建)击败围棋世界冠军李世石,MCTS已成为热门研究课题。
3. 蒙特卡洛树搜索算法详解
现在我们来探索算法的工作原理。首先构建一个前瞻树(游戏树),根节点为初始状态,然后通过随机推演不断扩展树结构。过程中,我们会维护每个节点的访问次数和胜利次数。
最终,我们将选择统计数据最优的节点。
算法包含四个阶段,下面详细解析每个阶段:
3.1 选择阶段
算法从根节点开始,选择胜率最高的子节点。同时要确保每个节点都有公平的机会。
核心思想是持续选择最优子节点,直到到达树的叶子节点。 选择子节点的好方法是使用UCT(应用于树的上置信界)公式: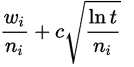 其中:
其中:
- wᵢ = 第i步移动后的胜利次数
- nᵢ = 第i步移动后的模拟次数
- c = 探索参数(理论值√2)
- t = 父节点的总模拟次数
该公式确保: ✅ 不会有状态被"饿死"(长期不被访问) ✅ 高胜率分支会被更频繁地探索
3.2 扩展阶段
当无法再用UCT找到后继节点时,算法通过添加叶子节点的所有可能状态来扩展游戏树。
3.3 模拟阶段
扩展后,算法随机选择一个子节点,从该节点开始模拟随机游戏直到结束。如果在推演过程中节点是随机或半随机选择的,称为轻量级推演。也可以通过编写高质量启发式函数或评估函数实现重量级推演。
3.4 反向传播阶段
也称为更新阶段。当算法到达游戏终点时,评估状态确定胜者。然后向上回溯到根节点:
- 增加所有访问节点的访问计数
- 如果该位置玩家获胜,则更新对应节点的胜利分数
MCTS会重复这四个阶段,直到达到固定迭代次数或时间限制。
这种方法通过随机移动估计每个节点的胜利分数。迭代次数越多,估计越可靠。搜索开始时估计可能不准确,但随着时间推移会持续改进——这完全取决于问题类型。
4. 算法演示
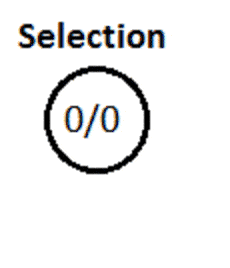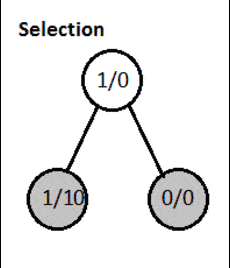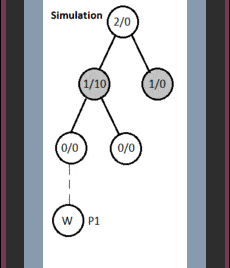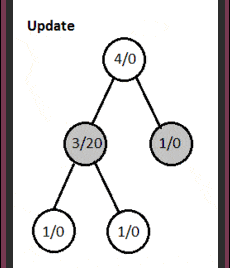
图中节点格式为:总访问次数/胜利分数
5. Java实现
现在我们用蒙特卡洛树搜索算法实现井字棋游戏。我们将设计一个通用MCTS解决方案,稍作修改即可用于其他棋类游戏。本文将展示大部分核心代码。
为保持简洁,可能省略部分与MCTS无关的细节,但完整实现可在GitHub找到(作者邮箱:eugenp@github.com)。
首先需要基础的树和节点类:
public class Node {
State state;
Node parent;
List<Node> childArray;
// setters and getters
}
public class Tree {
Node root;
}
每个节点对应问题状态,实现State类:
public class State {
Board board;
int playerNo;
int visitCount;
double winScore;
// copy constructor, getters, and setters
public List<State> getAllPossibleStates() {
// 构建当前状态的所有可能状态列表
}
public void randomPlay() {
/* 获取棋盘所有可能位置并随机落子 */
}
}
实现MonteCarloTreeSearch类,负责从给定局面找出最佳下一步:
public class MonteCarloTreeSearch {
static final int WIN_SCORE = 10;
int level;
int opponent;
public Board findNextMove(Board board, int playerNo) {
// 设置终止条件(如结束时间)
long end = System.currentTimeMillis() + 2000; // 模拟2秒
opponent = 3 - playerNo;
Tree tree = new Tree();
Node rootNode = tree.getRoot();
rootNode.getState().setBoard(board);
rootNode.getState().setPlayerNo(opponent);
while (System.currentTimeMillis() < end) {
Node promisingNode = selectPromisingNode(rootNode);
if (promisingNode.getState().getBoard().checkStatus()
== Board.IN_PROGRESS) {
expandNode(promisingNode);
}
Node nodeToExplore = promisingNode;
if (promisingNode.getChildArray().size() > 0) {
nodeToExplore = promisingNode.getRandomChildNode();
}
int playoutResult = simulateRandomPlayout(nodeToExplore);
backPropogation(nodeToExplore, playoutResult);
}
Node winnerNode = rootNode.getChildWithMaxScore();
tree.setRoot(winnerNode);
return winnerNode.getState().getBoard();
}
}
我们持续迭代四个阶段直到超时,最终得到具有可靠统计数据的树用于决策。
现在实现各阶段方法:
从选择阶段开始(需实现UCT):
private Node selectPromisingNode(Node rootNode) {
Node node = rootNode;
while (node.getChildArray().size() != 0) {
node = UCT.findBestNodeWithUCT(node);
}
return node;
}
public class UCT {
public static double uctValue(
int totalVisit, double nodeWinScore, int nodeVisit) {
if (nodeVisit == 0) {
return Integer.MAX_VALUE;
}
return ((double) nodeWinScore / (double) nodeVisit)
+ 1.41 * Math.sqrt(Math.log(totalVisit) / (double) nodeVisit);
}
public static Node findBestNodeWithUCT(Node node) {
int parentVisit = node.getState().getVisitCount();
return Collections.max(
node.getChildArray(),
Comparator.comparing(c -> uctValue(parentVisit,
c.getState().getWinScore(), c.getState().getVisitCount())));
}
}
该阶段返回需要扩展的叶子节点:
private void expandNode(Node node) {
List<State> possibleStates = node.getState().getAllPossibleStates();
possibleStates.forEach(state -> {
Node newNode = new Node(state);
newNode.setParent(node);
newNode.getState().setPlayerNo(node.getState().getOpponent());
node.getChildArray().add(newNode);
});
}
随机选择节点并模拟推演,实现反向传播更新分数:
private void backPropogation(Node nodeToExplore, int playerNo) {
Node tempNode = nodeToExplore;
while (tempNode != null) {
tempNode.getState().incrementVisit();
if (tempNode.getState().getPlayerNo() == playerNo) {
tempNode.getState().addScore(WIN_SCORE);
}
tempNode = tempNode.getParent();
}
}
private int simulateRandomPlayout(Node node) {
Node tempNode = new Node(node);
State tempState = tempNode.getState();
int boardStatus = tempState.getBoard().checkStatus();
if (boardStatus == opponent) {
tempNode.getParent().getState().setWinScore(Integer.MIN_VALUE);
return boardStatus;
}
while (boardStatus == Board.IN_PROGRESS) {
tempState.togglePlayer();
tempState.randomPlay();
boardStatus = tempState.getBoard().checkStatus();
}
return boardStatus;
}
MCTS实现完成!只需井字棋专用的Board类:
public class Board {
int[][] boardValues;
public static final int DEFAULT_BOARD_SIZE = 3;
public static final int IN_PROGRESS = -1;
public static final int DRAW = 0;
public static final int P1 = 1;
public static final int P2 = 2;
// getters and setters
public void performMove(int player, Position p) {
this.totalMoves++;
boardValues[p.getX()][p.getY()] = player;
}
public int checkStatus() {
/* 评估游戏状态:
返回胜者编号(1/2)
平局返回0
未结束返回-1 */
}
public List<Position> getEmptyPositions() {
int size = this.boardValues.length;
List<Position> emptyPositions = new ArrayList<>();
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
if (boardValues[i][j] == 0)
emptyPositions.add(new Position(i, j));
}
}
return emptyPositions;
}
}
我们实现了一个无法被击败的井字棋AI!用单元测试验证AI对弈结果必为平局:
@Test
void givenEmptyBoard_whenSimulateInterAIPlay_thenGameDraw() {
Board board = new Board();
int player = Board.P1;
int totalMoves = Board.DEFAULT_BOARD_SIZE * Board.DEFAULT_BOARD_SIZE;
for (int i = 0; i < totalMoves; i++) {
board = mcts.findNextMove(board, player);
if (board.checkStatus() != -1) {
break;
}
player = 3 - player;
}
int winStatus = board.checkStatus();
assertEquals(winStatus, Board.DRAW);
}
6. 算法优势
✅ 无需游戏战术知识:不依赖特定游戏规则
✅ 通用性强:基础实现稍作修改即可用于多种游戏
✅ 资源聚焦:优先探索高胜率节点
✅ 高分支场景友好:避免在所有分支上浪费计算资源
✅ 实现简单:核心逻辑直观
✅ 随时终止:可随时中断并返回当前最优解
7. 潜在缺陷
⚠️ 如果使用基础MCTS而不做改进,可能无法给出合理走法。当节点访问不足时,会导致估计不准确。
但MCTS可通过多种技术改进:
- 领域特定技术:模拟阶段生成更真实的推演(需游戏知识)
- 领域无关技术:通用优化方法(如并行化)
8. 总结
乍看之下,很难相信依赖随机选择的算法能产生智能AI。但精心实现的MCTS确实能提供适用于多种游戏和决策问题的解决方案。
完整代码实现请访问GitHub仓库(作者邮箱:eugenp@github.com)。