1. 概述
随着 AI 和机器学习技术的发展,我们越来越需要从图像中提取文本信息的能力——比如识别截图中的文字块、解析扫描文档等。
本文将介绍 Tesseract,一个功能强大的开源 OCR(Optical Character Recognition,光学字符识别)引擎,并通过实际示例演示如何将图像内容转换为可编辑的文本。
如果你在项目中遇到“把图片转成文字”的需求,Tesseract 是一个成熟且值得信赖的选择。它不仅能识别 100 多种语言,还支持中文、阿拉伯语等复杂书写系统,甚至可以自定义训练模型。
2. Tesseract 简介
Tesseract 最初由 HP 开发,现由 Google 维护,是目前最主流的开源 OCR 引擎之一。
✅ 主要特性包括:
- 支持超过 100 种语言,涵盖中文、日文、韩文等意音文字,以及阿拉伯语、希伯来语等从右到左书写的语言
- 提供两种 OCR 引擎:
- LSTM(Long Short-Term Memory)引擎:基于深度学习,识别准确率高
- Legacy 引擎:传统模式,基于字符模板匹配,速度较快但精度较低
- 使用 Leptonica 库 处理图像格式
- 输出格式丰富:纯文本、hOCR(带位置信息的 HTML)、PDF(可搜索)、TSV(表格数据)
⚠️ 注意:虽然功能强大,但识别效果高度依赖图像质量、字体清晰度和预处理手段。模糊、倾斜或低分辨率的图片容易“翻车”。
3. 环境安装
Tesseract 支持主流操作系统,安装方式如下:
macOS
使用 Homebrew 安装:
brew install tesseract
默认只包含英文(eng)、方向脚本检测(osd)和数字识别(snum)的语言数据包:
==> Installing tesseract
==> Downloading https://homebrew.bintray.com/bottles/tesseract-4.1.1.high_sierra.bottle.tar.gz
==> Pouring tesseract-4.1.1.high_sierra.bottle.tar.gz
==> Caveats
This formula contains only the "eng", "osd", and "snum" language data files.
If you need any other supported languages, run `brew install tesseract-lang`.
==> Summary
/usr/local/Cellar/tesseract/4.1.1: 65 files, 29.9MB
如需其他语言支持(如中文、西班牙语),需额外安装:
brew install tesseract-lang
Linux
使用 yum(CentOS/RHEL):
yum install tesseract
安装语言包(以英文和西班牙语为例):
yum install tesseract-langpack-eng
yum install tesseract-langpack-spa
Windows
推荐使用 UB Mannheim 提供的安装包,自带图形界面和命令行工具,开箱即用。
安装完成后,确保 tesseract 命令能被系统识别(即加入 PATH)。
4. 命令行使用
Tesseract 提供了强大的 CLI 工具,适合快速测试或批处理任务。
4.1 基础使用
假设我们有一张网站截图 baeldung.png:
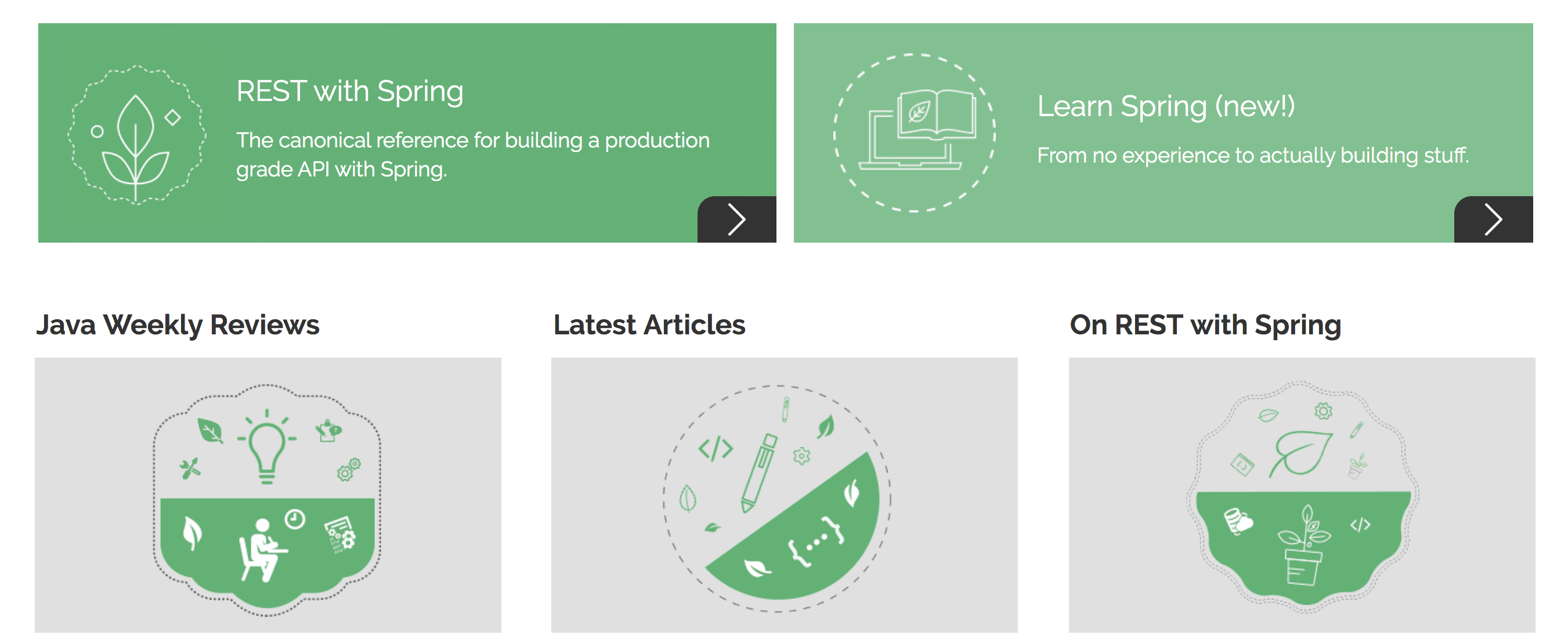
执行以下命令提取文本:
tesseract baeldung.png output
生成的 output.txt 内容如下:
a REST with Spring Learn Spring (new!)
The canonical reference for building a production
grade API with Spring.
From no experience to actually building stuff.
y
Java Weekly Reviews
⚠️ 踩坑提示:输出不完整?别慌,这是正常现象。OCR 的准确性受多种因素影响:
- 图像分辨率
- 字体样式与大小
- 背景干扰
- 语言设置
- 页面分割模式(PSM)
- 使用的 OCR 引擎
接下来我们逐个优化。
4.2 多语言支持
Tesseract 默认使用英文模型。要识别其他语言,需通过 -l 参数指定语言代码。
例如,处理一张包含多国语言的图片:

仅用英文识别:
tesseract multiLanguageText.png output
结果:
Der ,.schnelle” braune Fuchs springt
iiber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra il cane pigro. El zorro
marron rapido salta sobre el perro
perezoso. A raposa marrom rapida
salta sobre 0 cao preguicoso.
可以看到葡萄牙语中的 ç、ã 被错误识别。
改用葡萄牙语模型:
tesseract multiLanguageText.png output -l por
结果明显改善:
Der ,.schnelle” braune Fuchs springt
iber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra il cane pigro. El zorro
marrón rápido salta sobre el perro
perezoso. A raposa marrom rápida
salta sobre o cão preguiçoso.
✅ 支持多语言混合识别:
tesseract multiLanguageText.png output -l spa+por
表示优先使用西班牙语模型,再尝试葡萄牙语。顺序会影响识别结果,建议按出现频率排序。
4.3 页面分割模式(Page Segmentation Mode, PSM)
PSM 控制 Tesseract 如何理解图像布局。使用 --psm 参数设置(0-13)。
常用模式:
tesseract multiLanguageText.png output --psm 1
--psm 1 表示“自动页面分割 + OSD(方向/脚本检测)”,适合大多数场景。
完整模式说明:

📌 常用建议:
psm 3:完全自动,适合普通文档psm 6:单块文本,适合截图中的段落psm 7:单行文本psm 8:单个单词psm 13:原始图像,不进行分割
4.4 OCR 引擎模式(OCR Engine Mode, OEM)
通过 --oem 参数选择使用哪种 OCR 引擎:
tesseract multiLanguageText.png output --oem 1
--oem 1 表示使用 LSTM 引擎(推荐)。
可用模式:

📌 推荐组合:--oem 1 --psm 3(LSTM + 自动分割),平衡准确率与兼容性。
4.5 训练数据(Tessdata)
Tesseract 提供三套训练数据:
tessdata_best:最高精度,文件大tessdata_fast:速度快,精度略低tessdata:兼容 Legacy 和 LSTM 引擎
⚠️ 踩坑提示:如果使用 Legacy 引擎但缺少对应 .traineddata 文件,会报错:
Error: Tesseract (legacy) engine requested, but components are not present in /usr/local/share/tessdata/eng.traineddata!!
Failed loading language 'eng'
Tesseract couldn't load any languages!
解决方案:
- 下载所需
.traineddata文件 - 放入默认目录(如
/usr/local/share/tessdata) - 或通过
--tessdata-dir指定路径:
tesseract multiLanguageText.png output --tessdata-dir /image-processing/tessdata
4.6 输出格式
Tesseract 支持多种输出格式,通过扩展名指定:
- 生成可搜索 PDF(保留原图 + 文本层):
tesseract multiLanguageText.png output pdf
- 生成 hOCR(HTML 格式,包含文本坐标):
tesseract multiLanguageText.png output hocr
- 生成 TSV(表格数据,含置信度、坐标):
tesseract multiLanguageText.png output tsv
📌 实用技巧:使用 tesseract --help 或 tesseract --help-extra 查看所有参数。
5. Java 集成:Tess4J
在 Java 项目中,推荐使用 Tess4J,它是 Tesseract 的 JNI 封装,API 简洁易用。
添加依赖
Maven:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.1</version>
</dependency>
基础 OCR 示例
File image = new File("src/main/resources/images/multiLanguageText.png");
Tesseract tesseract = new Tesseract();
// 设置训练数据路径(需包含 eng.traineddata 等文件)
tesseract.setDatapath("src/main/resources/tessdata");
// 设置语言
tesseract.setLanguage("eng");
// 设置页面分割模式(PSM)
tesseract.setPageSegMode(1); // PSM_AUTO_OSD
// 设置 OCR 引擎模式(OEM)
tesseract.setOcrEngineMode(1); // OEM_LSTM_ONLY
// 执行 OCR
String result = tesseract.doOCR(image);
验证结果
Assert.assertTrue(result.contains("Der ,.schnelle” braune Fuchs springt"));
Assert.assertTrue(result.contains("salta sopra il cane pigro. El zorro"));
高级用法
- 获取 hOCR 输出:
tesseract.setHocr(true);
- 只识别图像局部区域(如某个矩形框):
Rectangle rect = new Rectangle(1200, 200); // x=1200, y=200, width=?, height=?
String result = tesseract.doOCR(image, rect);
⚠️ 注意:Rectangle 的坐标是相对于图像左上角的像素位置。
替代方案
除了 Tess4J,也可使用 JavaCPP Presets for Tesseract,它基于 JavaCPP,更新更及时,但 API 稍底层。
6. 总结
本文系统介绍了 Tesseract OCR 引擎的使用方法:
- ✅ 命令行工具:适合快速验证、脚本化处理
- ✅ 支持多语言、多种输出格式
- ✅ 提供 LSTM 和 Legacy 两种引擎,灵活平衡速度与精度
- ✅ 通过 PSM 和 OEM 参数精细控制识别行为
- ✅ Java 项目可通过 Tess4J 无缝集成
📌 实际项目建议:
- 图像预处理(去噪、二值化、放大)能显著提升识别率
- 中文识别推荐使用
chi_sim或chi_tra模型 - 生产环境建议使用
tessdata_best并缓存训练数据
所有示例代码已托管至 GitHub:https://github.com/eugenp/tutorials/tree/master/image-processing