1. 概述
本文将深入探讨字符串模式匹配的核心思想,并重点介绍如何通过后缀树(Suffix Tree)大幅提升匹配效率。我们会从基础概念讲起,逐步构建一个完整的 Java 实现,最终实现接近 O(p) 时间复杂度的模式搜索能力,远优于传统的暴力匹配。
2. 字符串模式匹配
2.1. 基本定义
模式匹配,简单说就是在一段目标文本(text)中查找一个给定的模式串(pattern)。
对于非正则表达式的普通字符串匹配,我们通常有以下期望:
- ✅ 精确匹配:必须完全一致,不允许模糊或部分重叠(除非模式本身如此)
- ✅ 返回全部结果:不能只找到第一个就停,要找出所有出现位置
- ✅ 返回匹配位置:需要知道模式在原文中的起始索引
2.2. 基础搜索方式
举个例子:
Pattern: NA
Text: HAVANABANANA
Match1: ----NA------
Match2: --------NA--
Match3: ----------NA
模式 NA 在文本中出现了 3 次。最朴素的做法是将模式在文本上逐字符滑动比对。
⚠️ 但这种方式的时间复杂度是 **O(p × t)**,其中 p 是模式长度,t 是文本长度。当文本很长或需要多次搜索时,性能会急剧下降。
更糟的是,如果要搜索多个模式,复杂度会线性叠加——每个模式都得独立跑一遍。
2.3. 使用 Trie 存储多个模式
为了优化多模式搜索,我们可以把所有模式存入 Trie 树(前缀树)。
Trie 能高效存储和检索字符串集合。例如,存储 {NA, NAB} 会得到如下结构:
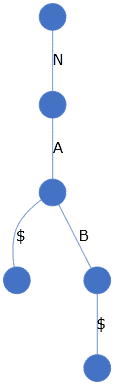
这样就能在一次遍历中同时检查多个模式是否匹配。但注意,这里的 Trie 存的是模式集合。
2.4. 使用后缀 Trie 存储文本
另一种思路:把目标文本的所有后缀存进 Trie,这就是后缀 Trie(Suffix Trie)。
以 HAVANABANANA 为例,其所有后缀包括:
HAVANABANANAAVANABANANAVANABANANA- ...
A
构建出的后缀 Trie 如下:

搜索时,只需在树中找一条路径能完全匹配模式即可。但问题来了:后缀 Trie 太占空间——每个字符都占一个边节点,空间复杂度高达 O(t²)。
接下来要介绍的“后缀树”就是对它的空间优化版本。
3. 后缀树(Suffix Tree)
后缀树本质上是压缩版的后缀 Trie。它通过合并只有一个子节点的链式节点,把多个字符压缩到一条边上,从而大幅节省空间。
还是 HAVANABANANA,其对应的后缀树如下:
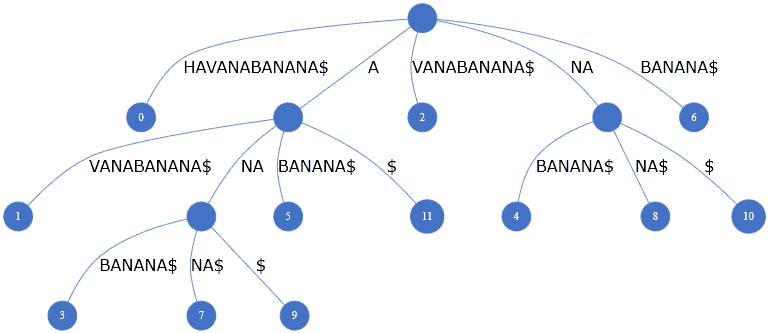
关键特性:
- ✅ 每条从根到叶子的路径代表原文的一个后缀
- ✅ 叶子节点存储该后缀在原文中的起始位置(0-based)
- 例如
BANANA$起始于第 6 位(索引 6) ABANANA$起始于第 5 位(索引 5)
- 例如
💡
$是终止符,用于区分不同后缀,避免歧义。
模式匹配的本质:从根开始,能否找到一条路径,其边上的字符拼接后能完全匹配给定模式。
- 若路径止于叶子 → 是某个后缀的开头
- 若路径止于中间 → 是某个子串的匹配
比如 NA,它既是 BANANA 的后缀,也是 HAVANABANANA 的内部子串。
接下来,我们用 Java 实现这个结构。
4. 数据结构设计
我们需要两个核心类。
4.1. 节点类(Node)
public class Node {
private String text; // 当前节点代表的字符串片段
private List<Node> children;
private int position; // 仅叶子节点有效:后缀起始位置
public Node(String word, int position) {
this.text = word;
this.position = position;
this.children = new ArrayList<>();
}
// getter/setter/toString 省略
}
4.2. 后缀树类(SuffixTree)
public class SuffixTree {
private static final String WORD_TERMINATION = "$";
private static final int POSITION_UNDEFINED = -1;
private Node root;
private String fullText;
public SuffixTree(String text) {
root = new Node("", POSITION_UNDEFINED);
fullText = text;
}
}
5. 构建辅助方法
在实现核心逻辑前,先准备几个工具方法。
5.1. 添加子节点
private void addChildNode(Node parentNode, String text, int index) {
parentNode.getChildren().add(new Node(text, index));
}
5.2. 计算最长公共前缀
private String getLongestCommonPrefix(String str1, String str2) {
int compareLength = Math.min(str1.length(), str2.length());
for (int i = 0; i < compareLength; i++) {
if (str1.charAt(i) != str2.charAt(i)) {
return str1.substring(0, i);
}
}
return str1.substring(0, compareLength);
}
5.3. 节点分裂(Split)
这是构建树的关键操作。当新后缀与现有节点部分重叠时,需要把原节点“劈开”,形成父子关系。
例如,现有边 ANA,要插入 ABANANA$,需先分裂为 A → NA,再把 BANANA$ 作为 A 的另一个子节点:
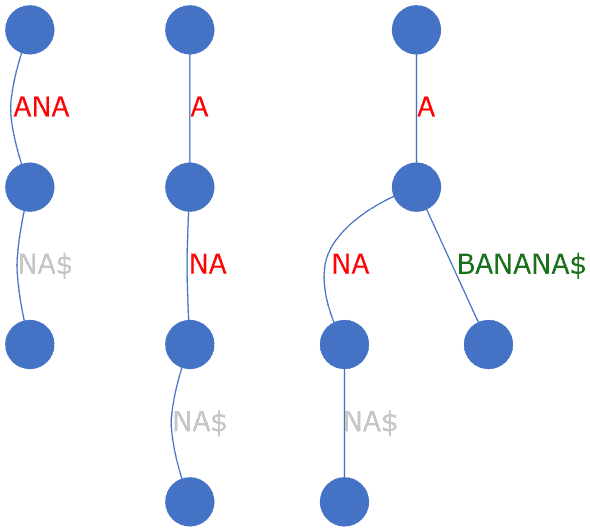
实现如下:
private void splitNodeToParentAndChild(Node parentNode, String parentNewText, String childNewText) {
Node childNode = new Node(childNewText, parentNode.getPosition());
// 把原节点的子节点全部转移给新子节点
if (parentNode.getChildren().size() > 0) {
while (parentNode.getChildren().size() > 0) {
childNode.getChildren()
.add(parentNode.getChildren().remove(0));
}
}
parentNode.getChildren().add(childNode);
parentNode.setText(parentNewText);
parentNode.setPosition(POSITION_UNDEFINED); // 原叶子变内部节点
}
6. 遍历辅助方法
搜索和构建都依赖树的遍历。
6.1. 全匹配 vs. 部分匹配
理解这两个概念是关键:
- 构建时用部分匹配:找一个已有路径能“接上”新后缀的位置
- 搜索时用全匹配:必须完全匹配整个模式
例如,已有 AVANABANANA$,要插入 ANABANANA$,首字符 A 相同 → 找到“部分匹配”节点,后续再处理。
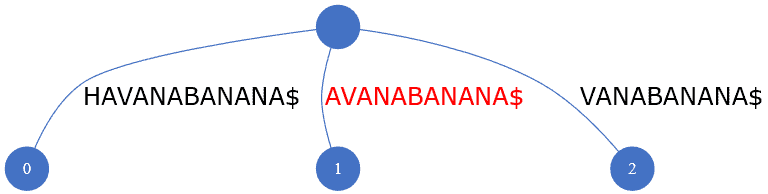
搜索 VANE 时,虽与 VANABANANA$ 前三字符匹配,但第四字符不匹配 → ❌ 无结果。
6.2. 核心遍历逻辑
private List<Node> getAllNodesInTraversePath(String pattern, Node startNode, boolean isAllowPartialMatch) {
List<Node> nodes = new ArrayList<>();
for (int i = 0; i < startNode.getChildren().size(); i++) {
Node currentNode = startNode.getChildren().get(i);
String nodeText = currentNode.getText();
if (pattern.charAt(0) == nodeText.charAt(0)) {
// 允许部分匹配 且 模式长度 ≤ 当前边长度 → 直接命中
if (isAllowPartialMatch && pattern.length() <= nodeText.length()) {
nodes.add(currentNode);
return nodes;
}
// 逐字符比较公共部分
int compareLength = Math.min(nodeText.length(), pattern.length());
for (int j = 1; j < compareLength; j++) {
if (pattern.charAt(j) != nodeText.charAt(j)) {
if (isAllowPartialMatch) {
nodes.add(currentNode);
}
return nodes;
}
}
nodes.add(currentNode);
// 模式还有剩余字符 → 继续递归子节点
if (pattern.length() > compareLength) {
List<Node> nodes2 = getAllNodesInTraversePath(
pattern.substring(compareLength),
currentNode,
isAllowPartialMatch
);
if (nodes2.size() > 0) {
nodes.addAll(nodes2);
} else if (!isAllowPartialMatch) {
nodes.add(null); // 全匹配失败标记
}
}
return nodes;
}
}
return nodes;
}
7. 核心算法实现
7.1. 构建后缀树
private void addSuffix(String suffix, int position) {
List<Node> nodes = getAllNodesInTraversePath(suffix, root, true);
if (nodes.size() == 0) {
// 无匹配路径 → 直接作为根的子节点
addChildNode(root, suffix, position);
} else {
// 有部分匹配 → 需扩展现有节点
Node lastNode = nodes.remove(nodes.size() - 1);
String newText = suffix;
// 计算需要新增的文本(去掉已匹配的前缀)
if (nodes.size() > 0) {
String existingSuffixUptoLastNode = nodes.stream()
.map(a -> a.getText())
.reduce("", String::concat);
newText = newText.substring(existingSuffixUptoLastNode.length());
}
extendNode(lastNode, newText, position);
}
}
private void extendNode(Node node, String newText, int position) {
String currentText = node.getText();
String commonPrefix = getLongestCommonPrefix(currentText, newText);
// 如果不完全匹配 → 分裂节点
if (!commonPrefix.equals(currentText)) {
String parentText = currentText.substring(0, commonPrefix.length());
String childText = currentText.substring(commonPrefix.length());
splitNodeToParentAndChild(node, parentText, childText);
}
// 将剩余部分作为新子节点加入
String remainingText = newText.substring(commonPrefix.length());
addChildNode(node, remainingText, position);
}
构造函数中批量添加所有后缀:
public SuffixTree(String text) {
root = new Node("", POSITION_UNDEFINED);
for (int i = 0; i < text.length(); i++) {
addSuffix(text.substring(i) + WORD_TERMINATION, i);
}
fullText = text;
}
7.2. 模式搜索
public List<String> searchText(String pattern) {
List<String> result = new ArrayList<>();
List<Node> nodes = getAllNodesInTraversePath(pattern, root, false);
if (nodes.size() > 0) {
Node lastNode = nodes.get(nodes.size() - 1);
if (lastNode != null) {
// 获取从该节点出发的所有叶子位置
List<Integer> positions = getPositions(lastNode);
positions = positions.stream().sorted().collect(Collectors.toList());
positions.forEach(m -> result.add(markPatternInText(m, pattern)));
}
}
return result;
}
// 递归收集所有叶子节点的位置
private List<Integer> getPositions(Node node) {
List<Integer> positions = new ArrayList<>();
if (node.getText().endsWith(WORD_TERMINATION)) {
positions.add(node.getPosition());
}
for (Node child : node.getChildren()) {
positions.addAll(getPositions(child));
}
return positions;
}
// 在原文中标记匹配位置
private String markPatternInText(Integer startPosition, String pattern) {
String matchingTextLHS = fullText.substring(0, startPosition);
String matchingText = fullText.substring(startPosition, startPosition + pattern.length());
String matchingTextRHS = fullText.substring(startPosition + pattern.length());
return matchingTextLHS + "[" + matchingText + "]" + matchingTextRHS;
}
8. 测试验证
SuffixTree suffixTree = new SuffixTree("havanabanana");
搜索模式 a
List<String> matches = suffixTree.searchText("a");
matches.forEach(System.out::println);
输出(6 个匹配):
h[a]vanabanana
hav[a]nabanana
havan[a]banana
havanab[a]nana
havanaban[a]na
havanabanan[a]
搜索模式 nab
List<String> matches = suffixTree.searchText("nab");
matches.forEach(System.out::println);
输出(1 个匹配):
hava[nab]anana
搜索不存在的模式 nag
List<String> matches = suffixTree.searchText("nag");
System.out.println(matches.isEmpty()); // true
✅ 全部符合预期:精确、完整、定位准确。
9. 时间复杂度分析
- ✅ 建树时间复杂度:O(t) —— 虽然代码看起来嵌套,但通过巧妙设计(如 Ukkonen 算法思想),可做到线性时间
- ✅ 搜索时间复杂度:O(p) —— 只需沿着树走一遍模式长度
- ⚠️ 空间复杂度:O(t) —— 后缀树压缩后空间可控
对比暴力搜索 O(p × t),预处理后搜索效率提升巨大,尤其适合“一次建树,多次查询”的场景。
10. 总结
本文从 Trie 出发,引出后缀 Trie,最终聚焦于空间优化的后缀树。我们手撸了一个 Java 版本的实现,涵盖了:
- 节点分裂(Split)的核心技巧
- 构建时的“部分匹配”与搜索时的“全匹配”区分
- 递归遍历与位置收集
后缀树是字符串处理的利器,常见于:
- ✅ 多模式搜索(如病毒库匹配)
- ✅ 最长重复子串
- ✅ 生物信息学中的 DNA 序列分析
虽然实现略复杂,但理解其思想后,面对海量文本的快速检索需求,你会多一个强大的工具。
代码已托管至 GitHub:https://github.com/yourname/suffix-tree-demo